Spark 在提交应用程序到 Worker 节点时,数据会通过 CPU-GPU 异构并行计算系统进行处理,在这过程中,调用内核函数 Kernel 后,CPU 会分配数据块到 GPU 中进行并行计算,而数据块有大有小,因其在传输过程中速度不一样,最后到达 GPU 的顺序也不一样。在已建立的多服务窗混合制排队模型 M/M/n/m 中未考虑数据到达的顺序,对多种应用的数据处理不做区分地遵循先来先服务原则,忽略了实际应用固有的优先级特性。而在实际应用中数据处理是有优先级的,比如生活中的一些场景:信件有普通件和挂号件,快递有一般快递和顺丰快递,医院看病有普通门诊和急诊,普通车让道救护车、消防车等都是优先服务的例子。由此可见,在有优先权排队模型中,顾客是分等级的。因此本文在已建立的 M/M/n/m 排队模型中,加入顾客优先级(数据块大小优先级)来对模型做进一步优化。
.........
第一章绪论
国内外对 Spark 系统性能优化的研究主要集中在两大方向:一是 Spark 内存计算模型的扩展和完善,二是 Spark 内存计算模型的性能优化。对于前者,这些研究主要包括提出了简单而高效的并行流水线编程模型[12],提出了分析关系型大数据的基本架构[13],提出了图计算的并行化设计方案[14],提出了集群资源的细粒度共享策略[15],提出了差分数据流与响应及时反馈并行的运算模式[16],提出了计算机内存运算框架分布式调度的重要云计算方法[17],实现了高性能的 SQL 查询系统[18],基于 Bit Torrent 实现了内存计算框架的广播通信技术[19],这些重要的研究思路极大地提升了系统的可扩展性。对于后者,其研究成果集中体现在充分利用数据访问的时间、空间局限性上,设计了一种策略,可以提高本地数据访问[20],通过分析并行的任务度会对缓存的有效性产生影响,设计出一种协调缓存算法可以符合内存计算需求[21],针对一些相对较慢的任务节点问题,研究者提出了多种不同的优化方案以供选择,为保障连续执行作业提供了更多的参考[22],通过两种策略(确定性执行、批处理事务),使系统具有良好的可靠性和扩展性[23]。
.........
第二章相关理论基础与技术探讨
2.1 Spark 分布式计算框架概述
Spark 是一个系统、全面的计算框架,它适用于对各种复杂的不同性质数据源进行批量处理。Spark 基于内存运算在运行速度上优于 Hadoop 百倍,减少了 I/O 读取操作,使得磁盘运行速度也跟着提升了 10 倍。相比 Hadoop 而言,Spark 有着明显的云计算优势: (1)增加任务并行度。Spark 在应用中,整个执行流程抽象为通用的有向无环图DAG,Spark 根据 RDD 之间不同的依赖关系切分形成不同的阶段(Stage),允许多个Stage 既可以串行执行,又可以并行执行,而无须将 Stage 的中间结果输出到 HDFS 中,从而优化了计算路径,大大减少了 I/O 读取操作。这一点非常适合于具有多个阶段的作业过程,比如需要多轮迭代的机器学习领域。而 Map-Reduce 会将中间结果输出到磁盘上,进行存储和容错,在数据存储过程中容易出错。 (2)没有线程切换开销。Spark 在通信方面可以忽略进程或线程启动切换开销,通过类库 AKKA 来启动任务,实现线程池复用线程,因此延迟低,运行速度快。而Map-Reduce 具有高延迟性,适合应用于长时间的离线批量作业。
2.2 Spark+GPU 性能建模相关研究工作
目前针对 Spark 的性能建模工作,仅有文献[34]中提出了 Spark Streaming 流式计算系统性能建模。而基于 GPU 的 Spark 计算框架性能建模工作尚属空白。 国内外学术界对于 GPU 通用计算的研究工作基本上集中在对应用程序的开发建设方面,而对 GPU 性能剖析与分析工具的研究相对较少。市面上能够找到的商业程序分析工具也比较少,较为著名的比如 ATI Stream Profiler、NVIDIA Parallel Nsight 等,这些都建立在 GPU 的计算功能模拟器之上的重要程序分析工具,而这些产品均只对程序的运行时间进行统计,却不关注性能的分析。因此,对于 GPU 程序执行过程的建模分析,尚属空白,既没有对 GPU 程序执行过程的精度分析进行充分的研究和探讨,也缺少对GPU 调优相关问题的探索,这为基于 GPU 理论与研究基础去探索 Spark 的建模分析工作提供了较少的线索和参考。本文所探讨和研究的课题——Spark+GPU 性能建模分析,是一个全新的探索性课题,一方面要基于 GPU 广泛被使用的程序分析工具的理论基础和实践经验来探索 Spark 中的 GPU 应用,另一方面还要研究如何使用 GPU 来加速 Spark运行,以一种全新的计算模式来分析和讨论 GPU 与 Spark 两大强势工具“联姻”的成果。因此,目前对基于 GPU 的 Spark 的性能建模研究以及相关方法的讨论也基本上是处于一个初始的研究阶段。
......
第三章数学建模理论基础——排队论 .............................................................................. 21
3.1 排队论理论基础 ........................................................................................................... 21 3.2
3.2基本排队模型............................................................................................................... 23
3.3排队系统常用概率分布............................................................................................... 24
第四章基于排队论的 Spark+GPU 性能模型研究 .......................................................... 27
4.1 Spark+GPU 工作原理 ................................................................................................... 27
4.2 排队模型选取 ............................................................................................................. 31
4.3 排队模型 M/M/n/m 计算方法................................................................................... 33
第五章非强占有限优先权模型优化与验证...................................................................... 39
5.1模型优化........................... 39
5.2模型验证 ......................... 41
.......
第四章基于排队论的 Spark+GPU 性能模型研究
4.1Spark+GPU 工作原理
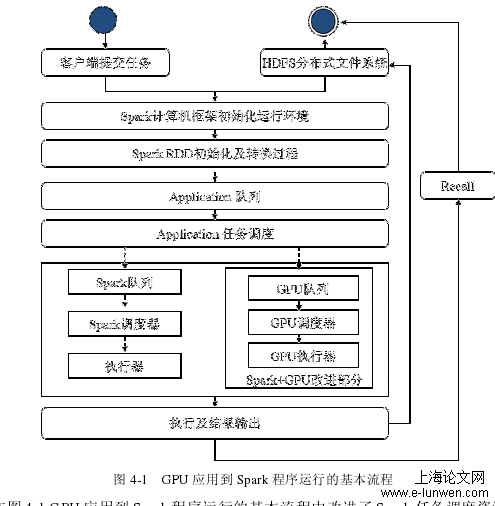
首先,启动 HDFS 服务进程,当一个应用程序提交至 Spark 集群,Spark 会创建运行环境即初始化 Spark Context 对象,SparkContext 是 Spark 应用的入口并负责和整个集群的交互。Spark 将按照提交命令中所含信息更新集群配置。之后 Spark Context 将从文件系统中提取数据,并创建RDD。根据任务类型的不同RDD 将执行进一步的转换操作。Spark Context会根据 RDD之间的依赖关系构建 DAG ( Directed Acyclic Graph有向无环图),每个 DAG 再触发 Spark 执行一个 Job,并将 Job 发送给 DAG Scheduler,DAG Scheduler是 Spark 作业调度的核心技术。DAG Scheduler 根据 RDD 的分区把 DAG拆分成很多的Tasks,每组的 Tasks 形成一个 Stage,一旦遇到 Shuffle 就会产生新的Stage ,然后以一个个 Taskset 为单位提交给底层调度器 Task Scheduler。Task 需要监视因 Shuffle 输出导致的失败,如果某个 Stage 运行失败,Task Scheduler会通知 DAG Scheduler 将运行失败的任务重新注册并执行(即任务的 Recall 过程)。
4.2排队模型选取
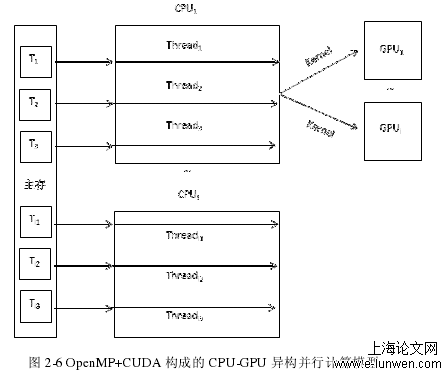
本节根据排队论理论基础和基于 GPU 的 Spark 计算模型架构,设计和选取相匹配的排队模型。 Spark 由主节点(Master)和工作机(Workers)组成。每个 Worker 分别实现了 CPU和 GPU 的异构并行计算[49]。当 Spark 把应用程序提交到集群,通过 CPU 调控,将数据进行分片,然后把分片的数据分发到 Workers,Workers 收到对 RDD 的操作,将分片的数据进行本地计算(图 4-4 中灰色部分)。计过程中,由 CPU 控制任务调度以及少量计算任务,大量的并行计算交给 GPU 执行。其中显存与内存需要做频繁的数据交换,过程如下:当程序执行到内核函数 Kernel 时,CPU 将会调用 GPU,这个时候数据就会从内存转移到显存。数据到显存后,GPU 对每个数据分配相应的线程,以线程为单位进行相应的数据计算,最后把计算结果保存到显存,接着由显存传送到内存,等待 CPU 的调用或者做接下来的串行程序操作。
......
参考文献
[1]卞琛.内存计算框架性能优化关键技术研究[D].新疆大学,2017.
[2]黄天琪.GPU 通用计算的发展及其应用领域综述[J].计算机光盘软件与应用,2011 (8): 34~36.
[3]周情涛,何军,胡昭华.基于 GPU 的 Spark 大数据技术在实验室的开发应用[J].实验室研究与探索,2017,36(01):112-116+131.
[3]周情涛,何军,胡昭华.基于 GPU 的 Spark 大数据技术在实验室的开发应用[J].实验室研究与探索,2017,36(01):112-116+131.
[4][Segal O, Colangelo P,Nasiri N, et al. Spark CL: A unified programming framework for accelerators on heterogeneous clusters [J].ar Xiv preprint ar Xiv :1505.01120,2015. #p#分页标题#e#
[5]林闯.随机 Petri 网和系统性能评价[M].清华大学出版社, 2005.
[6]Lin X.Wang P.Wu B.Log analysis in cloud computing environment with hadoop and spark[C].www.zhonghualw.comProc of the 5th IEEE International Conference on Broadband Network& Multimedia Technology (IC-BNMT). New York : NY,IEEE,2013 :273-276 .
[7]DongX.XieY.MuralimanoharN .etal.Hybrid checkpointingusingemerging nonvolatilememoriesforfutureexascalesystem[J] .ACMTransonArchitectureand Code Optimization (TACO), 2011, 8(2): 1-29.
[8]ZahariaM,DasT,Haoyuan Li, et al. Discretized Streams: Fault-tolerant streaming computation at scale [C] //Proc of the 24th ACMSymposium on Operating Systems Principles. Farmington, PA: ACM, 2013: 423-438.
[9]Armbrust M, Xin R S, Lian C, et al. Spark SQL: Relational dataprocessing inspark[C]//Procofthe2015ACMSIGMODInternational Conferenceon Management of Data. Victoria, Australia: ACM, 2015: 1-12.
[10] ApacheSpark.Sparkmachinelearninglibrary(MLlib)[EB/OL].2012 [2015-03-18].https://spark.incubator.apache. org/docs/latest/mllib-guide.html.
..........

