第 1 章 绪论
1.1 研究背景
1.1.1 数据挖掘
随着信息技术的飞速发展,可用数据的爆炸式增长和巨大数据量使得我们的时代成为真正的数据时代。因此,如何从这些海量的数据中挖掘出有价值的信息成为众多学者研究的课题之一。数据挖掘(Data Ming, DM)是数据库知识发现(Knowledge Discover in Database, KDD)中的一个重要步骤,用来从大量的、随机的、模糊的、有噪声的数据中挖掘出用户感兴趣的、有价值的模式的过程[1,2]。图 1-1 大致描述了数据挖掘的系统框架。
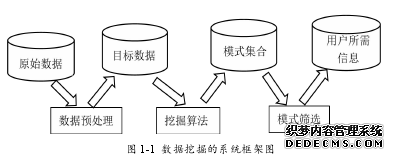
利用数据挖掘技术可以进行预测、估计、分类、聚类、关联规则分析等方面[1],目前数据挖掘研究的课题有:频繁项集挖掘、关联规则挖掘、高效用项集挖掘、序列模式挖掘以及共现项的挖掘[7]等等。因此,数据挖掘在现实生活中应用非常广泛,主要有市场分析和管理、风险分析和管理、欺骗检测和异常模式的监测(孤立点)、文本挖掘(新闻组、电子邮件、文档)和 WEB 挖掘、流数据挖掘。
频繁项集挖掘(Frequent Itemsets Mining, FIM)(或关联规则挖掘(AssociationRule Mining, ARM))和高效用项集挖掘是目前数据挖掘中最重要和常见的任务,是数据挖掘的众多知识类型中最为典型的,因为它们满足众多领域和应用的要求。通过关联规则挖掘我们可以揭示和发现大量数据之间隐含的、有趣的关系,这对一些决策者来说可以帮助他们制定更好的营销策略和商业决定,而频繁项集挖掘由于其简单性和高效性而被用作代表关联规则的挖掘方法。而高效用项集挖掘是频繁项集挖掘的一个扩展,可以进一步帮助决策者如何获得更的利润。
..............................
1.2 研究目的及意义
FIM 是一种流行的数据挖掘任务,可以发现存在大量数据之间隐含的有价值的信息,但是 FIM 只衡量了项集的出现频次。而在现实生活中,项集的出现频次所提供的信息对一些决策者来说,往往是不充分的。因为它并未没有考虑每个项所拥有的其它重要的因素,如权重、单位利润、成本、风险等,而这些因素在一些商业决策中往往扮演者重要的作用。因此,一些学者进一步提出了基于效用挖掘的框架,即高效用项集挖掘。刚开始高效用项集的挖掘都是采用单一效用阈值挖掘的方法,但是这种方法没有考虑项之间的差异,这在现实生活中是不适当的和不公平的。为了解决这个问题,又有人提出了多最小效用阈值挖掘算法,以达到对不同项进行公平地挖掘高效用项集。目前,多最小效用阈值的高效用项集挖掘,已经得到了广泛的关注。但是现有的多最小效用阈值的高效用项集挖掘算法在实际应用过程中仍然会受到许多外部因素的限制,并存在一些不足和挑战,如下所述:
(1)如何扩大多最小效用阈值的高效用项集挖掘算法的应用范围和提高挖掘效率。在现实生活中,随着社会的发展,数据的产生量呈爆炸式增长。而现有的多最小效用阈值高效用项集挖掘算法随着需要处理的数据越来越多,搜索空间往往呈指数级增长,浪费了大量的存储空间,降低了挖掘效率。因此,有必要提出更有效的挖掘算法,来解决从大量的数据中挖掘出高效用项集的问题。
(2)如何根据不同的用户需求,制定出更合理的知识表达方式。以购物篮分析为例,频繁性项集挖掘算法的应用可以帮助商家发现哪些商品在一起被频繁的购买。而高效用项集挖掘算法,可以帮助商家发现哪些商品可以给商家带来更大的利润。而如果商家想要知道哪些商品既可以被频繁的购买又可以带来更高的利润,传统的频繁项集挖掘算法或者高效用项集挖掘算法都不能解决这个问题。因此,有必要制定一个新型的项集模式来挖掘出既是频繁项集又是高效用项集。
(3)如何制定合适的挖掘方案,从进行分类处理的数据库中挖掘高效用项集。目前,高效用项集挖掘算法主要有单一效用阈值和多最小效用阈值两种。但是这两类算法对现实生活中需要分类处理的物品来说都不太合适。采用单一效用阈值没有考虑项之间的差异,把所有项看成同等重要,在实际生活中显然是不适当和不公平的;而采用多最小效用阈值对每个项都进行赋值,如果当数据库中项的数量很多但项的种类很少时,这时再对每一项都进行赋值,显然也是不合适的。因此,有必要定义一种更合适的高效用挖掘方法来解决这个问题。
............................
第 2 章 相关研究现状
2.1 频繁项集挖掘
2.1.1 研究现状
关联规则挖掘是数据挖掘研究的热点之一,近年来得到了广泛的应用和研究。作为关联规则挖掘中最重要一步的频繁项集挖掘在数据挖掘挖掘领域中有着举足轻重的地位。到目前为止,已经提出了大量的挖掘算法,其中,Apriori 算法和FP-Growth 算法是最典型的两个频繁项集挖掘算法,在这两个算法提出之后,频繁项集挖掘得到了更为广泛的研究,越来越多的算法被提出,主要有两大类:
2.1.1 研究现状
关联规则挖掘是数据挖掘研究的热点之一,近年来得到了广泛的应用和研究。作为关联规则挖掘中最重要一步的频繁项集挖掘在数据挖掘挖掘领域中有着举足轻重的地位。到目前为止,已经提出了大量的挖掘算法,其中,Apriori 算法和FP-Growth 算法是最典型的两个频繁项集挖掘算法,在这两个算法提出之后,频繁项集挖掘得到了更为广泛的研究,越来越多的算法被提出,主要有两大类:
(1)类似 Apriori 算法:有候选项集产生的方法。这类算法利用反单调性(也称先验性质)来剪枝搜索空间(即:如果一个项或者项集不是频繁的,那么它的所有超集也不是频繁项集[5]。),代表算法有文献[5,34-36]等等。这类算法的缺点是:需要很大的花销来维护产生的大量候选项集,并且需要多次扫描数据库。
(2)类似 FP-growth 算法:使用模式增长的方法。这类方法通过将关于频繁项集的重要信息存储到一个特殊的数据结构上,避免了候选项集的产生和多次扫描数据库。代表算法有文献[3,37,38]等。但是,这类算法也存在一些不足:一是在稀疏数据库中采用这种结构是低效率的;二是构建的数据结构是复杂的。最近几年,又提出了几种基于前缀树的数据结构来存储频繁项集的重要信息,如:Node-list结构[39]、N-list 结构[40]、Nodeset 结构[41]、DiffNodeset[42]以及 NegNodeset 结构[43]等来进一步提高挖掘效率。
(2)类似 FP-growth 算法:使用模式增长的方法。这类方法通过将关于频繁项集的重要信息存储到一个特殊的数据结构上,避免了候选项集的产生和多次扫描数据库。代表算法有文献[3,37,38]等。但是,这类算法也存在一些不足:一是在稀疏数据库中采用这种结构是低效率的;二是构建的数据结构是复杂的。最近几年,又提出了几种基于前缀树的数据结构来存储频繁项集的重要信息,如:Node-list结构[39]、N-list 结构[40]、Nodeset 结构[41]、DiffNodeset[42]以及 NegNodeset 结构[43]等来进一步提高挖掘效率。
除了单一支持度约束的频繁项集挖掘算法外,多最小支持度阈值的模式挖掘问题已经也已经得到广泛研究,其主要思想是通过为每个项分配指定的最小项支持度阈值(minimum item supports threshold, MIS),可以在不生成大量无意义规则的情况下发现稀有的频繁项集或者关联规则。目前为止,已经有大量的挖掘算法被提出,如前面提到的 MSApriori, CFP-Growth, CFP-Growth++, FP-ME, FQSP-MMS等等,这几个算法除了 MSApriori 算法是基于 Apriori 算法的,其余的都是基于FP-Growth 算法。MSApriori 算法[12]是 Apriori 算法的一个扩展,它通过考虑多最小支持度阈值来挖掘频繁项集和关联规则。另外 MSApriori 以一种逐层(level-wise)搜索的方式挖掘关联规则,但是由于它依赖于生成—测试的方法,因此遇到了“模式爆炸”的问题[12]。
............................
第 3 章 多最小效用阈值的频繁高效用项集快速挖掘算法....................................... 19............................
2.2 高效用项集挖掘
高效用项集挖掘是数据挖掘领域内的一个重要研究方向,是频繁项集挖掘的一个延伸。它比频繁项集挖掘更具有实践意义,可以帮助决策者或者管理者制定更有效的策略。在效用挖掘中,每一个项有一个效用值并且项在每一个事务中出现的次数可以超过一次。根据在不同的应用中,这个效用的度量可以是一个项的单位价钱、利润、成本等。因此,高效用项集挖掘考虑了项的数量和单位效用来衡量一个项集的“有用性”。一个项集的效用值不低于用户设定的最小效用阈值,那么这个项集就是高效用的,高效用项集挖掘的目的就是挖掘出所有能带来高效用值的项集。
2.2.1 高效用项集挖掘:单一效用阈值
高效用项集挖掘是数据挖掘领域内的一个重要研究方向,是频繁项集挖掘的一个延伸。它比频繁项集挖掘更具有实践意义,可以帮助决策者或者管理者制定更有效的策略。在效用挖掘中,每一个项有一个效用值并且项在每一个事务中出现的次数可以超过一次。根据在不同的应用中,这个效用的度量可以是一个项的单位价钱、利润、成本等。因此,高效用项集挖掘考虑了项的数量和单位效用来衡量一个项集的“有用性”。一个项集的效用值不低于用户设定的最小效用阈值,那么这个项集就是高效用的,高效用项集挖掘的目的就是挖掘出所有能带来高效用值的项集。
2.2.1 高效用项集挖掘:单一效用阈值
HUI 挖掘是过去十年中最活跃的研究课题之一。这个问题最初由 chan 等人提出,以解决关联规则挖掘中经常使用的基于支持度框架的关键限制。随着高效用项集挖掘算法的广泛应用,到目前为止已经有大量的挖掘算法被提出。主要有以下几大类:
(一)基于两阶段的高效用项集挖掘算法,其遵循水平方向的候选生成和测试方法。Liu 等提出的一个两阶段(Two-Phase)算法,其中包含事务权重效用 TWU和事务效用 TU 的概念[17],用来剪枝高效用项集挖掘的搜索空间。算法的挖掘过程是:在第一阶段,算法挖掘所有高事务权重效用项集(HTWUI)。然后,在第二阶段,计算项集的实际效用,并过滤掉非 HUI。其它相关的水平挖掘方法有:UMining和 UMining_H[47],FUM 和 DCG +[48]等。尽管这类算法可以减少效用挖掘的搜索空间,但是仍然存在以下问题:
(一)基于两阶段的高效用项集挖掘算法,其遵循水平方向的候选生成和测试方法。Liu 等提出的一个两阶段(Two-Phase)算法,其中包含事务权重效用 TWU和事务效用 TU 的概念[17],用来剪枝高效用项集挖掘的搜索空间。算法的挖掘过程是:在第一阶段,算法挖掘所有高事务权重效用项集(HTWUI)。然后,在第二阶段,计算项集的实际效用,并过滤掉非 HUI。其它相关的水平挖掘方法有:UMining和 UMining_H[47],FUM 和 DCG +[48]等。尽管这类算法可以减少效用挖掘的搜索空间,但是仍然存在以下问题:
(1)像 Apriori 算法一样可能有大量的候选项集产生。
(2)需要多次扫描数据库。#p#分页标题#e#
(3)项集的 TWU 通常比它的效用值高很多。导致挖掘效率低下,内存消耗严重。
(2)需要多次扫描数据库。#p#分页标题#e#
(3)项集的 TWU 通常比它的效用值高很多。导致挖掘效率低下,内存消耗严重。
(二)基于模式树的高效用挖掘算法。对于大型或密集数据集,逐层搜索算法不能很好地扩展。为了解决大量的候选项集产生的问题,许多学者提出了基于树的高效用项集挖掘算法,展现了更好的挖掘性能。这些算法主要包括 IHUP[22],HUC-Prune[23], UP-Growth[24]和 UP-Growth+[25]。这类算法的挖掘过程是:首先,将待挖掘的数据库转换为前缀树,并且树中保留了有关项集的效用信息;其次,对于树中的每个项,如果估计它是有价值的,即可能存在该包含该项的高效用项集,也就是 TWU 值不低于用户设置最小效用阈值 minutil 的项,则算法为该项构造条件前缀树;第三,算法递归地处理所有条件前缀树来生成候选高效用项集;最后,算法通过再次扫描数据库计算出所有候选项集的实际效用。通过减少数据库扫描次数和候选项集的数量,使得算法的性能优于基于 Apriori 的算法。即使如此,与所得到的高效用项目集的数量相比,这些算法在大多数情况下仍然生成大量候选项集,并且生成这些候选项集并计算它们的实际效用是非常昂贵的。
............................
3.1 预备知识和问题陈述.................................... 19
3.1.1 多最小效用阈值挖掘算法............................... 19
3.1.2 主要定义及问题陈述................................... 21
第 4 章 同类项的多最小效用阈值的频繁高效用项集挖掘算法............................... 41
4.1 问题分析和相关概念................................... 41
4.1.1 问题分析.................................... 41
4.1.2 同类项相关概念........................... 42
第 5 章 总结和展望............................... 57
5.1 总结.................................... 57
5.2 展望........................... 57
第 4 章 同类项的多最小效用阈值的频繁高效用项集挖掘算法
4.1 问题分析和相关概念
4.1.1 问题分析
通过前面的介绍可知,高效用项集挖掘(HUIM)在数据挖掘领域中扮演着越来越重要的角色,应用范围越来越广。它解决了传统的频繁项集挖掘算法不考虑项的购买数量和不考虑项的单位利润的问题。目前,高效用项集挖掘算法已经得到广泛的研究,按效用阈值分类主要有:单一效用阈值和多最小效用阈值两种。但是这两类算法对现实生活中需要分类处理的物品来说都不太合适。采用单一效用阈值没有考虑项之间的差异,把所有项看成同等重要,在现实生活中显然是不适当和不公平的;而采用多最小效用阈值对每个项都进行赋值,当数据库中项的数量很多但项的种类很少时,这时再对每一项都进行赋值,显然也是不合适的。比如,在一家大型超市中,商品的数量大,但是有很多都属于同一类(如:红茶、绿茶、青茶和白茶等属于茶类,面包、奶酪和汉堡是一类,等等),如果对每一项都进行赋最小阈值,在实际的工作中会增大工作量,降低工作效率。
因此,在以上两类算法的基础上进一步提出分类的思想,通过对每一类赋最小效用阈值,既考虑了不同类商品之间的差异,又减少了同类商品重复赋值的问题。而单一效用阈值的高效用项集挖掘和多最小效用阈值的高效用项集挖掘都可以看成是分类的多最小效用阈值的高效用项集挖掘的特殊情况,当数据库中的所有项属于同一类时就采用单一效用阈值挖掘,而当数据库中的项都是不同类时就采用多最小效用阈值挖掘。因此,研究基于分类的多最小效用的高效用项集挖掘算法是有必要的。
另外,为了保证挖掘的高效用项集的频繁性,又加上了支持度约束条件,使得挖掘的高效用项集也是频繁项集。这样的项集可以帮助商场决策者制定更好的销售策略,既能保证商品在一起销售的频数又能保证得到更多的利润。
...........................
第 5 章 总结和展望
5.1 总结
通过学习分析现有的频繁项集和高效用项集挖掘算法的研究成果,提出了几个改进的算法,以下是本文所做的主要工作:
1. 交代了本文研究背景和国内外研究现状,分析了现有算法的优点和不足,着重介绍了多最小效用阈值的高效用项集挖掘算法。针对多最小效用阈值挖掘算法(MHUI 算法)中存在的重复计算问题,做了以下工作:
5.1 总结
通过学习分析现有的频繁项集和高效用项集挖掘算法的研究成果,提出了几个改进的算法,以下是本文所做的主要工作:
1. 交代了本文研究背景和国内外研究现状,分析了现有算法的优点和不足,着重介绍了多最小效用阈值的高效用项集挖掘算法。针对多最小效用阈值挖掘算法(MHUI 算法)中存在的重复计算问题,做了以下工作:
(1)重新定义项集的最小效用阈值的计算方法,避免求项集的最小效用阈值时出现重复计算。
(2)定义所有项的扩展项的最小效用阈值表 EMMU-Table,避免了求项集的扩展项的最小效用阈值时出现重复计算。
(3)定义一个全局最小效用阈值 GMU,并结合 EMMU-Table 提高了算法的运行效率。结合以上工作提出了改进的 FMHUI 算法,为了使挖掘的项集是频繁项集又提出了 SFMHUI 算法,保证了项集的频繁性。
2. 提出了从分类的数据库中挖掘频繁高效用项集的算法—CMFHUI 算法。CMFHUI 算法对每一类赋最小效用阈值来挖掘高效用项集,并通过设置一个最小支持度阈值来保证挖掘的项集是频繁项集。后来为了进一步提高挖掘效率又提出了改进的 CMFHUI+算法。最后通过仿真实验得到了验证。
(2)定义所有项的扩展项的最小效用阈值表 EMMU-Table,避免了求项集的扩展项的最小效用阈值时出现重复计算。
(3)定义一个全局最小效用阈值 GMU,并结合 EMMU-Table 提高了算法的运行效率。结合以上工作提出了改进的 FMHUI 算法,为了使挖掘的项集是频繁项集又提出了 SFMHUI 算法,保证了项集的频繁性。
2. 提出了从分类的数据库中挖掘频繁高效用项集的算法—CMFHUI 算法。CMFHUI 算法对每一类赋最小效用阈值来挖掘高效用项集,并通过设置一个最小支持度阈值来保证挖掘的项集是频繁项集。后来为了进一步提高挖掘效率又提出了改进的 CMFHUI+算法。最后通过仿真实验得到了验证。
本文提出的算法解决了频繁项集和多最小效用阈值的高效用项集挖掘中的不足,通过实验验证了提出算法的有效性和可行性。但是,这些算法尚有改进空间,如:
(1)FMHUI 算法和 SFMHUI 算法在内存消耗方面没有明显的减少。
(2)CMFHUI 算法和 CMFHUI+算法中类最小效用阈值的设置较简单。这些都需要我们进一步研究。
参考文献(略)
(2)CMFHUI 算法和 CMFHUI+算法中类最小效用阈值的设置较简单。这些都需要我们进一步研究。
参考文献(略)

