计算机网络应用论文哪里有?本文分析流量数据,通过数据变化趋势分析影响预测准确性的因素,使用深度学习技术,研究流量数据预测模型。把构建出的模型应用到项目中,达到了比较理想的效果。
第 1 章 引言
1.2 国内外研究现状
通过对国内外网络流量预测技术研究现状调研,使得对网络流量预测技术有更深层次的了解,为接下来的研究工作奠定基础以及指明研究方向。
目前机器学习领域的两大研究热点是分类问题和逻辑回归问题,很多现实问题都可以使用分类或者逻辑的方法解决,本文着手解决的问题是网络流量预测部分,而预测通常来讲是属于逻辑回归问题。本节将对逻辑回归概念简短介绍如下:
线性判别分析[1]:回归方法只适合分类类别数只有两类的问题,如果需要解决的问题涉及到两个及以上的类别,那么线性判别分析算法将会是首选的线性分类技术。线性判别分析算法的优点是在对数据降维过程中通过使用先验经验来达到降维的目的,同时对于样本分类依赖的是均值而不是方差;但是该方法的缺点是不适合对非高斯分布样本进行降维,如果要降维最多只能降到类别数(k-1)的维数,如果降维的维度大于 k-1,则不能采用线性判别分析算法,因为此时对样本进行分类依赖的是方差而不是均值的时候,导致降维的效果不好。
决策树:二叉树所有节点包含输入变量 X 和与之对应的分割点数字变量。决策树的优点是模型的学习速度和预测速度都很快,并且可以同时处理数据型和常规型的数据,算法不容易检测到缺失数据,因此可以用来处理特征相关性不高的数据;决策树算法的缺点是对字段与字段之间的连贯难以捕捉到,需要预处理对时间有先后依赖关系的数据。
朴素贝叶斯[2]:一种预测准确度很精确的算法。由于贝叶斯算法核心有着坚实的数学理论知识做基础,并且有着相对稳定的分类效率,所以对小规模的数据预测准确度比较高,能用来处理多分类任和增量式训练,贝叶斯算法的缺点是需要事先计算先验概率,同时由于对输入数据的表达形式很敏感,因此在进行分类决策的时候错误率比较高。

计算机网络应用论文范文
.......................
第 3 章 基于优化神经网络的预测模型构建
3.1 经典神经网络优缺点分析
BP 神经网络[29]对时间序列[30]的记忆能力表现不佳,模型的损失函数收敛速度慢等缺点,适应不了现如今预测技术快速发展的潮流;因此循环神经网络应用而生。循环神经网络[31]顾名思义该网络结构模型包含循环的部分,循环结构可以重复利用前面的信息得到预测值,并能将其长时间保存在网络模型中。随着科技的进步,循环神经网络模型已经不限于识别手写字体;现如今已被推广到时间序列分析和自然语言处理等领域,并在相关领域均取得了良好的成绩。
网络信息的流通方向是自上向下的,数据由最高层逐渐传递至最底层,在输入层和输出层中节点互相链接。网络结构图如图 3.1 所示:
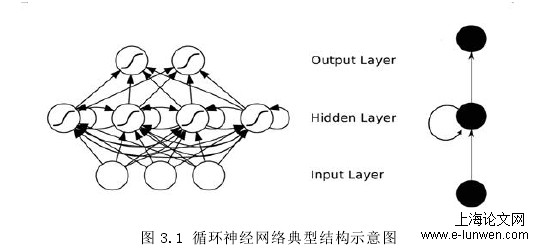
图 3.1 循环神经网络典型结构示意图
.........................
第 4 章 网络流量预测应用和结果分析
4.1 实验环境介绍
如今互联网环境日趋复杂,为了实现资源共享的目标。网络中用于传输的联网设备数量日益激长,从而导致网络故障层出不穷,给网络管理工作人员带来了繁重的维护任务和管理成本。本文通过对于网络流量进行预测, 从而能够提前到了解网络流量变化情况,将会大大减少网络管理的成本和维护工作的劳动强度。
Keras 是广泛使用的实现机器学习以及其它涉及大量数学运算的算法库之一。与 Keras 类似的还有 Caffe、Theano、Tensorflow、MXNet 等算法库。其中 Keras是由谷歌公司的工程师开发的用于深度学习任务的一个平台,由于这个平台是开源的,全球开发者和科研工作人员可以结合工作实际,给这个开源平台添加各种自己想要的功能,方便自己的科研开发;因此受到广大科研工作者的喜爱。
.........................
4.2 实验数据集介绍本文研究用到的数据集是湖北省某市 2 万多个网元,168 天的网络流量数据,数据集中存在随机位置数据字段缺失或者数值为零的情况,以及因为节假日等突发因素导致网元节点流量偏大的情况,而数据缺失、数值为 0、数据值异常并不能正确反映数据集内部规律,从而导致模型的预测准确率受到影响,因此需要对数据集中的数据进行相关预处理操作。
为了使网络流量预测模型预测更加准确,通常需要对收集的网络流量的数据进行相关处理。在这一节的讲解中,将系统介绍数据预处理技术和网络流量预测问题中的难点。
本文将数值不准确或者缺失的数据称为异常数据。网络流量的历史数据一般而言是可以反映其数据间内在的规律性,而异常数据的存在将对预测模型的训练和对未来流量数据的预测都会导致误差比较大的情况。
从网络流量预测角度来看,如果数据有异常值情况将不能正常反应数据之间的规律,将会导致模型预测误差较大;异常数据不论是作为训练的输入数据参与模型的训练还是作为评估模型预测性能的验证数据,都会导致预测的不准确。
各种预测算法本身的健壮情况与否虽然能不同程度的消除异常数据对预测的影响,但是要想预测误差最小和模型曲线拟合最好,就需要清除掉问题数据。
...........................
第 5 章 总结与展望
本文基于目前研究很广、实用的神经网络模型,使用注意力机制构建出了网络流量预测模型,通过实验验证了本文构建出来的网络模型在预测准确性上较之前有所提升。本文的主要研究内容总结如下:
(1)本文在查阅了大量国内外研究资料,对预测技术的研究方法有所了解后,结合项目实际,选用 Seq2Seq 模型作为本文研究技术路线参考,根据 Seq2Seq 模型本身的特性、结合网络模型本身存在的缺陷,通过大量的查阅资料,找到了改进模型本身存在的缺陷的方式,并将解决方法用到了 Seq2Seq 模型中来。
(2)本文为了加快模型的预测速度,引入了智能优化算法。其中主要介绍了进化算法的相关概念、蜻蜓优化算法、蚱蜢优化算法、粒子群优化算法,并通过对比实验证明了蜻蜓优化算法寻优能力优于其它两种优化算法。
(3)本文详细介绍了预测模型的构建,使用蜻蜓优化算法来优化神经网络模型的学习率加快模型的训练速度。在实验过程中,使用湖北省某城市的流量数据,通过对比预测准确率,实验证明经过优化后的神经网络模型在预测准确率较之前有所提升,运行时间也更少。
Seq2Seq 模型同其它深度学习网络模型一样具有非常多的超参数,关于这些超参数的选取具有很强的随机性,因此网络模型在训练的过程中具有不可知性和不可控性,所以很难保证网络模型按照我们期望的方式去预测。
参考文献(略)

