
第一章 绪论
1.1 研究背景和意义
当前人工智能的迅猛发展得益于硬件计算能力的增强、数据的爆发式增长和越来越多的科研投入。机器学习和深度学习领域有很多有效而稳健的算法模型被提出,推动着社会的发展。计算机视觉作为人工智能的一个重要研究领域,其发展影响到了当下人们生活的各个方面。
从图像或图像的序列中识别对象是计算机视觉中的重要任务。计算机视觉的基本挑战之一就是从二维图像中推断关于三维世界的信息。如果我们扩展到三维的空间,对象识别所遇到的一些视觉问题就会得到缓解。与二维数据相比,三维数据可以体现物体的完整结构,并且具有固定的相对深度,不受光照和视角影响。由于之前很少有能够访问的三维对象模型,对象的识别往往需要通过基于来自各种视角的二维图像来识别和推理三维空间中的对象。
近几年来随着三维成像传感器和三维重建技术的发展,人们可以从生活中便捷地捕获大量的三维物体结构信息。同时,网络的发达也促进了三维数据的传播与分享,越来越多的三维模型数据集可供研究者们分析。逐渐增长的三维数据推动了三维物体研究以及三维数据的应用。例如扫地机器人需要对所处的三维场景进行建模和理解,手机的人脸识别需要处理图像及深度信息,增强现实和虚拟现实需要进行三维物体的生成和渲染等等。
三维物体识别与二维图像识别有着一定的区别。区别的主要原因在于二维数据与三维数据的数据形式不同。传统的二维图像数据主要以矩阵形式存储和处理,其数据结构排列规范,易于读取与处理,并且包含了色彩信息。而大部分可供研究的三维数据为非结构化数据,且不含色彩信息。二维图像得益于其结构化,可以被归一化为同等的输入大小,表现出了对处理模型的友好性,尤其是神经网络模型。然而,三维数据具有多个不同的描述形式。由于三维物体数据获取来源有差别,三维物体数据可被分类为体素、点云、网格三种。三种不同结构的数据对应了不同的处理模型。并且,在同一数据结构下的三维数据难以合理的归一化。这使得在传统特征提取和深度学习网络框架上,三维物体识别与图像识别都有所不同,尤其是神经网络架构。随着处理二维图像的神经网络逐渐成熟,深度学习在三维数据上才开始发展。
.......................
1.2 国内外研究现状
早期的三维形状识别,主要基于人工设计的三维数据描述特征和机器学习特征分类器。由于三维数据形式的特殊性,以三维网格形式表现的三维形状可以被看作一个无向图结构。所以,在计算机视觉和图形学的研究领域中都有许多的三维形状描述算子被提出来。[7]给出了直接计算三维网格体积,矩长和傅里叶变换的显式方法。Kazhdan 等人提出了球面谐波表示[8],一种在不同能量方面具有旋转不变性的球面函数。Rustamov 使用 Laplace-Beltrami 微分算子[9]的特征值和特征函数,即 GPS 嵌入,提出了称为 G2 分布的具有形变不变性的形状描述子。Johnson 和 Hebert 通过使用旋转图像表示匹配点来匹配表面,提出了用于匹配表面为网格数据的数据级形状描述符 spin image[10]。Belongie提出了 shape context[11],一个点上的形状上下文特征会捕获其他点的相对分布,并从累积的局部描述中总结全局特征。将二维图像特征 HoG 衍生到三维网格数据上,Zaharescu提出了 MeshHoG 和 MeshDoG[12],以简洁的方式捕获局部几何或光度特性。在[13]中,Reuter 等人选择有限元算子进行特征函数计算,并从拉普拉斯频域第一部分特征函数的节点域中分析完成分割任务。在同一年,Sun 等人基于形状上的热扩散过程提出了一种新颖的点标记,被称作热核标记[8]。之后,Bronstein 等人在此之上进行了改进,提出了具有尺度不变性的热核描述符[9].
随着硬件技术和深度学习的发展,三维物体数据库扩大,许多处理三维数据的神经网络框架被提出。神经网络框架针对输入被大致分为三个流派:基于体素的方法[14-19,21,22],基于点云的方法[23-27]和多视图的方法[28,31-36]。目前大多识别三维网格数据的网络是基于多视图的。并且大部分的实验表明,基于多视图的方法效果表现比基于体素的方法好。下文将逐一介绍这三个流派的部分研究状况。
........................
第二章 相关理论与技术
第二章 相关理论与技术
2.1 三维物体的视图渲染
三维物体的数据形式主要有三种:体素,点云和网格。本文所处理的为网格形式。网格形式的三维物体主要由三角面片构成。这些三角面片无间隙地覆盖于物体的表面,构成一个中空的三维模型。
常见的三维网格模型数据库中模型的描述格式使用的是 OFF 文件格式。文件内容分为两个部分,第一部分是所有顶点的三维坐标,第二部分是组成每个面片的三个顶点的索引序号。所以三维网格物体的原始数据不利于被学习模型直接处理分析。一种解决思路便是将物体在三维空间中的表现形式投影到二维,通过分析二维投影对三维物体进行推断。
为了生成三维网格物体的渲染视图,本论文使用的是 Phong 提出的反射模型[40]。网格多边形在透视投影下渲染,像素的灰度通过插值多边形顶点的反射强度来确定。投影的二维图像为灰度图像,可以反应出物体的边缘信息。
三维物体的数据形式主要有三种:体素,点云和网格。本文所处理的为网格形式。网格形式的三维物体主要由三角面片构成。这些三角面片无间隙地覆盖于物体的表面,构成一个中空的三维模型。
常见的三维网格模型数据库中模型的描述格式使用的是 OFF 文件格式。文件内容分为两个部分,第一部分是所有顶点的三维坐标,第二部分是组成每个面片的三个顶点的索引序号。所以三维网格物体的原始数据不利于被学习模型直接处理分析。一种解决思路便是将物体在三维空间中的表现形式投影到二维,通过分析二维投影对三维物体进行推断。
为了生成三维网格物体的渲染视图,本论文使用的是 Phong 提出的反射模型[40]。网格多边形在透视投影下渲染,像素的灰度通过插值多边形顶点的反射强度来确定。投影的二维图像为灰度图像,可以反应出物体的边缘信息。
为了从多个视角采集投影的渲染图,需要设置多个虚拟摄像机的视角。一般视角的设置分为两种。如图 2-2[33]所示。第一种是假设三维物体已经在竖直方向上对齐,则将虚拟摄像机从地面抬高 30 度,指向物体的中心,在水平面上每隔 30 度在物体周围放置12 个虚拟摄像机来创建 12 个渲染图像。第二种是假设三维物体没有对齐,可能是任何的朝向,则这样需要通过将 20 个虚拟摄像机放置在包围该物体的十二面体的 20 个顶点处来生成渲染图,以此来保证对物体所有视角信息的囊括。同时,在 MVCNN[28]论文中,考虑到物体对于视角的旋转,摄像机在沿着穿过物体中心的连线轴分别旋转了 0 度,90度,180 度和 270 度,共产生 80 个视图。
........................
........................
2.2 特征提取网络
近几年来深度学习在计算机视觉研究领域迅速发展。相比于传统的在三维特征描述上建立特征分类器,多视图的方法可以借力于相对成熟的卷积神经网络作为视图的特征提取器和分类器。使用在大型图像数据库中训练的卷积神经网络,在识别三维模型投影的过程中对网络参数进行微调。这一步也可以节省对特征提取网络的训练消耗,同时缓解训练时反向传播算法的梯度消失问题。
近几年来深度学习在计算机视觉研究领域迅速发展。相比于传统的在三维特征描述上建立特征分类器,多视图的方法可以借力于相对成熟的卷积神经网络作为视图的特征提取器和分类器。使用在大型图像数据库中训练的卷积神经网络,在识别三维模型投影的过程中对网络参数进行微调。这一步也可以节省对特征提取网络的训练消耗,同时缓解训练时反向传播算法的梯度消失问题。
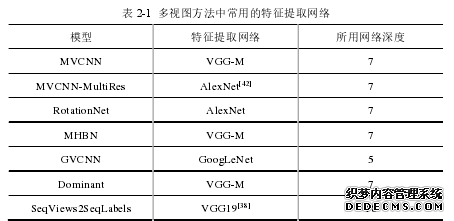
由于三维模型的多视图是无噪声和无背景的,所以在卷积神经网络选择上,大部分的多视图框架都选择了较为简单浅层的卷积神经网络。下表列出了部分与本文相比较的方法所采用的特征提取网络结构。
完整 VGG-M 网络具有 5 层卷积层和 3 层全连接层,最后一层全连接层为输出层。而作为特征提取网络,MVCNN 只利用了 VGG-M 输出层之前的 7 层,所以在表中网络深度为 7。同时,GVCNN 所使用特征提取网络为 GoogLeNet[37]的前 5 层卷积层,所以表中的网络深度为 5。从表中可以看出,特征提取网络并没有固定要求的框架。不过除了 SeqView2SeqLabels 和 GVCNN,其余的模型都主要利用 5 层卷积层后接 2 层全连接层作为特征提取模块。
...........................
3.1 方法概述 ........................................... 17
3.2 视角选择策略 ............................................ 18
3.3 视图特征映射模块 .................................. 23
第四章 实验与结果分析 .................................... 30
4.1 实验数据集 .................................... 30
4.2 实验细节 ............................... 31
4.3 三维物体的识别任务 .................................. 34
第四章 实验与结果分析
4.1 实验数据集
三维物体识别与检索领域常用的标准数据集是 Wu 等人创建的 ModelNet 数据集。ModelNet 中的三维物体来源于 CAD 建模,是三维网格数据格式。三维网格数据形式用覆盖于物体表面的三角形面片构成。物体为中空状态,且只具有结构信息,没有色彩和纹理。
三维物体的类型涵盖了生活中常见的物体。其中 ModelNet40 包含了所有的三维模型共 12311 个,40 个类。其中训练集 9843 个模型,测试集 2468 个模型。种类包括椅子,床,沙发,衣柜,浴缸,车,水杯,飞机,乐器,植物,花盆等常见类别。类别涵盖的范围广泛,且不同的类别模型的数量不同,训练样本存在一定的不平衡现象。同时,Wu 等人还建立了 ModelNet 的一个子类,称作 ModelNet10。这个子类包含了三维模型共 4899 个,10 个类。其中训练集有 3991 个模型,测试集有 908 个模型。ModelNet10作为 ModelNet40 的子集,收入的类别主要为家具类型,且样本数量较为平衡。但是家具类三维物体中以长方体形态的模型居多,不同类别之间相似性较强,同样具有一定的挑战。 #p#分页标题#e#
三维物体识别与检索领域常用的标准数据集是 Wu 等人创建的 ModelNet 数据集。ModelNet 中的三维物体来源于 CAD 建模,是三维网格数据格式。三维网格数据形式用覆盖于物体表面的三角形面片构成。物体为中空状态,且只具有结构信息,没有色彩和纹理。
三维物体的类型涵盖了生活中常见的物体。其中 ModelNet40 包含了所有的三维模型共 12311 个,40 个类。其中训练集 9843 个模型,测试集 2468 个模型。种类包括椅子,床,沙发,衣柜,浴缸,车,水杯,飞机,乐器,植物,花盆等常见类别。类别涵盖的范围广泛,且不同的类别模型的数量不同,训练样本存在一定的不平衡现象。同时,Wu 等人还建立了 ModelNet 的一个子类,称作 ModelNet10。这个子类包含了三维模型共 4899 个,10 个类。其中训练集有 3991 个模型,测试集有 908 个模型。ModelNet10作为 ModelNet40 的子集,收入的类别主要为家具类型,且样本数量较为平衡。但是家具类三维物体中以长方体形态的模型居多,不同类别之间相似性较强,同样具有一定的挑战。 #p#分页标题#e#
........................
总结与展望
本文首先简要介绍了三维数据处理的研究背景以及研究意义。分析了三维物体识别任务的重要性和挑战性。三维数据在人们的日常生活中越来越容易被获取,数据处理的需求也逐渐增多。三维物体识别作为三维数据处理的基本任务,是数据理解和分析的基础。三维数据的不规范给模型的设计带来了一定的挑战。在国内外的相关研究中,基于对三维物体多个角度视图推断三维物体形状的方法成为当前主流方法之一。本文针对多视图方法的视角选择模块、特征提取模块和特征融合模块提出了改进的模型和算法。视角选择模块中,通过递归地划分视角分布的范围,产生具有空间相关性的视角点。特征提取模块中,设计相邻视图特征与局部融合特征间的残差映射,并设计损失函数对映射后特征的相似性做约束。特征融合模块中本文利用卷积操作对特征进行了加权融合。
总结与展望
本文首先简要介绍了三维数据处理的研究背景以及研究意义。分析了三维物体识别任务的重要性和挑战性。三维数据在人们的日常生活中越来越容易被获取,数据处理的需求也逐渐增多。三维物体识别作为三维数据处理的基本任务,是数据理解和分析的基础。三维数据的不规范给模型的设计带来了一定的挑战。在国内外的相关研究中,基于对三维物体多个角度视图推断三维物体形状的方法成为当前主流方法之一。本文针对多视图方法的视角选择模块、特征提取模块和特征融合模块提出了改进的模型和算法。视角选择模块中,通过递归地划分视角分布的范围,产生具有空间相关性的视角点。特征提取模块中,设计相邻视图特征与局部融合特征间的残差映射,并设计损失函数对映射后特征的相似性做约束。特征融合模块中本文利用卷积操作对特征进行了加权融合。
本文的主要贡献为:一、设计一种视角选择算法,通过该算法可以递归的产生不同密集程度的视角。视角点分布在多个高度上,且相邻的视角间具有图结构,在视图内容上相互补充。二,设计了一种视图特征映射模块,通过对学习相邻视图特征间的映射,提高特征提取网络对物体空间结构信息的总结能力。三、基于设计的视角选择算法,在特征融合时利用卷积学习相邻特征间的权重。通过在多个特征图的最大响应值上做卷积操作,挖掘相邻视图间的信息.
参考文献(略)
参考文献(略)

