第一章 绪论
1.1 研究背景与意义
互联网的蓬勃发展使得中文数据信息规模日益庞大,如何有效地利用这些信息成为自然语言处理(Natural Language Processing,NLP)领域的重大挑战。中文词法分析作为自然语言处理的基础研究领域,其研究成果直接影响到后续句法分析研究和语义分析研究的规整度,而且对于有效利用大规模信息进行智能问答、语音识别和机器翻译等具有重要现实意义。
1.1 研究背景与意义
互联网的蓬勃发展使得中文数据信息规模日益庞大,如何有效地利用这些信息成为自然语言处理(Natural Language Processing,NLP)领域的重大挑战。中文词法分析作为自然语言处理的基础研究领域,其研究成果直接影响到后续句法分析研究和语义分析研究的规整度,而且对于有效利用大规模信息进行智能问答、语音识别和机器翻译等具有重要现实意义。
中文词法分析主要分为分词和词性标注两个任务。一般而言,自然语言处理的基本单位是“词语”。但是与外文不同,中文句子的词语之间不存在天然的分隔符,文本中的句子以字串的形式出现。因此对于中文词法分析来说,首要的任务是将句子切分为词语。而词性标注则是赋予分词后的每个词语正确的词性,从而为自然语言处理中的句法分析和语义分析提供支撑[4]。对于中文词法分析来说,分词结果的优劣关系到词性标注的准确性,而词性标注可以为分词结果提供反向校验,因此这两者关系是紧密相连的。
目前中文词法分析已经得到了众多专家学者的研究,不论是分词研究还是词性标注研究都获得了长足的发展,并且取得了不错的成绩。但是近几年来,伴随着计算机处理能力的提升,深度学习神经网络得到飞速发展,目前主流的基于统计的研究方法已经不能够满足该领域发展的需求。利用深度学习神经网络强大的建模能力处理中文词法分析任务成为了学术界研究新热点。
............................
............................
1.2 中文词法分析研究现状
1.2.1 中文分词研究现状
中文分词研究提出于上世界 80 年代,经过三十多年的不断发展,基于词义和规则的方法已经逐渐被基于标注数据的统计方法所取代,后者不仅使得分词结果取得显著提升,而且分词模型也变得更加简单易于理解。尤其是 2003 年国际中文分词公开评测比赛开展以来,中文分词研究吸引了更多研究者的关注。目前来看,中文分词研究方法主要分为词典匹配,标注数据学习和神经网络模型三种方法。
词典匹配一般是将句子与词典中的词条按照特定方向依次进行匹配查找,如果句子中存在该词条则匹配成功,在匹配成功处切分词语。目前研究中经常使用的匹配方法有:正向匹配法、逆向匹配法、最少切分匹配法和双向匹配法。除此之外,词典匹配还可以依赖标志切分,即在句子中识别出明显特征词,依托这些特征词将句子二次划分后再进行匹配。Pi-Chuan Chang 通过基于词典的规则特征信息融合提出考虑文本的出现频率,利用词典特征统计进行分词,显著提高了分词准确率。
1.2.1 中文分词研究现状
中文分词研究提出于上世界 80 年代,经过三十多年的不断发展,基于词义和规则的方法已经逐渐被基于标注数据的统计方法所取代,后者不仅使得分词结果取得显著提升,而且分词模型也变得更加简单易于理解。尤其是 2003 年国际中文分词公开评测比赛开展以来,中文分词研究吸引了更多研究者的关注。目前来看,中文分词研究方法主要分为词典匹配,标注数据学习和神经网络模型三种方法。
词典匹配一般是将句子与词典中的词条按照特定方向依次进行匹配查找,如果句子中存在该词条则匹配成功,在匹配成功处切分词语。目前研究中经常使用的匹配方法有:正向匹配法、逆向匹配法、最少切分匹配法和双向匹配法。除此之外,词典匹配还可以依赖标志切分,即在句子中识别出明显特征词,依托这些特征词将句子二次划分后再进行匹配。Pi-Chuan Chang 通过基于词典的规则特征信息融合提出考虑文本的出现频率,利用词典特征统计进行分词,显著提高了分词准确率。
标注数据学习是充分考虑数据集特性提出的研究方法。互联网信息时代,网页文本中包含大量标记分词边界的标注信息(学术界通常将这种信息称为自然标注),如何应用这些自然标注信息进行分词成为分词领域新的研究方向。2014 年 Yijia Liu 等[26]将包含自然标注信息的文本转化为局部标注数据,加入到模型训练数据中,显著提高了分词效果。随后,研究者们更进一步考虑运用两个句子之间的互信息、句子邻接字的多样性、句子邻接标点符号的频率以及词语出现频率等无标注半指导特征进行分词。如 2015 年韩东煦、常宝宝[9]利用中文的卡方统计量等无标注半指导特征进行跨领域中文分词,准确率比传统词典方法提升了 1.00%。
............................
第二章 中文词法分析相关技术
2.1 深度学习概述
2.1.1深度学习概念
2.1 深度学习概述
2.1.1深度学习概念
深度学习的概念源于人工神经网络的研究,其通过组合低层属性形成更加抽象的高层特征,以发现数据的分布式特征表示[42]。与浅层学习方法不同,深度学习重点强调要有足够的深度,这里的深度来源于流向图。流向图是一种能够表示计算的图,在这种图中从输入节点开始,每一个节点表示一个基本计算,在该节点计算的结果传递到子节点中继续进行运算,如此循环往复直到输出层结束。流向图的最大特点就是输入节点没有父节点,输出节点没有子节点。而深度就是流向图从一个输入到一个输出所经过的最长路径长度。一般深度学习要求具有多层(大于等于 3)隐层节点并且是非线性结构,其次深度学习强调自动学习,能够自动从数据中抽取关键信息,不过分依赖人工特征选取。
2.1.2 深度学习模型基本框架
深度学习是模仿人类大脑神经元结构来进行解决问题的方法,因此对于深度学习来说学习的过程是逐步递进的。通过多层非线性融合,深度学习可以实现多领域的多种任务处理。为了更好地展现深度学习处理任务的算法流程,图 2.1 展示了深度学习模型的基本框架。
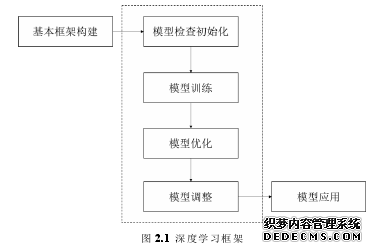
........................
2.2神经网络模型
2.2.1 长短时记忆神经网络模型
循环神经网络(Recurrent Neural Networks,RNN)由于其记忆单元保留历史信息的独特性在 NLP 领域广泛应用,并在 NLP 任务处理中展示了显著效果。相对于传统前馈神经网络,RNN 能够有效利用历史信息,这对于预测当前状态信息非常重要。理论上,RNN能够利用任意长序列的信息,但是由于 RNN 网络结构存在梯度消失或者梯度爆炸问题,因此在实际应用时 RNN 仅能够回溯利用与它接近时间点上的信息。长短时记忆神经网络正是解决这种长距离依赖问题而提出的。一个 LSTM 单元由三个门组成:输入门(input gate),输出门(output gate),遗忘门(forget gate)。图 2.2 展示了 LSTM 的记忆单元结构。
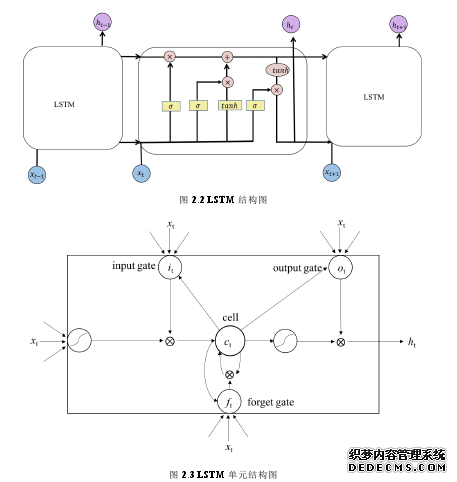
.........................
2.1.2 深度学习模型基本框架
深度学习是模仿人类大脑神经元结构来进行解决问题的方法,因此对于深度学习来说学习的过程是逐步递进的。通过多层非线性融合,深度学习可以实现多领域的多种任务处理。为了更好地展现深度学习处理任务的算法流程,图 2.1 展示了深度学习模型的基本框架。
........................
2.2神经网络模型
2.2.1 长短时记忆神经网络模型
循环神经网络(Recurrent Neural Networks,RNN)由于其记忆单元保留历史信息的独特性在 NLP 领域广泛应用,并在 NLP 任务处理中展示了显著效果。相对于传统前馈神经网络,RNN 能够有效利用历史信息,这对于预测当前状态信息非常重要。理论上,RNN能够利用任意长序列的信息,但是由于 RNN 网络结构存在梯度消失或者梯度爆炸问题,因此在实际应用时 RNN 仅能够回溯利用与它接近时间点上的信息。长短时记忆神经网络正是解决这种长距离依赖问题而提出的。一个 LSTM 单元由三个门组成:输入门(input gate),输出门(output gate),遗忘门(forget gate)。图 2.2 展示了 LSTM 的记忆单元结构。
.........................
3.1 引言......................................... 15
3.2 中文分词标注集选择............................. 15
3.3 双向门控循环神经网络分词模型......................... 16
第四章 基于深度学习的中文词性标注模型............................. 30
4.1 引言...................................... 30
4.2 常用词性标注方法.................................. 30
第五章 歧义词识别与中文词法分析一体化模型.............................. 42
5.1 引言..................................... 42
5.2 歧义词分类......................... 42
5.3 歧义词识别方法及歧义词资源构建......................... 43
第五章 歧义词识别与中文词法分析一体化模型
5.1 引言
在前面的第三章和第四章中,我们介绍了解决中文分词和词性标注的方法-基于双向门控循环神经网络和条件随机场组合模型。而在这两章的实验过程中,我们会遇到因歧义词而导致分词和词性标注错误的情况,经过分析发现组合模型方法对歧义词的处理准确度较低。例如在处理句子“乒乓球拍卖完了”时既可以分词为“乒乓球/拍卖/完了”又可以分词为“乒乓球拍/卖/完了”。此时,“乒乓球”和“乒乓球拍”都有可能用作句子中的独立词,但是两者却可能导致对原始文本完全不同的解释,这样的结果是无法接受的。因此在本章中,将首先对如何正确处理歧义词进行详细说明,其次在解决歧义词问题基础上,考虑建立一体化模型,一体处理分词和词性标注任务。
5.1 引言
在前面的第三章和第四章中,我们介绍了解决中文分词和词性标注的方法-基于双向门控循环神经网络和条件随机场组合模型。而在这两章的实验过程中,我们会遇到因歧义词而导致分词和词性标注错误的情况,经过分析发现组合模型方法对歧义词的处理准确度较低。例如在处理句子“乒乓球拍卖完了”时既可以分词为“乒乓球/拍卖/完了”又可以分词为“乒乓球拍/卖/完了”。此时,“乒乓球”和“乒乓球拍”都有可能用作句子中的独立词,但是两者却可能导致对原始文本完全不同的解释,这样的结果是无法接受的。因此在本章中,将首先对如何正确处理歧义词进行详细说明,其次在解决歧义词问题基础上,考虑建立一体化模型,一体处理分词和词性标注任务。
..........................
第六章 总结与展望
6.1 工作总结
互联网计算机时代的快速发展,带动了大量中文信息的流动,如何更好地利用这些信息提取关键数据成为学术界研究重点。本文根据自然语言处理中的词法分析存在的问题,在分析了中文文本特性和前人研究方法中存在不足的前提下提出了基于深度学习以双向门控逻辑循环神经网络和线性条件随机场组合模型为基准模型的解决方法。本文的主要工作内容以及研究成果如下:
6.1 工作总结
互联网计算机时代的快速发展,带动了大量中文信息的流动,如何更好地利用这些信息提取关键数据成为学术界研究重点。本文根据自然语言处理中的词法分析存在的问题,在分析了中文文本特性和前人研究方法中存在不足的前提下提出了基于深度学习以双向门控逻辑循环神经网络和线性条件随机场组合模型为基准模型的解决方法。本文的主要工作内容以及研究成果如下:
(1)介绍中文词法分析中的两个任务-分词和词性标注,并介绍用于解决分词和词性标注的常用神经网络模型 LSTM、GRU 和 CRF,分析三个模型的内部结构和更新方法。
(2)对现有分词方法进行分析,针对现有方法存在的训练时间长,需要大量人工特征构造,不能有效利用长距离信息等一系列问题,提出了 Bi-GRU+CRF 模型用于分词任务,经过与现有的分词模型方法进行实验对比,尤其是现在主流分词方法 Bi-LSTM+CRF 模型对比:本文提出的 Bi-GRU+CRF 模型不仅 P、R、F 值得到有效提高,而且在保证分词速度的基础上训练速度也得到大幅度提升。#p#分页标题#e#
(2)对现有分词方法进行分析,针对现有方法存在的训练时间长,需要大量人工特征构造,不能有效利用长距离信息等一系列问题,提出了 Bi-GRU+CRF 模型用于分词任务,经过与现有的分词模型方法进行实验对比,尤其是现在主流分词方法 Bi-LSTM+CRF 模型对比:本文提出的 Bi-GRU+CRF 模型不仅 P、R、F 值得到有效提高,而且在保证分词速度的基础上训练速度也得到大幅度提升。#p#分页标题#e#
(3)对词性标注任务进行分析,介绍 HMM 模型处理方法和基于 HMM 改进版的 CRF模型处理方法,指出两种方法存在的依赖人工特征提取的不足之处。由于 Bi-GRU+CRF 模型能够自动获取特征,我们继续在该组合模型基础上进行处理词性标注任务。但是与分词5 个字位标记不同,词性标注有 40 个字位,因此在以 Bi-GRU+CRF 模型为基准模型的基础上,本文提出了预训练向量算法,经过实验对比,使用预训练向量算法后,词性标注准确率和处理速度得到明显提高。
(4)针对研究中文词法分析过程中存在的歧义词识别问题,提出改进模型方案,并提出一体化模型解决分词和词性标注两个任务。对于歧义词测试语料无法外部获取的情况,提出构建歧义词资源方案。经过实验对比:一体化模型在处理歧义词方面和分词,词性标注结果方面都得到了提高。
参考文献(略)

