本文是计算机论文,基于此本文提出了以下两种解决方法:(1)针对第一个问题,设计出了基于DPMM和IsoalationForest的信贷风控冷启动方法。该方法分为四个步骤,第一步是基于DPMM计算无标记样本的违约相似度,该步骤中首先对有标记数据中的正常样本和违约样本分别进行聚类,为了避免人工指定聚类个数带来的影响,故采用能够自动确定聚类数目的DPMM聚类算法,然后根据聚类中心计算出无标记样本的违约相似度;第二步考虑到该场景中存在大量无标记样本,其无标记样本中违约用户占比较少且违约用户种类较多,故采用无监督异常检测算法IForest,使用该算法计算出无标记样本的违约异常度;第三步对违约相似度和违约异常度进行综合,筛选出可靠正常样本和可靠违约样本,并设置权重;第四步使用监督模型对筛选出的样本进行训练。对设计的方法进行仿真实验,验证了设计方法的有效性。
.......
第一章绪论
互联网金融行业竞争也进入了白热化阶段,各个机构都推出了多种类型的个人信用贷款业务,来扩大其业务的覆盖面,让其服务被更多的用户采用。按照传统商业银行办理信贷业务的风控方法,用户在申请贷款后,银行的信贷审批员会对申请人的历史资料进行审批,例如申请人的受教育水平、收入情况、房产情况等信息,但这种方法的效率不高,已经不能满互联网金融机构的海量高纬度数据的业务需求,同时人为主观因素影响太大,内部人员容易出现作弊的情况。基于上述原因,互联网金融机构采用机器学习算法来构建信贷风控模型,这样做,不仅在扩大业务规模的同时,也能减少因用户违约带来的坏账成本。通过对大数据技术的应用,互联网金融机构能够收集到用户的网购记录、社交记录等数据,从而有效分析出用户信用风险方面的特征,建立信贷风控模型对用户进行违约概率预测,进而为是否发放贷款提供决策依据。从用户的角度来看,这种信贷风控模型的开发与实施,也会让用户注意维护自己的信用记录。从政府的角度看,当各个领域的数据能够汇总到一起时,这也能够促进我国征信体系进一步发展。总的来说,互联网金融机构使用基于机器学习算法的信贷风控模型,对促进业务发展、改善客户体验、推动我国征信体系建设、金融产品创新等方面,都有十分重要的意义。
........
第二章基础知识和相关理论
2.1信贷风控体系介绍
反欺诈的主要目的是将带有欺诈意图的客户拒绝掉,包括两部分,分别是反欺诈规则和反欺诈引擎。反欺诈模型很少使用传统监督模型,是因为欺诈标签不容易得到,而且欺诈用户往往将自己伪装成信用良好的用户,进行借款后失联或者拒不还款,进而欺诈特征不明显。因此,反欺诈模型常使用无监督算法、社交网络算法等,还有反欺诈规则也被主要使用。近几年随着深度学习的流行,带来了意想不到的效果,其基本思想是,简单评分卡可解释性强,其缺点就是容易被逆向破解,深度学习的黑箱操作虽然可解释性差,但安全性有所提升,反向破解成本极高。催收是风控的最终手段。这个环节生成的数据对模型很有帮助,比如催收记录的文字描述、欺诈标签等。产生坏账的客户会被列入黑名单,但是只要能把催收回来的,理论上都不是坏账,但是多数机构为了保险起见,某些逾期超过一定时间的客户,即使被催收回来,也会被列入黑名单。该部分常使用有监督或者无监督模型,也有以社交网络算法为基础的失联模型等。
2.2信贷风控冷启动方法
传统方法实现信贷风控冷启动需要建模人员对业务有深入理解且经验丰富。传统方法的主要思想是建模人员根据其他相似业务场景中的经验积累,制定相应的业务规则来满足风控系统的基本需求,然后经过业务量的积累,满足了建模的最低样本需求,第一个版本的模型才能被正式开发。传统方法面临着两个问题,一个是建模人员的认为主观因素影响太大,二是获得坏账样本的代价太高。因此需要新的方法实现冷启动。信贷风控冷启动方法分为两种,主要的根据是有无样本数据。第一种,在新的信贷产品投放之前,没有任何样本,即无样本可依的信贷风控冷启动方法;第二种,是有一定量的样本积累,但大都是少量标记样本或者大量无标记样本,即无标记样本下的信贷风控冷启动方法。
第三章基于DPMM和IForest的信贷风控冷启动方法.........16
3.1问题分析...........16
3.2方法设计...........16
3.3仿真实验...........21
第四章基于Bagging的XGBoost-LR信贷风控模型融合方法.............27
4.1问题分析...........27
4.2方法设计...........28
4.3仿真实验...........32
第五章信贷风控系统....39
5.1系统框架...........39
5.2数据分析模块...40
5.2.1选择目标变量.......40
5.3数据清洗模块...45
............
第五章信贷风控系统
5.1系统框架
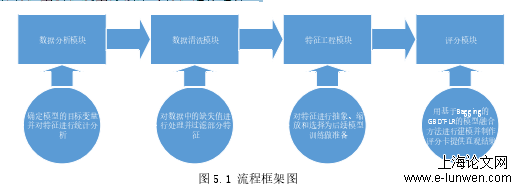
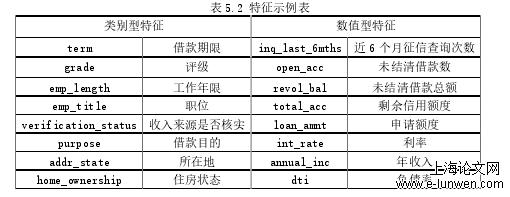
该系统分为四个模块,分别是数据分析模块、数据清洗模块、特征工程模块和评分模块,具体流程图如下图5.1所示。在数据分析模块中首先对模型的目标变量进行选择,定义坏账,然后对原始数据中的特征进行概括性地统计分析,从而对数据类型有一个大致地认识;在数据清洗模块中,删除存在较多缺失值的特征,并对缺失值进行填充,同时剔除不相关的特征;在特征工程模块中,对类别型特征进行独热编码转换,对数值型特征进行标准化处理,并使用多种特征重要性度量方法来对特征进行选择。本章数据从LendingClub官方网站获得,LendingClub在2006年10月成立,是目前全球最大的一家P2P公司。本章选取了2005年到2018年第四季度的借贷记录,作为信贷风控系统开发过程中所使用的数据。原始数据共有2621341个,151个变量。由此可以得出结论,信用等级与坏账率成反比,信用等级越高,坏账率月底越低。前一个模块对数据进行了清洗,主要剔除了以下特征:借贷成交后产生的特征,因为需要对借贷为坏账的可能性进行预测,需要借贷生成前的特征进行建模;含有大量缺失值的特征,这些特征没有重要信息。
5.2数据分析模块
借款期限的取值分为两种,一种是36个月,另一种是60个月。根据原始数据对不同借款期限的总借款数和坏账数进行统计,得出坏账率,如表5.5所示。可以发现,借款期限为36个月的客户占比达到76.03%,而借款期限为69个月的客户占比为23.97%,即申请借款期限为36个月的客户比申请借款期限为60个月的多出很多。借款期限为36个月的客户中,坏账数量为16172个,坏账率为15.83%,借款期限为60个月的客户中,坏账数量10683,坏账率为32.99%。综上所述,借款期限为60个月的客户的坏账率超过了总体的坏账率,违约风险显著升高,所以需要在贷款发放前进行更多的背景调查,降低风险。客户的信用评级一共分为7种,从高到低分别是A、B、C、D、E、F、G,为了体现信用等级与坏账率的关系,选择grade特征根据等级进行分组,计算每个等级分组中的正常还款人数和坏账人数,进行统计分析。构建如下图5.3,其中X轴是7个信用等级,左侧Y轴是人数统计,右侧Y轴是违约比率。从图中可以发现,B等级中的借款人数最多,为39210人。分析得出,A级虽然是最好的信用等级,但是借款人很难达到,B和C两个等级相对来说信用等级次优,客户能够较容易达到。从坏账率的角度看,可以发现坏账率随着信用等级的降低出现了整体递增的趋势,在等级G中,坏账率达到最高,超过50%。
.........
第六章总结与展望
数据过滤模块主要从主观上删除了部分特征,本节对坏账可能性与特征的相关性和特征间的多重共线性进行量化,进而根据量化指标筛选出与坏账可能性高度相关的特征,以及解决特征之间存在共线性导致的信息冗余问题。特征选择直观上来看,对数据进行了降维,从而优化了模型的计算速度,也避免了不相关特征的影响,增强模型的泛化能力。本节使用三种方法对特征进行选择,分别是对递归消除法、皮尔森相关系数法、基于随机森林模型的特征选择法。随着互联网的快速普及,人们的日常生活方式也发生了巨大变化,传统的上街购物、饭店点餐、路边打车、学校上课等,都转变为网上购物、网上点餐、网上打车、网上学习等等,互联网让人们的生活变得非常便利,提升了人们的消费需求,使人们的消费观念逐渐升级。消费端的旺盛也让互联网金融中的信贷业务火爆,各种各样的信贷产品开始推出,这也给信贷风控带来了更多的挑战。(2)针对第二个问题,设计出了基于Bagging的XGBoost-LR信贷风控模型融合方法。考虑到LR模型对非线性特征不能较好拟合,故采用XGBoost进行特征转换,利用其在叶子结点的输出作为LR的输入,为了进一步提高模型的预测效果,引入Bagging机制,对XGBoost的行采样参数和列采样参数进行随机扰动,获得多个XGBoost-LR模型,对模型的输出结果进行融合处理。对设计的方法进行仿真实验,验证了设计方法的有效性,但是Bagging机制对模型的提升效果较小。
参考文献(略)
参考文献(略)

