第 1 章 绪论
1.1 课题研究背景及意义
近年来,互联网一直都在迅速的发展着,网络对我们的生活、工作和学习越来越变得不可缺少。它使我们的工作更有效率,学习更加方便,生活也更有质量。在现今这个互联网高速发展的时代,基本上我们每天都要在在网络上都做许多的事情,比如在电商平台购买物品,在网站上进行学习或观看视频,收发电子邮件等。网络确实给我们的生活带来了许多方便的地方。比如在各个网站上的推荐系统,它会根据我们在网上的历史信息以及兴趣爱好等,给我们个性化的推荐商品、资源和服务等。现在可以上网的手段越来越多,不仅局限于电脑,还包括手机,pad,电视以及各种智能终端等等,但是我们在使用网络的过程可能会产生大量的数据,这些数据都是自动被储存下来的。而且这些数据随着时间的增加不会减少,也是一直在叠加的。这些数据里边不仅有一些文字方面数据,还有图形,视频,声音等,这些数据的存储和加工都是在网络中进行的。海量数据的存储与加工对计算机技术提出了更高的要求,在这种情况下,云计算应运而生,而计算机技术进入了大数据时代[1]。
1.1 课题研究背景及意义
近年来,互联网一直都在迅速的发展着,网络对我们的生活、工作和学习越来越变得不可缺少。它使我们的工作更有效率,学习更加方便,生活也更有质量。在现今这个互联网高速发展的时代,基本上我们每天都要在在网络上都做许多的事情,比如在电商平台购买物品,在网站上进行学习或观看视频,收发电子邮件等。网络确实给我们的生活带来了许多方便的地方。比如在各个网站上的推荐系统,它会根据我们在网上的历史信息以及兴趣爱好等,给我们个性化的推荐商品、资源和服务等。现在可以上网的手段越来越多,不仅局限于电脑,还包括手机,pad,电视以及各种智能终端等等,但是我们在使用网络的过程可能会产生大量的数据,这些数据都是自动被储存下来的。而且这些数据随着时间的增加不会减少,也是一直在叠加的。这些数据里边不仅有一些文字方面数据,还有图形,视频,声音等,这些数据的存储和加工都是在网络中进行的。海量数据的存储与加工对计算机技术提出了更高的要求,在这种情况下,云计算应运而生,而计算机技术进入了大数据时代[1]。
云计算从提出到现在,依然备受关注。国内外许多企业都一直致力于云计算的发展和研究,比如亚马逊和微软等,他们先后加入对云计算研究的行列,这些对加快云计算的发展和应用具有重要的意义。云计算其实就是资源提供者将资源虚拟化后,在网络中作为一种服务提供给用户的计算模式,与此同时,用户不会去关心具体的基本设计还有设计的过程,他们只会根据自己需要什么去申请相应的云服务即可。云计算是大数据处理的一种解决途径。随着数据量的不断增加,要想保证服务的时间,就要提高服务器的性能。而提高单个服务器的性能成本与造价实在是太高。因此云计算所采用了分而治之的思想,利用现有的廉价的计算机搭建服务器集群,把数据划分成多个较小的板块,分别让集群对这些任务进行处理,处理之后在对这些各个小结果进行汇总,并根据用户的需求生成最终的结果。这样就不仅缩短了响应时间,也降低了研究成本。MapReduce 就是一个这样的计算框架。
...............................
1.2 国内外研究现状
1.2.1 小作业的研究现状
MapReduce 对作业进行安排的方法对集群这一性能影响是很大的。这种性能主要通过下面五个指标来衡量:首先就是在公平方面,也就只能是分配给用户资源的一个公平性还有合理性;其次就是在数据方面,看数据在对应的任务安排点上完成率的高低。然后就在调度的时间方面,根据花费的时间来判断具体的效果。最后就是在调度的算法方面看能不能满足用户的最低需求。但是这些性能又是相辅相成的,它们不可分割。提高一个性能可能会导致其他性能的下降,也就是鱼和熊掌不可兼得。所以一般情况下,我们对于这种算法,进行提升的目标就是指的提升某一项或者某几项性能,但是想要计算一个作业完成的平均时间,确实每种方法都要考虑到的,每种性能都要考虑到的。
前面的很多研究者为了让系统的性能更加完善,针对具体的作业算法进行了大量的研究,进行了大量数据的测试,最终一直在改进。其中很多部分都是针对 MapReduce 这种作业调度过程中的 Map 任务的优化和改进,但是对 Reduce研究就会少很多算法方面也会简单不少,所以存在一些不足,包括小作业还有“饥饿”(小作业执行效率不高)和系统资源利用率不高的问题,另一方面是数据倾斜的方面。关于 Reduce 任务来说,小作业在执行的时候可能会受到一定的干扰。因为大作业一直在占着资源而执行不了。 对于小作业的定义来说,之所以叫小做,也是因为他的执行时间是很短的,有可能几分钟,几十分钟就完成了。比如我们常用的淘宝中就会经常执行小作业,来完成每一个任务,因为浏览量和运行量比较大每天可能要运行上万个甚至数 10 万个小作业。所以一定要提高小作业的执行效率,才能够保证很多正常程序的运行。有学者对淘宝的云梯作业进行了深入的分析和了解,发现了小作业中的执行效率不够高也不够集中。所以提出了一些改进的算法,但是这些算法可能也会有一定的弊端,比如说没有考虑到饥饿问题。所以为了进一步完善该问题,Jian Tan 在该基础上,提出了进一步的加快任务的速度来进行进一步的完善,但是这种算法却没有考虑到任务完成的时间。还有学者在后边提出了在任务上尽快缩短剩余时间的一种改进算法,这种算法也是有弊端的,在一些情况下可能会导致系统的某些资源得不到合适的利用。所以对于算法和调度来说,有必要进行深入和专业的研究,研究出一套最适合的,最完整的算法。
第 3 章 基于时间的 Reduce 任务调度...............................26...............................
1.2 国内外研究现状
1.2.1 小作业的研究现状
MapReduce 对作业进行安排的方法对集群这一性能影响是很大的。这种性能主要通过下面五个指标来衡量:首先就是在公平方面,也就只能是分配给用户资源的一个公平性还有合理性;其次就是在数据方面,看数据在对应的任务安排点上完成率的高低。然后就在调度的时间方面,根据花费的时间来判断具体的效果。最后就是在调度的算法方面看能不能满足用户的最低需求。但是这些性能又是相辅相成的,它们不可分割。提高一个性能可能会导致其他性能的下降,也就是鱼和熊掌不可兼得。所以一般情况下,我们对于这种算法,进行提升的目标就是指的提升某一项或者某几项性能,但是想要计算一个作业完成的平均时间,确实每种方法都要考虑到的,每种性能都要考虑到的。
前面的很多研究者为了让系统的性能更加完善,针对具体的作业算法进行了大量的研究,进行了大量数据的测试,最终一直在改进。其中很多部分都是针对 MapReduce 这种作业调度过程中的 Map 任务的优化和改进,但是对 Reduce研究就会少很多算法方面也会简单不少,所以存在一些不足,包括小作业还有“饥饿”(小作业执行效率不高)和系统资源利用率不高的问题,另一方面是数据倾斜的方面。关于 Reduce 任务来说,小作业在执行的时候可能会受到一定的干扰。因为大作业一直在占着资源而执行不了。 对于小作业的定义来说,之所以叫小做,也是因为他的执行时间是很短的,有可能几分钟,几十分钟就完成了。比如我们常用的淘宝中就会经常执行小作业,来完成每一个任务,因为浏览量和运行量比较大每天可能要运行上万个甚至数 10 万个小作业。所以一定要提高小作业的执行效率,才能够保证很多正常程序的运行。有学者对淘宝的云梯作业进行了深入的分析和了解,发现了小作业中的执行效率不够高也不够集中。所以提出了一些改进的算法,但是这些算法可能也会有一定的弊端,比如说没有考虑到饥饿问题。所以为了进一步完善该问题,Jian Tan 在该基础上,提出了进一步的加快任务的速度来进行进一步的完善,但是这种算法却没有考虑到任务完成的时间。还有学者在后边提出了在任务上尽快缩短剩余时间的一种改进算法,这种算法也是有弊端的,在一些情况下可能会导致系统的某些资源得不到合适的利用。所以对于算法和调度来说,有必要进行深入和专业的研究,研究出一套最适合的,最完整的算法。
..............................
第 2 章 Hadoop 相关技术
第 2 章 Hadoop 相关技术
2.1 云计算技术
2.1.1 云计算概念
云计算最早的概念是在 06 年的一个搜索大会上被谷歌的首席执行官提出来的。这个名词当时提出来,引起了不小的轰动,社会各界迅速的引起广泛的关注,因为它不仅仅是一项计算技术,更是在互联网遍及时代一种新的商业模式。掌握了这种模式的较高水平,可能也就掌握了发展的核心和未来。所以这种模式得到了广泛的研究和学习,是很多传统技术共同发展的一个演化的产物。但是目前对于该计算定义没有明确的定义,有比较权威的解释,比如下面几点。
2.1.1 云计算概念
云计算最早的概念是在 06 年的一个搜索大会上被谷歌的首席执行官提出来的。这个名词当时提出来,引起了不小的轰动,社会各界迅速的引起广泛的关注,因为它不仅仅是一项计算技术,更是在互联网遍及时代一种新的商业模式。掌握了这种模式的较高水平,可能也就掌握了发展的核心和未来。所以这种模式得到了广泛的研究和学习,是很多传统技术共同发展的一个演化的产物。但是目前对于该计算定义没有明确的定义,有比较权威的解释,比如下面几点。
(1)Berkely 大学认为是:云计算其实是一种全新的商业模式,是一种计算模式。把计算的任务分配到相关的计算设备中去,形成一个巨大的资源库。云计算的使用用户就可以根据自己的需求从资源库中调出自己所需要的资源,来提供足够的信息服务。
(2)从维基百科我们查到的概念就是:云计算服务的用户主要指的是对于计算提供的服务并不了解的客户,他们没有一些实际的技术支撑,也没有相关的软件知识和能力。所以为他们提供一些基础的服务,让他们能够有足够的储存,还有一个计算的能力。
(2)从维基百科我们查到的概念就是:云计算服务的用户主要指的是对于计算提供的服务并不了解的客户,他们没有一些实际的技术支撑,也没有相关的软件知识和能力。所以为他们提供一些基础的服务,让他们能够有足够的储存,还有一个计算的能力。
(3)IBM 的技术白皮书对于云计算的概念,主要是指云计算是一个系统的平台,或者说是这一类的应用的程序。根据当地的需求进行一个动态的分配和部署。然后及时的进行调整和解决问题。它也算是一个虚拟的网络服务方面的系统。
(4)对云计算的定义,中国云计算网定义的是如下:云计算指的是一种传统的分布式的计算,包括计算能力,还有网络的发展和推进都有很大的影响。或者说是比较商业的一种模式来实现这些比较科学的概念。
(5)NIST(美国国家标准技术研究所)将云计算定义为:云计算虽然是一种计算模式,但是他是给用户是带来方便的一种计算模式,所以要让用户随时需要的时候就能够随时通过网络对于资源进行访问,包括计算的一些设备,还有需要的应用程序等。在这种情况下,能最大程度上的提供合理的服务。
但是,云计算又是在不断的发展和完善的,所以这些相关的服务和定义也是会随着时间而进一步的加强和完善的。会变得更加方便,便捷,用户的体验会更好。
...............................
(4)对云计算的定义,中国云计算网定义的是如下:云计算指的是一种传统的分布式的计算,包括计算能力,还有网络的发展和推进都有很大的影响。或者说是比较商业的一种模式来实现这些比较科学的概念。
(5)NIST(美国国家标准技术研究所)将云计算定义为:云计算虽然是一种计算模式,但是他是给用户是带来方便的一种计算模式,所以要让用户随时需要的时候就能够随时通过网络对于资源进行访问,包括计算的一些设备,还有需要的应用程序等。在这种情况下,能最大程度上的提供合理的服务。
但是,云计算又是在不断的发展和完善的,所以这些相关的服务和定义也是会随着时间而进一步的加强和完善的。会变得更加方便,便捷,用户的体验会更好。
...............................
2.2 Hadoop 平台
2.2.1 Hadoop 简介
在 2005 年, Hadoop 得到了 Apache 企业的引入,经过不断发展逐渐形成的一个分布式系统架构。由于得到了Google 公司 Map Reduce 模型的启发,Hadoop得以成功构建。在 2003 年-2004 年,Google 公司一共发布了三篇技术论文,分别了GFS( System File Google )、Map Reduce 以及 Big Table ,后来,通过这三篇技术论文, Cutting Doug 实现了DFS(分布式文件系统)以及 Map Reduce 机制。到了2006 年,在 Hadoop 中引入 Map Reduce ,从此, Hadoop 发展成分析数据与处理数据的一个重要计算框架。
2.2.1 Hadoop 简介
在 2005 年, Hadoop 得到了 Apache 企业的引入,经过不断发展逐渐形成的一个分布式系统架构。由于得到了Google 公司 Map Reduce 模型的启发,Hadoop得以成功构建。在 2003 年-2004 年,Google 公司一共发布了三篇技术论文,分别了GFS( System File Google )、Map Reduce 以及 Big Table ,后来,通过这三篇技术论文, Cutting Doug 实现了DFS(分布式文件系统)以及 Map Reduce 机制。到了2006 年,在 Hadoop 中引入 Map Reduce ,从此, Hadoop 发展成分析数据与处理数据的一个重要计算框架。
Hadoop 具备很多优点。即使是对性能并不高的集群而言,Hadoop 同样能够运行并实现大规模数据处理,如此,即使用户不进行硬件更改,同样可以满足不同节点的内存以及存储空间,从而使整个集群的利用率得到最大程度的发挥。Hadoop 属于一种分布式系统结构,其操作具备简单性和便捷性,对用户而言,无需掌握底层的全部细节,也可以按照自己的需求来开发分布式应用程序,且其存储能力以及数据处理能力都非常强。Hadoop 主要利用 Map 函数和Reduce函数来实现数据分析以及数据处理,对适用于 Map Reduce 编程任务的模型而言,通过 Hadoop 可以进一步降低集群设备配置的要求。按照自己的需求来对数据进行自动的调整,对于部分暂时没有用到的节点进行关闭操作。同时, Hadoop 还可以自动处理节点故障,如果检测到任务不成功,那么可以在另外处于空闲状态的节点上重启任务,如此,不仅可以有效确保数据处理的准确性,同时还可以提高数据处理的完整性。#p#分页标题#e#
2.2.2 Hadoop 的生态系统
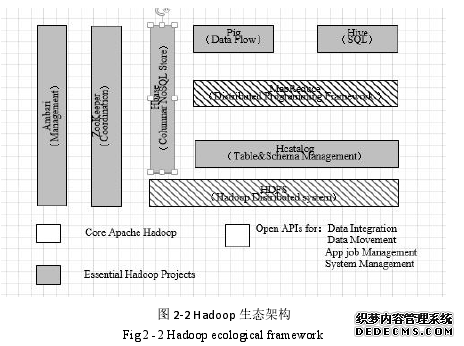
Apache 的 Hadoop 属于一套系统平台,同时在该项目中还包括其它的子项目。整个项目所有子项目组成的生态系统如下图 2-2 所示。其中,HDFS文件存储系统以及 Map Reduce 数据处理模型是非常重要的部分。 Ambari不仅协助管理人员进行 Hadoop 的配置以及部署工作,同时还提供监控服务以及升级集群服务。Zoo Keeper 和协调器非常相似,由于 Hadoop 的成员不断增多,利用 Zoo Keeper 功能,其他成员可以实现服务和配置的同步工作。以下详细介绍它们。
..........................
Apache 的 Hadoop 属于一套系统平台,同时在该项目中还包括其它的子项目。整个项目所有子项目组成的生态系统如下图 2-2 所示。其中,HDFS文件存储系统以及 Map Reduce 数据处理模型是非常重要的部分。 Ambari不仅协助管理人员进行 Hadoop 的配置以及部署工作,同时还提供监控服务以及升级集群服务。Zoo Keeper 和协调器非常相似,由于 Hadoop 的成员不断增多,利用 Zoo Keeper 功能,其他成员可以实现服务和配置的同步工作。以下详细介绍它们。
..........................
3.1 MapReduce 的执行过程..................................26
3.2 小作业的 Reduce“饥饿”问题...................................27
3.3 基于时间的 Reduce 任务调度...........................29
第 4 章 基于抽样与贪心算法的负载均衡..........................32
4.1 MapReduce 的数据倾斜问题................................32
4.2 抽样估计........................34
第 5 章 实验结果与分析..................................41
5.1 实验环境的搭建.......................................41
5.1.1 环境配置..........................41
5.1.2 软硬件环境......................41
第 5 章 实验结果与分析
5.1 实验环境的搭建
5.1.1 环境配置
就集群视角而言,可将 Hadoop 划分为两种不同的角色:其一,Slave;其二,Master。若就存储数据视角而言,HDFS集群则是通过以下节点所形成的:即一个 NameNode节点以及数个DataNode节点。主节点为 NameNode,其最关键的一个在于对元数据信息进行储存; DataNode的关键功能在于对集群中的数据进行储存。 Map Reduce 框架有以下两部分所形成:其一, r TaskTracke ;其二,Job Tracker。Job Tracker独立地在主节点运行,而 r TaskTracke 则主要在各个从节点运行。主节点主要监控执行以上任务的具体状况,假使之前任务发生失败,便需要再次予以执行。如果某一 Job 作业遭到submit ,那么 Job Tracker便会把所收至的配置信息以及作业信息分发到 DataNode节点上。除此之外, Job Tracker也需要对任务进行调度且对每个Task 任务的执行情况进行监控。
那么就上述内容的阐述便可以发现: Hadoop 分布式系统体系结构核心由两部分所构成,即 Map Reduce 以及 HDFS。HDFS在 Map Reduce 任务执行时给予了以下支持:文件操作以及存储数据等。以 HDFS为基础,任务跟踪、任务分发、以及任务的完成由 Map Reduce 实现,且对并结果进行收集,两者共同地促使了Hadoop 分布式集群任务的完成。
.........................
结论
随着大数据时代的到来以及云计算近年来的迅猛发展,越来越多的企业和个人应用云计算平台来处理其海量数据。本文首先介绍了云计算的相关概念以及云计算背后涉及的关键技术。分布式处理技术是云计算平台中的核心技术。文中介绍了当前使用最广泛的 Hadoop 云计算平台,并对 Hadoop 的生态架构进行了简单的介绍,重点介绍了 Hadoop 的两个核心组件 HDFS 和 MapReduce。然后介绍了 Hadoop 的调度算法流程以及 Hadoop 平台常见的三种调度算法。
.........................
结论
随着大数据时代的到来以及云计算近年来的迅猛发展,越来越多的企业和个人应用云计算平台来处理其海量数据。本文首先介绍了云计算的相关概念以及云计算背后涉及的关键技术。分布式处理技术是云计算平台中的核心技术。文中介绍了当前使用最广泛的 Hadoop 云计算平台,并对 Hadoop 的生态架构进行了简单的介绍,重点介绍了 Hadoop 的两个核心组件 HDFS 和 MapReduce。然后介绍了 Hadoop 的调度算法流程以及 Hadoop 平台常见的三种调度算法。
在以上研究的基础之上,把小作业的饥饿问题和 Reduce 数据倾斜作为了本论文的重点研究对象。由于小作业的 Reduce 阶段用时相对较短,如果大作业长期占用 Reduce 节点资源,小作业就无法得到执行,这对小作业的执行来说是非常不利的,并举例说明了小作业的饥饿,而且此时节点上很有可能存在系统资源利用率不高的问题。结合以上分析,本文提出了一种基于时间的提高小作业执行效率的 Reduce 调度算法。该算法提出了一种时间评估模型,首先估计 Map 阶段的剩余完成时间以及 Reduce 任务的 shuffle 和 sort 阶段的时间,然后比较 Map阶段的剩余完成时间以及 Reduce 任务的 shuffle 和 sort 阶段的时间来对队列中的Reduce 任务重排序。通过实验验证该算法不仅有效缩短了小作业的执行时间,并且也是系统的资源利用率得到了提升。
Reduce 的数据倾斜问题严重影响着 Reduce 任务的负载均衡,进而制约着整个集群的性能,为了改善 Reduce 的数据倾斜问题,本文提出了基于贪心算法的分区策略,首先通过抽样获得要执行的 Reduce 任务的 key 数据的分布情况,然后通过贪心算法求出这些 key 值对于 Reduce 节点数的平均值 avg,然后为每一个Reduce 分配接近 avg 的 key,进而实现 Reduce 节点上的负载均衡,最后通过实验结果分析,证明其在负载均衡以及提高作业执行效率方面的优势。
参考文献(略)
参考文献(略)

