
第一章 绪论
1.1 课题背景研究
互联网自 1969 年在美国诞生以来,已经发展了整整 50 年。互联网早期主要用于学术研究和军事领域,自 20 世纪 90 年代投入商业使用以来,它得到了迅速发展,现已经扩展到世界五大洲的 240 多个国家和地区。互联网信息传输以高速传播、价格低成本、覆盖范围广的独特优势,互联网已经渗入到现代生活中的各个领域,为全球人民的日常工作、学习和生活提供了极大的便利,同时互联网也为促进全球的信息技术发展和经济发展起到了积极的作用。
1.1 课题背景研究
互联网自 1969 年在美国诞生以来,已经发展了整整 50 年。互联网早期主要用于学术研究和军事领域,自 20 世纪 90 年代投入商业使用以来,它得到了迅速发展,现已经扩展到世界五大洲的 240 多个国家和地区。互联网信息传输以高速传播、价格低成本、覆盖范围广的独特优势,互联网已经渗入到现代生活中的各个领域,为全球人民的日常工作、学习和生活提供了极大的便利,同时互联网也为促进全球的信息技术发展和经济发展起到了积极的作用。
中国互联网的发展始于 20 世纪 80 年代末。发展过程大致可分为四个阶段:初步探索阶段、基本网络建设阶段、网络普及阶段和网络繁荣阶段,随着互联网技术的普及和进步,各种各样形式的 APP 应用不断涌现,互联网应用领域也在不断扩大。互联网的应用已经从早期的信息浏览和电子邮件发展到多样化的应用,例如娱乐、新闻、通信、商业交易和政府服务。网络的各类信息已经发展成为各种类繁多、数量巨大、规模庞大的在线数据库。
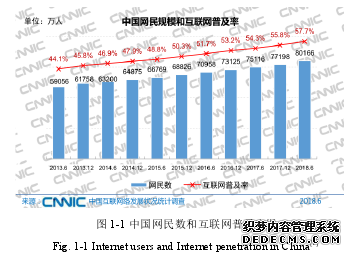
随着经济发展,互联网用户的规模及普及率不断提高,对于我国当前互联网的发展现状,中国互联网络信息中心在 2018 年 8 月发表了一份报告,即《第 47 次中国互联网络发展状况统计报告》[1],该报告表明截至 2018 年 6 月份,我国网民规模达到 8.02 亿,上半年新增网民约 2968 万人,较 2017 年末增加 3.8%,互联网普及率达 57.7%[1]。
........................
1.2 国内外研究现状
网络热词发现与分析主要依靠两大技术,即爬虫技术和文本挖掘技术。首先收集web内容以获取原始数据,然后对所需的数据信息进行预处理和过滤,最后利用文本分析等方法实现网络热词发现。全面、及时、迅速的热词信息可以为决策层做出正确的判断提供可靠的分析依据。
1.2.1 国外话题发现研究现状
目前,国外关于话题发现的研究比国内起步更早,并且已经取得了一些成果。自 1996年提出话题发现(TDT)概念以来,TDT 一直受到学者们的关注。学者们对 TDT 的研究已经逐渐从算法层面转移到应用层面,为数据挖掘、自然语言处理和机器学习的研究奠定了坚实的基础。然而,由于文本数据、视频数据、图像数据和音频数据的格式不同,传统的机器学习算法并不十分令人满意。
近年来,许多外国学者致力于拓展 TDT 技术,希望能使 TDT 技术能够得到更广泛的应用。自 1998 年以来,每年都召开话题检测和跟踪的国际会议,邀请 IBM、BBN 和许多其他企业和教育研究人员参加。随着研究成果的成熟,TDT 技术的应用范围也逐渐扩大。
许多不同语言的专家已经开始研究话题发现的相关内容,不同语言的 TDT 研究的内容和重点也有很大不同,因此多国语言的处理成为话题发现问题研究中的一个难点。近年来,随着互联网技术的快速发展和 Twitter 等社交网络的日益广泛应用,TDT 的研究范围不再局限于新闻语料库,越来越多的学者开始从事社交网络中话题发现的研究。
........................
第二章 相关技术
第二章 相关技术
2.1 Python 及开发平台
本系统的实现是基于 Python 平台,Python 语言是目前流行编程语言中比较易学、易读、易维护的一种语言,而且具有规模庞大的第三方库。Python 除了拥有传统编译语言的强大性和通用性,也借鉴了简单脚本和解释语言的易用性。在功能上,Python 还支持网络爬虫功能和大数据分析功能,可谓是集各家之所长为一体。Python 在进行情感分类时拥有它独特的优势,虽然它的算法本质上仍然是沿用了神经网络或机器学习,相对于其他语言,Python 但在操作性和实用性方面更具优势,使用户更容易获取到情感分类结果[13]。经过多年的发展和标准制定,Python 提供了丰富的标准库,同时提供成熟可靠的的 web 框架,简化的 web 开发的过程[14]。基于 Python 开发者“简单胜于复杂”的哲学,使 Python 源代码比 Perl 更具可读性,同时还支持大型软件开发[15]。
本系统的实现是基于 Python 平台,Python 语言是目前流行编程语言中比较易学、易读、易维护的一种语言,而且具有规模庞大的第三方库。Python 除了拥有传统编译语言的强大性和通用性,也借鉴了简单脚本和解释语言的易用性。在功能上,Python 还支持网络爬虫功能和大数据分析功能,可谓是集各家之所长为一体。Python 在进行情感分类时拥有它独特的优势,虽然它的算法本质上仍然是沿用了神经网络或机器学习,相对于其他语言,Python 但在操作性和实用性方面更具优势,使用户更容易获取到情感分类结果[13]。经过多年的发展和标准制定,Python 提供了丰富的标准库,同时提供成熟可靠的的 web 框架,简化的 web 开发的过程[14]。基于 Python 开发者“简单胜于复杂”的哲学,使 Python 源代码比 Perl 更具可读性,同时还支持大型软件开发[15]。
网络上 Python 拥有众多发行版本,本系统使用的是 Anaconda Python 3.6 版本,该版本打包 Python 及其常用包,支持 Windows、Linux 和 Mac OS 系统。对于开发者来说它就是省时省心的分析利器[16]。Anaconda 不仅安装方便而且可以自动安装相应的依赖包,满足不同项目的需求。同事它包含 720 多个与数据科学相关的开源包,涉及数据可视化、机器学习、深入学习以及其他许多方面,可以快捷的进行大数据分析、人工智能学习 [17]。
.........................
2.2 中文分词
本系统使用了 Python 的第三方库,涉及了几种中文分词算法。包括了 Tire 树、Character-Based Generative Model、HMM,下面简单介绍下各种算法的特点和优势。
Tire 树也称为字典树、词搜索树、前缀树等。它是树形结构和哈希树的变体,典型的应用程序是计数、排序和保存大量字符串(但不限于字符串),因此搜索引擎系统经常使用它来统计单词频率。Tire 树的核心理念是空间改变时间,使用字符串的公共前缀来减少查询时间的开销,以提高效率[18]。所以 Tire 的最大的优点就是通过使用字符串的公共前缀可以减少查询时间,减少不必要的字符串比较,所以查询效率高于哈希树。同时由于 Tire 树是基于时间空间的概念,系统中存在大量没有公共前缀的字符串将消耗大量内存。
中文分词(Chinese word segmentation, CWS)的统计学习模型大致可以分为两类:Word-Based Generative Model 与 Character-Based Discriminative Model,其中 Word-Based Generative Model 特点是高召回 IV(in-vocabulary)、低召回 OOV(out-of-vocabulary),而 Character-Based Discriminative Model 特点是高召回 OOV,低召回 IV。鉴于两种 CWS模型的利弊,Snow Nlp 的作者结合两种模型的特点,提出了 Character-Based Generative Model[19] 。但由于作者在求解 Generative Model 的最大值采用了穷举法,导致分词效率较低。
.........................
2.2 中文分词
本系统使用了 Python 的第三方库,涉及了几种中文分词算法。包括了 Tire 树、Character-Based Generative Model、HMM,下面简单介绍下各种算法的特点和优势。
Tire 树也称为字典树、词搜索树、前缀树等。它是树形结构和哈希树的变体,典型的应用程序是计数、排序和保存大量字符串(但不限于字符串),因此搜索引擎系统经常使用它来统计单词频率。Tire 树的核心理念是空间改变时间,使用字符串的公共前缀来减少查询时间的开销,以提高效率[18]。所以 Tire 的最大的优点就是通过使用字符串的公共前缀可以减少查询时间,减少不必要的字符串比较,所以查询效率高于哈希树。同时由于 Tire 树是基于时间空间的概念,系统中存在大量没有公共前缀的字符串将消耗大量内存。
中文分词(Chinese word segmentation, CWS)的统计学习模型大致可以分为两类:Word-Based Generative Model 与 Character-Based Discriminative Model,其中 Word-Based Generative Model 特点是高召回 IV(in-vocabulary)、低召回 OOV(out-of-vocabulary),而 Character-Based Discriminative Model 特点是高召回 OOV,低召回 IV。鉴于两种 CWS模型的利弊,Snow Nlp 的作者结合两种模型的特点,提出了 Character-Based Generative Model[19] 。但由于作者在求解 Generative Model 的最大值采用了穷举法,导致分词效率较低。
隐马尔可夫模型(Hidden Markov Model)是美国数学家鲍姆提出的,隐马尔可夫模型(鲍姆-韦尔奇算法)的训练方法也以他命名。隐马尔可夫算法模型(HMM)的核心是动态时间序列统计模型,该统计模型具有非常严谨的数据结构和相对可靠的计算性能,在语音识别的早期技术中占有重要的地位。近几十年来,隐马尔科夫模型开始被各个研究者广泛地应用于各领域中,例如智能手机中的语音识别、安防系统中的行为识别、生物学和经济领域等。在一些对中国股市的信息分析研究中,通过使用贝叶斯和马尔科夫链蒙特卡洛的方法,验证了该模型对市场信息的识别能力较强[20]。隐马尔可夫模型一直被认为是解决大多数自然语言处理问题的最快、最有效的方法[21]。
...........................
...........................
3.1 系统需求分析 ................................... 10
3.2 系统功能需求 ........................................... 10
第四章 系统设计 ........................................ 13
4.1 系统架构设计 ............................................. 13
4.2 系统功能设计 ................................... 14
第五章 系统实现 ................................................... 23
5.1 运行环境和开发平台 ......................................... 23
5.2 数据导入模块 ........................................ 24
第六章 系统测试
6.1 数据导入
数据导入模块测试分为数据导入测试和模板下载测试。数据导入功能需要能将用户的数据一键导入系统,同时分别支持词云、词频、情感数据导入。模板下载功能需要测试用户是否能顺利下载 FTP 服务器上的模板。
数据导入模块测试分为数据导入测试和模板下载测试。数据导入功能需要能将用户的数据一键导入系统,同时分别支持词云、词频、情感数据导入。模板下载功能需要测试用户是否能顺利下载 FTP 服务器上的模板。
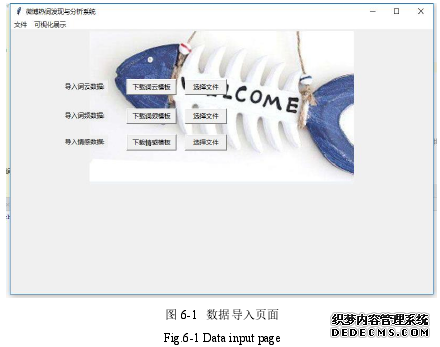
数据导入页面运行效果如图 6-1 所示:
............................
............................
第七章 总结与展望
7.1 全文总结
论文主要论述了微博热词发现与分析系统的背景、意义、需求分析、系统设计、系统实现、系统测试等阶段的工作。本文设计并实现了一种操作简单、平台化的热词发现与分析系统。系统架构上采用典型的三层架构,将系统的整个业务应用划分为:表现层、业务逻辑层、数据访问层,每个模块只需完成独立子功能,与其他模块的联系最少且接口简单。从而降低了各层之间的依赖,达到了“高内聚,低耦合”的目的,该架构使得本系统结构清晰、耦合度低、可维护性高、可扩展性高,容易适应需求变化。
本文对微博数据进行了数据挖掘分析和可视化展示。通过词云图、词频 Top10、情感统计为用户提供多了多维度的数据分析。可视化帮助用户过滤大量的低频、低质信息,只需要一眼扫过即可领会文本主旨。#p#分页标题#e#
本文针对过滤停用词、情感分析部分还做优化,提高分词的准确性和情感分析的效果。在优化停用词表时,考虑到网络词汇、符号、emoji 表情的快速更新,本文采用并合并了一些网络上比较热门的停用词表,提高停用词的过滤效果。在测试中证明,停用词过滤效果有了明显改善。情感分析部分,由于 Snow NLP 采用的是商品评论数据进行的训练,导致在对微博内容情感分析时效果一般,本文针对这种情况,收集了一些微博的评论语料并进行训练。通过对比新旧语料库在不同情感系数下的精确率和召回率,选用了新语料库及最优的情感系数。
总体来说,本文设计和实现的微博热词发现与分析系统架构清晰、可扩展性高,已经实现了数据的一键导入、自动分析、可视化展现功能。
参考文献(略)
7.1 全文总结
论文主要论述了微博热词发现与分析系统的背景、意义、需求分析、系统设计、系统实现、系统测试等阶段的工作。本文设计并实现了一种操作简单、平台化的热词发现与分析系统。系统架构上采用典型的三层架构,将系统的整个业务应用划分为:表现层、业务逻辑层、数据访问层,每个模块只需完成独立子功能,与其他模块的联系最少且接口简单。从而降低了各层之间的依赖,达到了“高内聚,低耦合”的目的,该架构使得本系统结构清晰、耦合度低、可维护性高、可扩展性高,容易适应需求变化。
本文对微博数据进行了数据挖掘分析和可视化展示。通过词云图、词频 Top10、情感统计为用户提供多了多维度的数据分析。可视化帮助用户过滤大量的低频、低质信息,只需要一眼扫过即可领会文本主旨。#p#分页标题#e#
本文针对过滤停用词、情感分析部分还做优化,提高分词的准确性和情感分析的效果。在优化停用词表时,考虑到网络词汇、符号、emoji 表情的快速更新,本文采用并合并了一些网络上比较热门的停用词表,提高停用词的过滤效果。在测试中证明,停用词过滤效果有了明显改善。情感分析部分,由于 Snow NLP 采用的是商品评论数据进行的训练,导致在对微博内容情感分析时效果一般,本文针对这种情况,收集了一些微博的评论语料并进行训练。通过对比新旧语料库在不同情感系数下的精确率和召回率,选用了新语料库及最优的情感系数。
总体来说,本文设计和实现的微博热词发现与分析系统架构清晰、可扩展性高,已经实现了数据的一键导入、自动分析、可视化展现功能。
参考文献(略)

