1 绪论
1.1 背景和意义
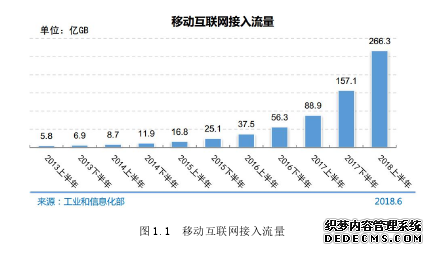
近几年物联网技术的快速发展和互联网技术的日趋完善,社会信息化已经成为当今国家和社会发展的大趋势。视频、图像、音频和文本等多媒体信息已经逐渐成为人们获取最新国内外资讯的重要途径。互联网覆盖范围的增大、网络速度的快速提升以及移动端 4G 和 5G 网络的出现,使得我国进入了大数据时代的黄金时期。据国家关于移动互联网流量数据的报告显示,2018 年 1 月到 6 月的数据流量为 266 亿 GB,文中所述如图 1.1 所示。随着爱奇艺、优酷视频和腾讯视频等网络视频平台的推广和普及,抖音短视频、西瓜短视频和火山小视频等可以上传视频分享生活的手机应用出现,以及网络用户和移动端用户的快速增长,使得移动端视频的数据量规模呈指数型增长。
根据第 42 次《中国互联网络发展状况统计报告》:如图 1.2 所示,截止至2018 年 6 月,网络视频用户规模达 6.09 亿,较去年末增长 3014 万,占网民总体的 76.0%。手机网络视频用户规模达到 5.78 亿,较去年末增加 2929 万,占手机网民的 73.4%。各个短视频应用的用户规模达 5.94 亿,合并短视频应用的网络视频用户使用率高达 88.7%[1]。在用户规模和网络视频规模快速扩大和增长的同时,国家也会对网络视频平台的内容出台相关规章制度和定期的内容审查,但是对于网络上个人发布短视频大部分都是由每种应用软件独自对其进行审查,而现有的技术对网络视频审核速度无法匹配用户发布网络视频的速度,同时也需要耗费人工进行操作,这样会使得网络上的视频内容变得无法控制,大部分庸俗、无趣和虚假的网络视频流入到网络上,对整个视频网络的生态环境产生了非常恶劣的影响。因此,针对短视频的问题,国家相关管理部门颁布了一系列的措施和对部分不正规的应用软件进行监督等办法来对这些违规的视频进行监控和整治,但同时也需要相应的手机应用在技术上提高对视频内容的审核技术。对于技术方面的提升,可以在视频上传的终端位置来进行判断,当视频在压缩上传的过程中,针对压缩信息做相应技术上的处理来进行判断视频内容是否符合现有的审查规定来决定当前视频是否应该上传。
.............................
1.2 国内外研究现状
在全世界内,随着视频监控系统的大范围布署,视频监控相关的领域近年来也逐渐受到了广泛的研究。从视频监控系统中获取信息变得越来越重要,尤其是在一些特定的环境下视频监控系统对内容信息的获取[6]。视频监控中运动物体识别是计算机视觉的一个重要研究领域,也是实现智能化监控的技术的热点问题之一[7]。视频中运动物体识别对于智能化视频监控技术中的目标分类、目标跟踪和行为理解等后续研究起着关键的作用。目前视频中运动物体识别方法大约分为以下几类,背景差分法、帧差法、光流法和使用深度学习技术的识别法。
(1)背景差分法
背景差分法是常用的运动物体识别方法之一,它的基本思想是通过计算当前帧与背景模型之间的差异来对运动区域进行提取,因此背景建模是实现背景减法的关键[8]。目前为止基于背景差分法已经设计了很多改进算法,常见的背景建模方法有:阈值法、码本法、混合高斯模型、和均值模型等。其中,由 Stauffer和 Friedman 等人提出的高斯混合模型可以模拟场景中周期运动的存在,例如叶子摇摆,旗帜飘动,显示闪烁,是最广泛使用的背景模型之一[9]。陈凤东等人[10]设置动态阈值的方法来解决复杂环境下光照变化对背景建模的影响,通过计算相邻图像中整体图像光照变换的平均值作为更新背景模型的阈值,减少复杂环境下光照变换带来的影响。R Zhang 等人[11]使用中值滤波器来实现视频背景模型的构建,使用自适应背景差分法来检测物体。Zang X 等人[12]使用高斯混合模型自适应地学习差异阈值来区分前景和背景,这样可以使得建立的背景模型减少环境因素和运动物体轻微抖动所带来的影响。
(2)帧差法
帧差法是另一种常用的视频目标检测方法,该算法的原理并不复杂,首先是在视频序列中选择前后相邻的视频帧,然后将相邻的视频帧进行像素级别的减法操作,最终出现像素变换大的区域就是运动物体的区域。帧差法对光线等场景变化不敏感,适应各种环境和场景。但是这种方法会在运动物体内部存在很多无法连接的空洞现象,也就是会出现无法连接空白区域。为了解决这个问题,IntanKartika 等人[13]引入了基于自适应阈值和阴影检测处理技术来消除出现的空洞现象,Zhao M 等人[14]基于视频帧中相邻三帧差值和背景差分法的混合方法。WHuang 等人[15]通过求得的背景平均值和当前帧之间的数值差来补偿空洞问题。虽然优化空洞现象的算法在逐渐完善,但是其所带来的后果是改进的帧差法的计算量越来越大,运行速度也是越来越慢。
................................
2 深度学习与视频压缩
2.1 深度学习相关理论
2006 年加拿大多伦多大学的 Geofrey Hinton 教授在神经网络方面提出深度学习模型训练方法的改进模型,极大的提高了基于 BP 反馈神经网络的训练速度和训练的最优问题[30],使得深度学习模型再次回归到科研领域的视野中,此后开始了深度学习的崛起浪潮,目前深度学习已经应用于大部分领域中,本小结主要是对深度学习的发展历史和当前深度学习的常用的网络结构做理论分析。
2.1.1 深度学习
深度学习是机器学习模型之一,机器学习通过训练样本是否有对应的标签数据可以分为监督学习和无监督学习两大类[31]。在监督学习中,输入到模型中的一组样本,其对应输出的结果是在何种范围之内或者输入和输出需要保持某种特定的逻辑关系,都可以通过标签给出准确的答案,监督学习根据其输出是离散值还是连续值可分为分类问题模型和回归问题模型[32]。无监督学习算法有聚类算法、主成分分析方法、局部线性嵌入方法和拉普拉斯特征映射方法等。其中聚类算法是无监督学习中最经典的算法,一般是将样本数据集中每个样本之间定义相似性度量,然后根据定义的相似性度量将距离相近的样本组合到一起形成一个簇,一个不错的聚类算法是可以在其分的每个簇族之内具有高类内相似性,簇与簇之间具有低类间相似性。聚类算法大致可分为 7 类算法:分层聚类算法、基于密度的聚类算法、分区聚类算法、基于图的聚类算法、基于网格的算法、基于模型的聚类算法和组合聚类算法[33],将聚类算法分成七大类是根据算法各自的基本思想,
1.2 国内外研究现状
在全世界内,随着视频监控系统的大范围布署,视频监控相关的领域近年来也逐渐受到了广泛的研究。从视频监控系统中获取信息变得越来越重要,尤其是在一些特定的环境下视频监控系统对内容信息的获取[6]。视频监控中运动物体识别是计算机视觉的一个重要研究领域,也是实现智能化监控的技术的热点问题之一[7]。视频中运动物体识别对于智能化视频监控技术中的目标分类、目标跟踪和行为理解等后续研究起着关键的作用。目前视频中运动物体识别方法大约分为以下几类,背景差分法、帧差法、光流法和使用深度学习技术的识别法。
(1)背景差分法
背景差分法是常用的运动物体识别方法之一,它的基本思想是通过计算当前帧与背景模型之间的差异来对运动区域进行提取,因此背景建模是实现背景减法的关键[8]。目前为止基于背景差分法已经设计了很多改进算法,常见的背景建模方法有:阈值法、码本法、混合高斯模型、和均值模型等。其中,由 Stauffer和 Friedman 等人提出的高斯混合模型可以模拟场景中周期运动的存在,例如叶子摇摆,旗帜飘动,显示闪烁,是最广泛使用的背景模型之一[9]。陈凤东等人[10]设置动态阈值的方法来解决复杂环境下光照变化对背景建模的影响,通过计算相邻图像中整体图像光照变换的平均值作为更新背景模型的阈值,减少复杂环境下光照变换带来的影响。R Zhang 等人[11]使用中值滤波器来实现视频背景模型的构建,使用自适应背景差分法来检测物体。Zang X 等人[12]使用高斯混合模型自适应地学习差异阈值来区分前景和背景,这样可以使得建立的背景模型减少环境因素和运动物体轻微抖动所带来的影响。
(2)帧差法
帧差法是另一种常用的视频目标检测方法,该算法的原理并不复杂,首先是在视频序列中选择前后相邻的视频帧,然后将相邻的视频帧进行像素级别的减法操作,最终出现像素变换大的区域就是运动物体的区域。帧差法对光线等场景变化不敏感,适应各种环境和场景。但是这种方法会在运动物体内部存在很多无法连接的空洞现象,也就是会出现无法连接空白区域。为了解决这个问题,IntanKartika 等人[13]引入了基于自适应阈值和阴影检测处理技术来消除出现的空洞现象,Zhao M 等人[14]基于视频帧中相邻三帧差值和背景差分法的混合方法。WHuang 等人[15]通过求得的背景平均值和当前帧之间的数值差来补偿空洞问题。虽然优化空洞现象的算法在逐渐完善,但是其所带来的后果是改进的帧差法的计算量越来越大,运行速度也是越来越慢。
................................
2 深度学习与视频压缩
2.1 深度学习相关理论
2006 年加拿大多伦多大学的 Geofrey Hinton 教授在神经网络方面提出深度学习模型训练方法的改进模型,极大的提高了基于 BP 反馈神经网络的训练速度和训练的最优问题[30],使得深度学习模型再次回归到科研领域的视野中,此后开始了深度学习的崛起浪潮,目前深度学习已经应用于大部分领域中,本小结主要是对深度学习的发展历史和当前深度学习的常用的网络结构做理论分析。
2.1.1 深度学习
深度学习是机器学习模型之一,机器学习通过训练样本是否有对应的标签数据可以分为监督学习和无监督学习两大类[31]。在监督学习中,输入到模型中的一组样本,其对应输出的结果是在何种范围之内或者输入和输出需要保持某种特定的逻辑关系,都可以通过标签给出准确的答案,监督学习根据其输出是离散值还是连续值可分为分类问题模型和回归问题模型[32]。无监督学习算法有聚类算法、主成分分析方法、局部线性嵌入方法和拉普拉斯特征映射方法等。其中聚类算法是无监督学习中最经典的算法,一般是将样本数据集中每个样本之间定义相似性度量,然后根据定义的相似性度量将距离相近的样本组合到一起形成一个簇,一个不错的聚类算法是可以在其分的每个簇族之内具有高类内相似性,簇与簇之间具有低类间相似性。聚类算法大致可分为 7 类算法:分层聚类算法、基于密度的聚类算法、分区聚类算法、基于图的聚类算法、基于网格的算法、基于模型的聚类算法和组合聚类算法[33],将聚类算法分成七大类是根据算法各自的基本思想,
研究人员根据不同应用的背景使用上述的聚类算法来获得最优的结果。
近年来随着人工智能技术的快速发展,深度学习逐渐回归到人们的视野里,深度学习是指三层以上的人工神经网络(Artificial Neural Network),看似一个突然出现的全新领域,其实在 19 世纪 50 年代就已经出现了,只是这个技术的名称随着时间的发展变换了很多次。深度学习的历史发展进程与其名称的变换有着相同的步伐。19 世纪 50 年代到 20 世纪 60 年代初,是人工智能发展的起点同时也是深度学习技术雏形的出现,这个时候深度学习叫做控制论;20 世纪 60 年代到20世纪90 年代人工智能技术从实验室中的理论探讨开始逐步走向现实世界的应用中,包括在工业,农业和医疗等领域都取得了巨大的成功,此时的深度学习技术被叫做联结主义;从 21 世纪初到现在,人工智能技术迎来了爆发式的发展阶段,深度学习技术也迎来了蓬勃的发展并以深度学习的名字出现在人们的视线当中[34]。无论是爆发式的发展还是蓬勃的发展,其背后是得益于大数据和物联网等当今主流技术的发展所带来的大容量的数据规模,同时图形图像处理器等硬件技术的提升也将深度学习技术的训练时间缩短至人们可以接受的范围之内。深度学习是属于机器学习技术领域的神经网络中的一个分支。
近年来随着人工智能技术的快速发展,深度学习逐渐回归到人们的视野里,深度学习是指三层以上的人工神经网络(Artificial Neural Network),看似一个突然出现的全新领域,其实在 19 世纪 50 年代就已经出现了,只是这个技术的名称随着时间的发展变换了很多次。深度学习的历史发展进程与其名称的变换有着相同的步伐。19 世纪 50 年代到 20 世纪 60 年代初,是人工智能发展的起点同时也是深度学习技术雏形的出现,这个时候深度学习叫做控制论;20 世纪 60 年代到20世纪90 年代人工智能技术从实验室中的理论探讨开始逐步走向现实世界的应用中,包括在工业,农业和医疗等领域都取得了巨大的成功,此时的深度学习技术被叫做联结主义;从 21 世纪初到现在,人工智能技术迎来了爆发式的发展阶段,深度学习技术也迎来了蓬勃的发展并以深度学习的名字出现在人们的视线当中[34]。无论是爆发式的发展还是蓬勃的发展,其背后是得益于大数据和物联网等当今主流技术的发展所带来的大容量的数据规模,同时图形图像处理器等硬件技术的提升也将深度学习技术的训练时间缩短至人们可以接受的范围之内。深度学习是属于机器学习技术领域的神经网络中的一个分支。
.............................
H.264/AVC 对每一个视频帧都不是独立的进行编码,而是尽可能地利用编码数据之间的相似区域,仅记录位置差异和纹理差异。未编码视频中的冗余信息主要是时间冗余和空间冗余,H.264/AVC 通过帧内预测方法消除空间冗余,并通过帧间预测方法消除时间冗余。每帧被分成 NxN 大小的像素宏块。宏块包含完整的像素信息,宏块的类型共有三种:I 宏块,P 宏块和 B 宏块。
帧内预测使用来自同一帧内的已编码完成的相邻宏块的类似区域来预测当前宏块的参数值。这些参数值包括亮度和色度的预测。帧内预测块的亮度分量大小有三个选项:16×16,8×8 和 4×4。对于 4×4 或 8×8 大小的宏块,根据当前宏块正上方的相邻区域执行帧内预测。如果所选择的大小是 16x16,则通过将宏块组合到当前宏块的左侧或上方来预测。通常,编码器选择合适的帧内预测模式以最小化预测中的比特和残差的总数[42]。宏块的色度分量是从顶部或左侧宏块的色度分量预测的。
..........................
3 视频压缩域的运动矢量图构建方法................................ 18
3.1 视频压缩域数据分析.................................... 18
3.1.1 运动矢量.................................18
3.1.2 DCT 系数.............................19
4 面向运动矢量图的深度神经网络模型............................. 29
4.1 面向运动矢量图的空间特征提取网络模型................................ 29
4.1.1 MS-CNN 网络设计................................... 29
4.1.2 MS-CNN 损失函数和优化算法................ 31
5 面向视频压缩域的目标实时识别........................ 39
5.1 视频压缩域目标识别问题.................................... 39
5.2 面向视频压缩域的识别方法......................... 39
5 面向视频压缩域的目标实时识别
5.1 视频压缩域目标识别问题
2.2 视频压缩技术
2.2.1 视频压缩原理
视频压缩域技术广泛的应用于不同的领域中,如视频传输,广播数字视频,高清晰度电视业务等。视频压缩技术的目的是减少视频图像的数据量,视频编码是降低视频比特率来减少资源的消耗进行传输和存储,同时对解码后的视频有良好的恢复保证。视频图像压缩是以频繁的间隔采样运动图像,通常为每秒 25 帧,作为帧序列存储。当前主流的视频压缩标准是 H.264/AVC,其框架是一种分层结构,按照功能共分为两层,视频编码层(Video Coding Layer,VCL)和网络提取层(Network Abstarction Layer,NAL),视频编码层主要是对视频图像数据进行有序的编解码,网络提取层将经过视频编码层处理过的视频数据进行封装起来,封装之后的数据可以高效的通过网络进行传输和在存储硬件中进行存储。#p#分页标题#e#
2.2.1 视频压缩原理
视频压缩域技术广泛的应用于不同的领域中,如视频传输,广播数字视频,高清晰度电视业务等。视频压缩技术的目的是减少视频图像的数据量,视频编码是降低视频比特率来减少资源的消耗进行传输和存储,同时对解码后的视频有良好的恢复保证。视频图像压缩是以频繁的间隔采样运动图像,通常为每秒 25 帧,作为帧序列存储。当前主流的视频压缩标准是 H.264/AVC,其框架是一种分层结构,按照功能共分为两层,视频编码层(Video Coding Layer,VCL)和网络提取层(Network Abstarction Layer,NAL),视频编码层主要是对视频图像数据进行有序的编解码,网络提取层将经过视频编码层处理过的视频数据进行封装起来,封装之后的数据可以高效的通过网络进行传输和在存储硬件中进行存储。#p#分页标题#e#
2.2.2 视频压缩结构
(1)压缩域中的预测结构H.264/AVC 对每一个视频帧都不是独立的进行编码,而是尽可能地利用编码数据之间的相似区域,仅记录位置差异和纹理差异。未编码视频中的冗余信息主要是时间冗余和空间冗余,H.264/AVC 通过帧内预测方法消除空间冗余,并通过帧间预测方法消除时间冗余。每帧被分成 NxN 大小的像素宏块。宏块包含完整的像素信息,宏块的类型共有三种:I 宏块,P 宏块和 B 宏块。
帧内预测使用来自同一帧内的已编码完成的相邻宏块的类似区域来预测当前宏块的参数值。这些参数值包括亮度和色度的预测。帧内预测块的亮度分量大小有三个选项:16×16,8×8 和 4×4。对于 4×4 或 8×8 大小的宏块,根据当前宏块正上方的相邻区域执行帧内预测。如果所选择的大小是 16x16,则通过将宏块组合到当前宏块的左侧或上方来预测。通常,编码器选择合适的帧内预测模式以最小化预测中的比特和残差的总数[42]。宏块的色度分量是从顶部或左侧宏块的色度分量预测的。
..........................
3 视频压缩域的运动矢量图构建方法................................ 18
3.1 视频压缩域数据分析.................................... 18
3.1.1 运动矢量.................................18
3.1.2 DCT 系数.............................19
4 面向运动矢量图的深度神经网络模型............................. 29
4.1 面向运动矢量图的空间特征提取网络模型................................ 29
4.1.1 MS-CNN 网络设计................................... 29
4.1.2 MS-CNN 损失函数和优化算法................ 31
5 面向视频压缩域的目标实时识别........................ 39
5.1 视频压缩域目标识别问题.................................... 39
5.2 面向视频压缩域的识别方法......................... 39
5 面向视频压缩域的目标实时识别
5.1 视频压缩域目标识别问题
传统的目标识别方法计算复杂度较高,识别速率较慢。目前使用深度学习方法可以使得识别的准确度有所提高,但是大多数模型的输入数据仍然受到传统方法的限制,无法提高识别速率。
本文将深度学习的输入部分改为视频压缩域中的运动矢量信息,在输入数据方面提高整个识别过程的速度,同时为了不丢失视频压缩域中的空间和时序信息,分别采用两个不同的模型对其进行特征提取,最终在对样本数据进行识别。
本文将深度学习的输入部分改为视频压缩域中的运动矢量信息,在输入数据方面提高整个识别过程的速度,同时为了不丢失视频压缩域中的空间和时序信息,分别采用两个不同的模型对其进行特征提取,最终在对样本数据进行识别。
本章实验的数据集是全球 AI 挑战赛短视频实时分类数据集,该数据集是一个大型的公开视频数据集,由于此数据集视频的标签是多标签体系,每条视频有1-3 个标签,每个标签信息包含主体、场景和动作。而本文的目的是识别视频中的物体,并不需要识别出物体的行为和场景信息,因此本文将标签中的其他信息去掉,仅保留主体的信息。为了节约存储空间和提高存储效率,将训练样本空间特征提取结束后的特征向量和其对应标签分别存储到 HDF5 文件中。
........................
6 总结与展望
6.1 总结
视频压缩技术经过近几十年的发展已经非常成熟,在改变着视频传输的同时也改变着人们的生活。深度学习技术是近几年热点研究领域。国内外学者对视频压缩域和深度学习技术相结合的研究和应用,目前已有很多研究人员取得了初步的效果。本文在大量阅读国内外文献和相关技术书籍的前提下,将视频压缩域中运动矢量数据应用到深度学习中的神经网络模型中,为视频压缩域和深度学习技术结合献出一份贡献。其主要工作总结如下:
........................
6 总结与展望
6.1 总结
视频压缩技术经过近几十年的发展已经非常成熟,在改变着视频传输的同时也改变着人们的生活。深度学习技术是近几年热点研究领域。国内外学者对视频压缩域和深度学习技术相结合的研究和应用,目前已有很多研究人员取得了初步的效果。本文在大量阅读国内外文献和相关技术书籍的前提下,将视频压缩域中运动矢量数据应用到深度学习中的神经网络模型中,为视频压缩域和深度学习技术结合献出一份贡献。其主要工作总结如下:
(1)本文首先对深度学习和视频压缩技术的研究背景及课题的研究意义进行了概述,对当前网络视频的现状和视频识别的技术进行探讨,同时对视频压缩域中可用信息的使用也进行了分析。为接下来基于视频压缩域的视频识别提供了基础。
(2)本文基于视频压缩技术的结构,对视频压缩过程中产生的可用信息分析,提取视频帧与帧之间的运动差异信息的运动矢量数据作为视频压缩过程中的应用数据,并利用图像二值化和图像学中形态学闭运算的方法将其还原成图像的形式来用于深度学习模型的训练。
(2)本文基于视频压缩技术的结构,对视频压缩过程中产生的可用信息分析,提取视频帧与帧之间的运动差异信息的运动矢量数据作为视频压缩过程中的应用数据,并利用图像二值化和图像学中形态学闭运算的方法将其还原成图像的形式来用于深度学习模型的训练。
(3)近几年人工智能的迅猛发展,使得深度学习技术也逐渐步入人们的视野,在图像图像领域深度学习技术已经逐渐成为主流技术。本文根据卷积神经网络模型的变体 VGG 网络和 ResNet 网络提出 MS-CNN 网络,该网络对输入的矩形运动矢量图进行空间特征的提取,再根据长短期记忆网络设计 MT-LSTM 网络对空间特征数据进行时序特征的提取并进行数据样本的识别。最终通过与光流法和原始视频帧作对比,本文方法在准确率方面的与其他两种方法差距在可接受范围之内,但是本文的方法对视频帧的处理速度是优于其他两种方法,并且能够达到对视频数据的实时处理。
参考文献(略)

