第一章 绪论
1.1 研究背景和意义
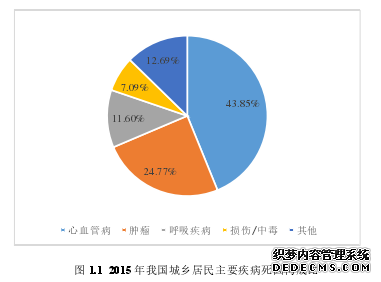
一直以来,我国整体医疗卫生事业都面临着供需失衡、资源紧张等问题,随着社会老龄化程度的不断加深,“看病难,看病贵”愈发成为一项亟待解决的严峻问题[1]。与此同时,公众的健康意识却在不断提升,对健康的追求也从传统的“生病之后去医院”的事后治疗转向事前疾病防控,伴随而来的就是社交圈中养生类话题热度的居高不下和健身行业的蓬勃发展。然而如图 1.1 所示,伴随着现代化条件下不健康的生活方式给人们身体健康状况带来的多种不利影响,心血管病(Cardiovascular Diseases, CVD)近年来在中国的发病率和死亡率却在不断攀升,成为威胁居民健康的头号杀手。近十年以来,我国用在心血管病诊疗上面的费用增速已经远高于 GDP 的增速,且呈现出在低龄化、低收入群体中快速增长及个体聚集的趋势[2]。可以预见,今后 10 年我国心血管患病人数仍将持续快速增长。
1.1 研究背景和意义
一直以来,我国整体医疗卫生事业都面临着供需失衡、资源紧张等问题,随着社会老龄化程度的不断加深,“看病难,看病贵”愈发成为一项亟待解决的严峻问题[1]。与此同时,公众的健康意识却在不断提升,对健康的追求也从传统的“生病之后去医院”的事后治疗转向事前疾病防控,伴随而来的就是社交圈中养生类话题热度的居高不下和健身行业的蓬勃发展。然而如图 1.1 所示,伴随着现代化条件下不健康的生活方式给人们身体健康状况带来的多种不利影响,心血管病(Cardiovascular Diseases, CVD)近年来在中国的发病率和死亡率却在不断攀升,成为威胁居民健康的头号杀手。近十年以来,我国用在心血管病诊疗上面的费用增速已经远高于 GDP 的增速,且呈现出在低龄化、低收入群体中快速增长及个体聚集的趋势[2]。可以预见,今后 10 年我国心血管患病人数仍将持续快速增长。
........................
1.2 国内外研究现状
1.2.1 数据挖掘的研究现状
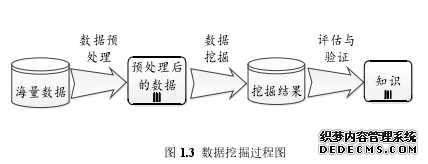
欧美国家针对数据挖掘技术的研究和应用开展比较早,对数据挖掘技术的应用意识也比较高,因此有大量成熟的、稳定可靠的数据挖掘实际应用案例。数据挖掘的过程大致可概括为:数据准备、算法的运行、结果评估与解释[4],具体见图 1.3。
随着大数据时代的到来,对数据挖掘方法的研究也愈发受到重视,以下是几种比较成熟的数据挖掘技术。
(1) 统计分析
统计分析是基于统计学的思想对样本数据集进行分析,从而得出描述该样本集内部规律的信息和知识,具有目的性、数据性、时效性等特点,是最基本的数据挖掘方法之一。
(2) 决策树
决策树是一种类似于流程图的树形结构,其构建过程是基于分裂准则。决策树算法的实现过程是以信息论为理论基础进行特征度量,沿着特征做切分,随着层层递进,数据集的划分会越来越细,最终生成一棵具有分类能力的决策树。
(3) 聚类
大数据领域中的聚类分析,就是对一组不确定的数据根据其属性相似度进行分类,将相似程度较高的数据划为一类,即所谓物以类聚。聚类分析在模式识别、生物学研究、空间数据分析等领域有着广泛的应用[7]。
..............................
第二章 关联分类及特征约简相关理论基础
2.1 关联分类算法论述
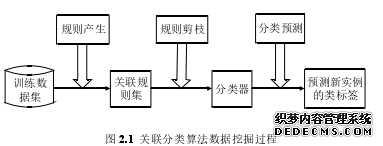
关联分类是关联规则挖掘和分类两种技术的结合,其数据挖掘过程可分为三个阶段,分别是分类关联规则的生成阶段、规则修剪阶段和对未知实例的分类预测阶段[52], 具体流程如图 2.1 所示
目前主流的几种关联分类算法有传统的 CBA 算法、CMAR 算法和 CPAR 算法等,分别代表了关联分类算法的一种研究方向。CBA 算法较好的结合了关联规则挖掘算法和传统分类算法的优点,相较于决策树、神经网络、SVM 等传统的分类算法具有更高的分类精度且分类模型更易理解。另一方面,关联分类算法是基于传统 Apriori 算法挖掘数据样本之间的关联来产生分类规则的,也因此不可避免的继承了 Apriori 关联规则挖掘需要多次扫描数据库、I/O 负载较大的缺点,算法效率不是很理想。与 CBA 算法相比,CMAR 算法的关联规则挖掘过程有所不同,该算法扩展了一种有效的 FP-growth 频繁模式挖掘方法[53],并基于此构建频繁模式树以挖掘关规则,然后采用 CR-树结构来高效地存储和检索所挖掘的关联规则,并在置信度和数据库覆盖技术的基础上进行有效地规则修剪。最后基于对多个强关联规则的?2 分析对未知样本进行分类。CMAR 算法相比 CBA 算法具有更高的算法效率和可扩展性,但是其缺点也很明显,需要更多的内存且分类模型不易理解。另外地,CPAR 算法没有基于候选项集来生成关联规则,而是采用了贪心算法[54]直接从数据集中发现关联规则,避免了系统资源的过度消耗。与另外两种算法相比,CPAR 算法所构造的分类器包含的规则数量更少,但容易出现过拟合问题,分类准确率略有不如。
..........................2.2 数据挖掘中的特征选择
2.2.1 特征选择相关理论
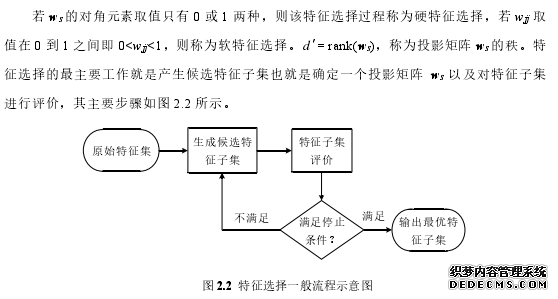
特征选择是一种线性特征约简技术,它从原始的特征全集中选取一个最优的特征子集以满足映射条件。

.......................
第三章 基于分块挖掘和事先剪枝的关联分类算法研究 ....................................22
3.2 关联分类算法改进思想 ...........................22
第四章 基于 Relief F 算法和互信息的特征选择算法研究 ....................................34
4.1 引言 .............................34
4.2 基于 Relief F 算法的特征权重计算 ..............................34
4.3 基于互信息的特征子集生成和修正 .........................36
第五章 改进后的关联分类算法在冠心病诊断中的应用 ..............................44
5.1 引言 ...........................44
5.2 实验环境介绍 ........................................44
第五章 改进后的关联分类算法在冠心病诊断中的应用
5.1 引言
近年来,我国心血管病的患病率与死亡率一直处于持续增长状态,给我国带来了沉重的社会及经济负担,以冠心病、卒中等为代表的心血管疾病已经成为危害民众健康的主要因素。早期研究表明,我国冠心病、卒中的发病规律与欧美国家存在些许差异,受到区域的较大影响,且近年来不同疾病的发病率增长趋势有显著差异。急性冠心病的发病率在持续走高,并且在中青年男性群体中增幅较大。另一方面,冠心病和卒中的病理基础和致病因素有相当大的重合,因此,在已有冠心病医疗数据记录的基础上,借助于关联分类等数据挖掘技术,研究民众罹患冠心病的风险与程度,进而推广到心血管疾病的辅助诊断与发病预警中,有着十分现实的社会作用。
.......................
第六章 总结与展望
6.1 全文工作总结
经济社会的发展伴随着物质条件的不断充裕,现代化条件下不健康的生活方式给人们身体健康带来了多种威胁,以冠心病为代表的心血管病近年来在中国的发病率和死亡率不断攀升,已发展成为重大的公共卫生问题。另一方面,信息技术和物理存储技术的不断发展也使得医疗诊断的手段越发的多样,过程越发的复杂,由此积累了海量的医疗信息。本文的主要任务是探索出一种有效数据挖掘算法对海量的冠心病数据进行挖掘,探究可能引起冠心病的高危因素,进而推广到整个心血管病领域的预防与诊断当中。本文的主要工作如下:
6.1 全文工作总结
经济社会的发展伴随着物质条件的不断充裕,现代化条件下不健康的生活方式给人们身体健康带来了多种威胁,以冠心病为代表的心血管病近年来在中国的发病率和死亡率不断攀升,已发展成为重大的公共卫生问题。另一方面,信息技术和物理存储技术的不断发展也使得医疗诊断的手段越发的多样,过程越发的复杂,由此积累了海量的医疗信息。本文的主要任务是探索出一种有效数据挖掘算法对海量的冠心病数据进行挖掘,探究可能引起冠心病的高危因素,进而推广到整个心血管病领域的预防与诊断当中。本文的主要工作如下:
1、首先阐述了课题研究的必要性与紧迫性,通过查阅大量的中外文献,对医疗健康领域的数据挖掘算法做了研究比较,重点学习了关联分类算法和过滤型特征选择算法的发展历程。
2、对关联分类算法和特征约简算法的相关概念与理论基础进行了系统的学习与研究,探讨了各自的优势与不足,并对工作原理做了深入的探讨与说明,为后文分类模型的构建奠定了理论铺垫。
3、针对原有关联分类算法或是分类准确率不高或是内存占用过大的不足,本文提出了一种基于分块挖掘与事先剪枝的 ACCP 关联分类算法。该算法从基于规则后向约束的分块挖掘与基于最大频繁项集的事先剪枝两个角度避免了无效候选项集的生成,减少了规则挖掘过程中扫描数据库的次数,并且采用改进后的数据库覆盖法对分类规则修剪过程进行了优化,提高了算法运行效率和分类准确率。
2、对关联分类算法和特征约简算法的相关概念与理论基础进行了系统的学习与研究,探讨了各自的优势与不足,并对工作原理做了深入的探讨与说明,为后文分类模型的构建奠定了理论铺垫。
3、针对原有关联分类算法或是分类准确率不高或是内存占用过大的不足,本文提出了一种基于分块挖掘与事先剪枝的 ACCP 关联分类算法。该算法从基于规则后向约束的分块挖掘与基于最大频繁项集的事先剪枝两个角度避免了无效候选项集的生成,减少了规则挖掘过程中扫描数据库的次数,并且采用改进后的数据库覆盖法对分类规则修剪过程进行了优化,提高了算法运行效率和分类准确率。
4、进一步提高分类挖掘效率,针对医疗数据模式多样且数值型特征较多的特点,提出了一种结合了 Relief F 算法与互信息的新的特征选择算法——FSRMI 特征选择算法,并从特征权重计算、特征子集生成、特征子集修正三个阶段对该算法的作用过程做了详细介绍。基于 breast-cancer 标准数据集的实验证明,FSRMI 算法可以有效降低特征集的冗余度,提升数据质量。
参考文献(略)

