第1章 绪论
1.1 研究背景及意义
1.1.1 研究背景
经济的发展大大地提高了人们的生活水平,人们对交通出行的舒适度要求也越来越高,刺激了小汽车的销量。以深圳为例,2004 至 2014 年这 10 年中,机动车数量竟以高达 10 倍的速度增长,市政府不得不在 2015 年开始限牌行动来遏制机动车数量的高速增长。截至 2019 年 2 月,深圳市的机动车总数为 339.22 万辆[1],其中私家车超过 300 万辆,车辆密度达到 550 辆/公里,比国际警戒线 270 辆/公里几乎翻了一翻,高居全国榜首,导致城市交通拥堵和停车困难问题日益严重。另外,在北上广深等一线城市,每天都有超过三千万人次的出行,给城市交通带来了很大的压力,特别是在早晚高峰期。在深圳,地铁 1 号线在上下班高峰期的发车间隔已经压缩到 2 分钟以内的极限发车间隔了,但站厅和车厢的拥挤程度还是非常严重。公共交通的拥挤和长时间的等候已经无法满足人们快捷舒适的出行需求,2014 年开始,以滴滴、uber、神州专车等共享出行的交通模式开始快速兴起,到 2018 年 5 月滴滴在国内 400 多个城市为 4.5 亿用户服务,日订单量达到 3000 万单[2]。
物联网、移动互联网、云计算、大数据等技术的发展,让我们可以收集的数据种类越来越丰富,数据量也越来越大,使得我们在引导乘客出行、发展共享交通这两方面有了一定的数据基础。以往大多通过经验或使用数学建模的方法来分析人群和车辆,现在,对移动行为和城市交通的分析正在进入一个新的智能阶段,交通管理正在从“经验治理”转向“科学治理”,交通规划也从简单的经验建模模型、人工分析模型发展到数据驱动与人机智慧迭代的新型[3]。大数据技术为智能化提供决策依据,已经成为城市交通规划、停车场规划、道路信号灯配时、交通诱导、路况预测等的重要解决方法。例如,近年被人们广泛使用的公交电子站牌、实时交通路况等都是采用大数据分析车辆轨迹数据的应用,这些应用极大的方便了人们的交通出行。
...........................
...........................
1.2 国内外研究现状
1.2.1 用户出行行为分析相关研究
在用户出行行为分析研究方面,国外学者根据不同城市的特点分别定义了不同的活动模式,并分析了各种活动模式的特征,通过嵌套 logit 模型、聚类分析、结构方程式等方法定量描述了活动模式与外部因素的相关性。
童晓君(2012)用深圳市 2000 多台出租车 GPS 数据来研究了居民出行的时空分布特征,从日总出行次数、出行时间、空驶率等方面统计分析了居民出行时间的特征,把居民出行空间进行层次聚类得到居民出行热点区域 [4]。
1.2.1 用户出行行为分析相关研究
在用户出行行为分析研究方面,国外学者根据不同城市的特点分别定义了不同的活动模式,并分析了各种活动模式的特征,通过嵌套 logit 模型、聚类分析、结构方程式等方法定量描述了活动模式与外部因素的相关性。
童晓君(2012)用深圳市 2000 多台出租车 GPS 数据来研究了居民出行的时空分布特征,从日总出行次数、出行时间、空驶率等方面统计分析了居民出行时间的特征,把居民出行空间进行层次聚类得到居民出行热点区域 [4]。
张明月(2013)考虑了城市兴趣点对居民出行的影响,采用 K-Means 算法和密度聚类方法处理城市兴趣点。根据不同时间段内不同热点的影响程度,向出租车司机推荐载客地点[5]。
马云飞(2014)以昆山市为例,采用凝聚层次聚类算法和 GIS 分析方法,分工作日和非工作日分析居民出行热点区域,并从不同时间段分析这些热点区域的分布特征[6]。
张健钦等(2014)先用聚类方法对北京市出租车轨迹数据进行聚类分析,得到驾驶员的居住地,然后用序列相似性技术方法对驾驶员的作息规律性进行了分析[7]。
马云飞(2014)以昆山市为例,采用凝聚层次聚类算法和 GIS 分析方法,分工作日和非工作日分析居民出行热点区域,并从不同时间段分析这些热点区域的分布特征[6]。
张健钦等(2014)先用聚类方法对北京市出租车轨迹数据进行聚类分析,得到驾驶员的居住地,然后用序列相似性技术方法对驾驶员的作息规律性进行了分析[7]。
陈红丽(2016)先从出租车的轨迹数据中统计出乘客的出行时长、出行距离、日出行总量、分时段出行量等数据,然后使用 DBSCAN 算法对乘客上下车位置进行聚类,识别并提取居民出行的热点,并分析居民的出行时间和空间分布,以及出行热点[8]。
..................................
第2章 私家车拼车出行系统及相关技术
第2章 私家车拼车出行系统及相关技术
2.1 私家车拼车出行系统
2.1.1 私家车拼车出行系统需求
以滴滴、uber、神州专车等实时共享出行的交通模式迅速的席卷了全球,但这些以盈利为目的的快车、专车等共享出行模式对传统的出租车造成了很大的影响,目前在很多国家和地区都还未得到相关政策的认可。于是一些企业开始推出以非盈利为目的的顺风车、拼车等共享出行模式。顺风车和拼车出行都需要司机和乘客双方提前约定出发时间和出发地点,可以对司机的出行行为进行分析,预测司机下一次的出发时间及目的地,给乘客推荐合适的顺风车或拼车司机,实现司乘的快速、精准匹配。
2.1.1 私家车拼车出行系统需求
以滴滴、uber、神州专车等实时共享出行的交通模式迅速的席卷了全球,但这些以盈利为目的的快车、专车等共享出行模式对传统的出租车造成了很大的影响,目前在很多国家和地区都还未得到相关政策的认可。于是一些企业开始推出以非盈利为目的的顺风车、拼车等共享出行模式。顺风车和拼车出行都需要司机和乘客双方提前约定出发时间和出发地点,可以对司机的出行行为进行分析,预测司机下一次的出发时间及目的地,给乘客推荐合适的顺风车或拼车司机,实现司乘的快速、精准匹配。
2.1.2 私家车拼车出行系统框架
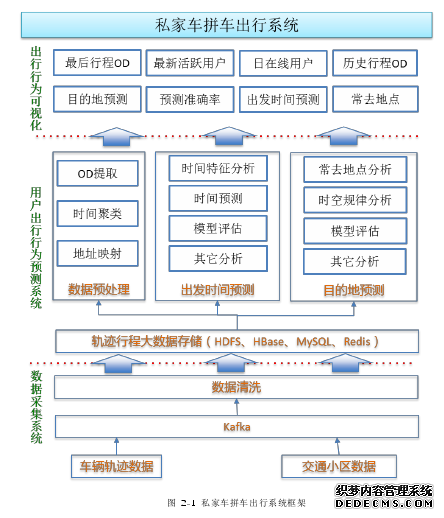
私家车拼车出行系统是一个非常有实际应用价值的系统,系统包括数据采集系统、用户出行行为预测系统、用户出行行为可视化等,本人在整个系统中主要负责用户出行行为预测子系统,是私家车拼车出行系统的核心。私家车拼车出行系统的框架如图 2-1:
..........................

.................................
私家车拼车出行系统是一个非常有实际应用价值的系统,系统包括数据采集系统、用户出行行为预测系统、用户出行行为可视化等,本人在整个系统中主要负责用户出行行为预测子系统,是私家车拼车出行系统的核心。私家车拼车出行系统的框架如图 2-1:
..........................
2.2 私家车用户出行行为分析及预测方法
2.2.1 互信息
互信息(Mutual Information)是用来度量两个事件之间的相关性的[38],假设有随机变量 M 和 N,且 M 和 N 服从联合分布, p(m,n)是 M 和 N 的联合概率分布函数,p(m)和p(n) 是 M 和 N 的边缘概率分布函数,若 M 和 N 是离散型变量,则互信息的表达式为:
2.2.1 互信息
互信息(Mutual Information)是用来度量两个事件之间的相关性的[38],假设有随机变量 M 和 N,且 M 和 N 服从联合分布, p(m,n)是 M 和 N 的联合概率分布函数,p(m)和p(n) 是 M 和 N 的边缘概率分布函数,若 M 和 N 是离散型变量,则互信息的表达式为:
.................................
3.1 引言 .................................... 21
3.2 数据集 ........................................ 21
3.3 数据预处理 ..................................... 23
第4章 基于随机森林的用户出行目的地预测 ............................ 39
4.1 引言 ......................................... 39
4.2 用户出行空间及出行规律分析 .................................. 39
第5章 用户出行行为预测系统实现与集成 ............................. 57
5.1 用户出行行为预测系统设计 ....................................... 57
5.1.1 系统需求分析 .......................................... 57
5.1.2 系统功能分析 ............................ 57
第5章 用户出行行为预测系统实现与集成
5.1 用户出行行为预测系统设计
用户出行预测系统是拼车出行系统中最重要的子系统,包含了拼车出行系统的核心算法,提供私家车用户出行行为分析和预测功能,让拼车出行系统的司机和乘客能快速匹配。
5.1.1 系统需求分析
用户出行行为预测系统主要是处理从车辆行车记录仪传送过来的车辆轨迹数据,对这些轨迹数据进行处理及分析,并能预测用户会在将来的某个时间点出发,也能预测用户在某个时间点、某个出发地点出行时要去的目的地,具体的需求如下:
1、 在地图上展示用户的某个 OD、常去的地点。
2、 预测用户下一次出行的出发时间。
3、 实时预测用户出行的目的地。
4、 预测将来某个时刻用户要去的目的地。
..........................
第6章 结论与展望
6.1 研究结论
本论文对深圳市的 2000 多辆私家车的真实轨迹数据进行分析和预测,主要完成了以下研究内容:
1、 数据预处理
轨迹中的空间数据是二维的,包括经度和纬度,且经纬度数据的精度要求非常高,达到小数点后六位,这种高精度的二维数据让我们很难准确的把同一地点上的不同的经纬度聚合在一起,本文将经纬度都映射到交通小区中,既为地点聚合提供了统一标准的解决方案,也能避免聚合后的地点在非正常的交通地点上,生成符合车辆行驶路径的 OD对。
2、 私家车用户出发时间预测
2、 私家车用户出发时间预测
先对用户的出行时间特征及规律进行分析,然后使用 K-Means 算法将连续的时间变量转换为离散的时间类别,再用随机森林来预测用户下一次的出发时间,并采用基于时间序列的 k 折交叉验证法和互信息来对模型预测的准确率进行评估。基于 K-Means 与随机森林的联合模型在覆盖率 70%时准确率 75%,优于朴素贝叶斯模型的 62%。
3、 私家车用户出行目的地预测
3、 私家车用户出行目的地预测
私家车用户的出行行为习惯会随着时间推移发生非常大的改变,也就是说用户的行为习惯可以视作是依赖时间的。本文构建了基于随机森林的模型来预测用户出行的目的地,并将训练数据逐日放到模型中训练,用训练集后一周的数据作为测试数据来测试,通过基于时间序列的 k 折交叉验证法来对模型预测的准确率进行测试评估,最后将模型的预测结果与朴素贝叶斯、滴滴用户出行目的地预测系统进行了对比分析。朴素贝叶斯模型在覆盖率为 30%时准确率约 78%,在覆盖率为 100%时准确率约 54%;随机森林模型在覆盖率为 30%时预测准确率为 90.48%,覆盖率为 100%时准确率可达 66.5%;滴滴出行目的地预测系统在覆盖率为 30%时准确率为 90%[25]。因此,随机森林的整体表现要优于朴素贝叶斯模型,与滴滴用户出行目的地预测系统的预测效果持平。#p#分页标题#e#
参考文献(略)

