第一章 绪论
1.1 选题背景与研究意义
近年来,互联网技术的迅猛发展和大量普及,全世界已经步入大数据时代。基于如此庞大的数据资源,如何从这些数据中获取有用的知识和信息资源来指导人类科学做出各种正确决策的需求越来越迫切,从而引起了全世界的广泛关注。传统的信息检索技术具有一定局限性,对用户有一定专业要求,数据挖掘技术可以对信息数据进行快速、高效、准确的分析,提取网络信息数据的有用知识,数据挖掘技术是多学科的交叉,建立在低级的数据检索技术之上。
二十世纪九十年代,数据挖掘技术被提出,自此得到各界巨大关注,面对数据的疯狂增长,人们很难轻易的发现数据中所包含的对自己有用的知识。对于这些不易发现,隐藏的知识,数据挖掘技术能很好的面对这些问题,现如今,各行各业,如医疗、商业、通讯等,都大量使用数据挖掘技术来为自己的效益提供帮助,获得广泛的好评。
1.1 选题背景与研究意义
近年来,互联网技术的迅猛发展和大量普及,全世界已经步入大数据时代。基于如此庞大的数据资源,如何从这些数据中获取有用的知识和信息资源来指导人类科学做出各种正确决策的需求越来越迫切,从而引起了全世界的广泛关注。传统的信息检索技术具有一定局限性,对用户有一定专业要求,数据挖掘技术可以对信息数据进行快速、高效、准确的分析,提取网络信息数据的有用知识,数据挖掘技术是多学科的交叉,建立在低级的数据检索技术之上。
二十世纪九十年代,数据挖掘技术被提出,自此得到各界巨大关注,面对数据的疯狂增长,人们很难轻易的发现数据中所包含的对自己有用的知识。对于这些不易发现,隐藏的知识,数据挖掘技术能很好的面对这些问题,现如今,各行各业,如医疗、商业、通讯等,都大量使用数据挖掘技术来为自己的效益提供帮助,获得广泛的好评。
传统关联规则 Apriori 算法需要频繁扫描数据库,建立大量候选项集等缺点,对于很多问题是无法适应的,更别说是大数据时代的到来。如何寻找高效的关联规则发现算法,以便更好的利用数据中隐藏的知识,这是很有意义的。
另一方面,当需要用传统的 C4.5 算法对数据分类进行时,无可避免的要对数据进行事先的准备;其次,用信息增益率这一属性度量选择属性,需要大量的对数运算,效率不高。但是,现实世界的数据千变万化,且类型繁杂,用传统的 C4.5 算法处理,这是不实际的,所以,找到优化 C4.5 算法的方式,提高 C4.5 算法的效率和分类正确率,是有很重大的意义和价值的。
另一方面,当需要用传统的 C4.5 算法对数据分类进行时,无可避免的要对数据进行事先的准备;其次,用信息增益率这一属性度量选择属性,需要大量的对数运算,效率不高。但是,现实世界的数据千变万化,且类型繁杂,用传统的 C4.5 算法处理,这是不实际的,所以,找到优化 C4.5 算法的方式,提高 C4.5 算法的效率和分类正确率,是有很重大的意义和价值的。
..........................
1.2 国内外研究现状
1.2.1 数据挖掘研究现状
1989 年 8 月在美国底特律召开的第十一届国际人工智能会议上,首次提出了知识发现 KDD 这一概念[1],之后,人们对数据挖掘进行了简单的分类,在科学研究方面,叫做知识发现;在工程应用方面,叫做数据挖掘。数据挖掘一直是研究者们密切关注的话题。经过 20 年前后的发展,数据挖掘领域取得了长足的进步并且硕果累累。当下,研究者们主要围绕三个方面展开研究,即数据挖掘的理论研究、数据挖掘的技术和数据挖掘的落地应用。
在几十年数据挖掘发展的历史岁月里,人们习惯将它划分成四个进程[2]:①第一个进程是 1970 年代的电子邮件时期,随着美国信息高速公路的建设,信息的增长速度惊人,数据挖掘应运而生且得到一定发展;②第二个进程是上世纪 90 年代,由于网络技术的进步,信息泛滥,这时候的数据挖掘技术可以集成数据库,支持多种模型;③第三个进程是 21 世纪初的的电子商务时期,该时期数据挖掘技术可对数据进行有效管理并实现部分功能;④第四个进程是全程电子商务时期,是数据挖掘技术成为一门独立学科,各种算法得到飞速发展,与不同计算设备有机的融合,并应用到实际。
目前,数据挖掘的功能得到迅速的发展,取得了巨大的研究成果。数据挖掘常用的功能主要有:关联规则的挖掘、分类与预测、聚类分析以及异常检测等。它们都为数据库中的知识发现提供了大量可能。
另一方面,由于各行各业对数据挖掘的需求迫切,大量的可用于大规模数据分析的应用软件被研究出来,得到落地的应用[3]。例如:Knowledge Studio、IBM 公司开发的Intelligent Miner 等等。它们都为各行各业提供了大量的决策支持。但相较来说,国内的挖掘软件的使用远不及国外的多。
当下,数据挖掘的研究重点主要集中在以下几个方面:对网页数据的分析、对文本信息的分析以及对多媒体数据的分析。因为我们正处于互联网高速发展的时代,所以对网页数据的挖掘应该会发展和进步更快,它从网站的各类数据中得到有价值的信息,为用户提供高质量的数据;文本数据挖掘是数据挖掘的主要趋势之一,常见的文本数据挖掘技术功能有文本分类、文本分析和文本总结等;多媒体数据的分析,它所研究的对象主要为视频文件、图片、音频文件和图像等等,它是多媒体技术与数据挖掘技术的有机融合。
最后,我们简单介绍数据挖掘领域可能较为重要的发展趋势:①标准化数据挖掘语言,标准化的语言有助于将数据挖掘技术更好的做成系统化的产品,供人们使用;②寻求数据挖掘技术中可视化技术的突破,越好的可视化技术,越能方便直观的向用户展现知识,更多的利用其潜在价值;③因为随着科技的发展,不同类型的数据不断呈现,该要怎样面对带来的难题,是值得深入钻研的;④数据挖掘如何在特定领域展现强大的功能;⑤网络信息爆炸和分布式广泛应用,如何在此环境下进行有效挖掘。
...............................
第二章 数据挖掘研究及技术基础
2.1 数据挖掘技术概述
我们从大量的数据中想要获得有用的知识和信息,而这些数据中往往还含有大量的干扰数据,这就用到了数据挖掘技术。数据挖掘被提出虽然还不到三十年,但发展的繁荣程度却超过很多领域。它是综合了很多学科和领域的知识而产生的又独立的技术,涉及的学科包括数据库、模式识别、人工智能、机器学习、数据可视化、统计学等等,受到各领域的高度重视。
2.1.1 数据挖掘流程
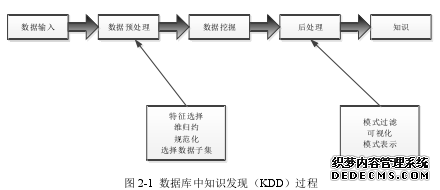
数据挖掘过程一般需要经历三个步骤,包括数据预处理、数据挖掘、结果评估与知识表示[33,34]。这些步骤在具体挖掘行为中可能需要交替重复进行,才能达到较为满意的结果。
(1)数据预处理
数据预处理一般包括数据清理、数据集成、数据变换以及数据归约几个步骤。数据清理就是通过补充缺失的值、识别孤立点等方法来消除噪声数据和不一致数据造成的干扰;数据集成,顾名思义,就是将不同来源的数据集中起来储存在同一个设备中,它可以方面地解决数据冗余和不一致性;数据变换就是当数据原本的格式不能用于直接挖掘时,将数据通过平滑、规范化、聚集等处理手段,来将数据格式转换成可直接用于挖掘;数据归约技术是当数据量大且复杂时,可利用该技术得到数据的简单表示,它不仅保持了原有数据的完整性,还大幅度提高了挖掘的效率。
(2)数据挖掘
这一步骤是整个数据挖掘过程中最为关键的部分,它是利用若干算法及方法发现数据中的有用知识。数据挖掘是 KDD 过程中最复杂的一个部分,得到广泛研究,它直接影响整个知识发现过程的效率和结果。
(3)结果评估[35]与知识表示
上一个阶段数据挖掘得到的结果也许是毫无意义的或者用户没办法直接理解的,又或许是还尚且不能完整的达到预期想要的结果,因此就需要本步骤对所发现的模式进行评估和修剪,并将最终的结果用可视化的方法展示给用户,便于用户理解。
综上所述,数据挖掘技术的一般流程可以用图 2-1 表示。
............................
1.2 国内外研究现状
1.2.1 数据挖掘研究现状
1989 年 8 月在美国底特律召开的第十一届国际人工智能会议上,首次提出了知识发现 KDD 这一概念[1],之后,人们对数据挖掘进行了简单的分类,在科学研究方面,叫做知识发现;在工程应用方面,叫做数据挖掘。数据挖掘一直是研究者们密切关注的话题。经过 20 年前后的发展,数据挖掘领域取得了长足的进步并且硕果累累。当下,研究者们主要围绕三个方面展开研究,即数据挖掘的理论研究、数据挖掘的技术和数据挖掘的落地应用。
在几十年数据挖掘发展的历史岁月里,人们习惯将它划分成四个进程[2]:①第一个进程是 1970 年代的电子邮件时期,随着美国信息高速公路的建设,信息的增长速度惊人,数据挖掘应运而生且得到一定发展;②第二个进程是上世纪 90 年代,由于网络技术的进步,信息泛滥,这时候的数据挖掘技术可以集成数据库,支持多种模型;③第三个进程是 21 世纪初的的电子商务时期,该时期数据挖掘技术可对数据进行有效管理并实现部分功能;④第四个进程是全程电子商务时期,是数据挖掘技术成为一门独立学科,各种算法得到飞速发展,与不同计算设备有机的融合,并应用到实际。
目前,数据挖掘的功能得到迅速的发展,取得了巨大的研究成果。数据挖掘常用的功能主要有:关联规则的挖掘、分类与预测、聚类分析以及异常检测等。它们都为数据库中的知识发现提供了大量可能。
另一方面,由于各行各业对数据挖掘的需求迫切,大量的可用于大规模数据分析的应用软件被研究出来,得到落地的应用[3]。例如:Knowledge Studio、IBM 公司开发的Intelligent Miner 等等。它们都为各行各业提供了大量的决策支持。但相较来说,国内的挖掘软件的使用远不及国外的多。
当下,数据挖掘的研究重点主要集中在以下几个方面:对网页数据的分析、对文本信息的分析以及对多媒体数据的分析。因为我们正处于互联网高速发展的时代,所以对网页数据的挖掘应该会发展和进步更快,它从网站的各类数据中得到有价值的信息,为用户提供高质量的数据;文本数据挖掘是数据挖掘的主要趋势之一,常见的文本数据挖掘技术功能有文本分类、文本分析和文本总结等;多媒体数据的分析,它所研究的对象主要为视频文件、图片、音频文件和图像等等,它是多媒体技术与数据挖掘技术的有机融合。
最后,我们简单介绍数据挖掘领域可能较为重要的发展趋势:①标准化数据挖掘语言,标准化的语言有助于将数据挖掘技术更好的做成系统化的产品,供人们使用;②寻求数据挖掘技术中可视化技术的突破,越好的可视化技术,越能方便直观的向用户展现知识,更多的利用其潜在价值;③因为随着科技的发展,不同类型的数据不断呈现,该要怎样面对带来的难题,是值得深入钻研的;④数据挖掘如何在特定领域展现强大的功能;⑤网络信息爆炸和分布式广泛应用,如何在此环境下进行有效挖掘。
...............................
第二章 数据挖掘研究及技术基础
2.1 数据挖掘技术概述
我们从大量的数据中想要获得有用的知识和信息,而这些数据中往往还含有大量的干扰数据,这就用到了数据挖掘技术。数据挖掘被提出虽然还不到三十年,但发展的繁荣程度却超过很多领域。它是综合了很多学科和领域的知识而产生的又独立的技术,涉及的学科包括数据库、模式识别、人工智能、机器学习、数据可视化、统计学等等,受到各领域的高度重视。
2.1.1 数据挖掘流程
数据挖掘过程一般需要经历三个步骤,包括数据预处理、数据挖掘、结果评估与知识表示[33,34]。这些步骤在具体挖掘行为中可能需要交替重复进行,才能达到较为满意的结果。
(1)数据预处理
数据预处理一般包括数据清理、数据集成、数据变换以及数据归约几个步骤。数据清理就是通过补充缺失的值、识别孤立点等方法来消除噪声数据和不一致数据造成的干扰;数据集成,顾名思义,就是将不同来源的数据集中起来储存在同一个设备中,它可以方面地解决数据冗余和不一致性;数据变换就是当数据原本的格式不能用于直接挖掘时,将数据通过平滑、规范化、聚集等处理手段,来将数据格式转换成可直接用于挖掘;数据归约技术是当数据量大且复杂时,可利用该技术得到数据的简单表示,它不仅保持了原有数据的完整性,还大幅度提高了挖掘的效率。
(2)数据挖掘
这一步骤是整个数据挖掘过程中最为关键的部分,它是利用若干算法及方法发现数据中的有用知识。数据挖掘是 KDD 过程中最复杂的一个部分,得到广泛研究,它直接影响整个知识发现过程的效率和结果。
(3)结果评估[35]与知识表示
上一个阶段数据挖掘得到的结果也许是毫无意义的或者用户没办法直接理解的,又或许是还尚且不能完整的达到预期想要的结果,因此就需要本步骤对所发现的模式进行评估和修剪,并将最终的结果用可视化的方法展示给用户,便于用户理解。
综上所述,数据挖掘技术的一般流程可以用图 2-1 表示。
............................
2.2 关联规则基本理论
关联规则挖掘是找出大量数据集中项集与项集之间隐藏的有价值的关联和关系,1993 年,Agrawal 等人首次提出了挖掘顾客交易数据库中项集间的关联规则问题,自此关于关联规则的研究呈现井喷式的发展。

..........................
关联规则挖掘是找出大量数据集中项集与项集之间隐藏的有价值的关联和关系,1993 年,Agrawal 等人首次提出了挖掘顾客交易数据库中项集间的关联规则问题,自此关于关联规则的研究呈现井喷式的发展。
..........................
第三章 改进的频繁项集挖掘算法 .................. 15
3.2 矩阵 Apriori 介绍 ........................... 18
3.3 改进的频繁项集挖掘算法 .............................. 19
第四章 改进的决策树 C4.5 算法的特征选择方式 ...................... 24
4.1 决策树 C4.5 算法 .......................... 24
4.2 二进制粒子群优化算法 ....................... 24
4.3 BPSO 与决策树 C4.5 的结合算法 ............... 27
第五章 数据分析平台的设计 ......................... 32
5.1 MyBatis 框架介绍 .............................. 32
5.2 Spring Boot 框架介绍 ........................... 33
第五章 数据分析平台的设计
5.1 MyBatis框架介绍
MyBatis本是Apache公司的一个开源项目,称为iBatis,这个项目于2010年由Apache软件基金会迁移到 Google 代码中,伴随着更名为 MyBatis。MyBatis 是一款优秀的持久层框架,它强大且支持定制化 SQL、存储过程以及高级映射。MyBatis 几乎避免了所有的 JDBC 代码和手动参数设置以及获取结果集,它可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java 对象)映射成数据库中的记录。#p#分页标题#e#
MyBatis[65,66]的功能架构主要分为三层,即 API 接口层、数据处理层和基础支撑层,他们分别的作用如下:
API 接口层:接口 API 是供外部使用的,开发者可以通过这些 API 操作数据库,一旦接口层获得了调用请求,它就会调用数据处理层执行特定的数据处理。
数据处理层:这一层的目的是根据调用的请求完成一次数据库操作,掌管具体的SQL 查找、SQL 解析、SQL 执行和执行结果的映射处理等。
基础支撑层:主要是对基本功能的支撑,将一些共用的部分,比如连接管理、事务管理、配置加载和缓存处理,提炼出来作为最基础的组件,为上层的数据处理提供最基础的支持。
........................
第六章 总结与展望
数据处理层:这一层的目的是根据调用的请求完成一次数据库操作,掌管具体的SQL 查找、SQL 解析、SQL 执行和执行结果的映射处理等。
基础支撑层:主要是对基本功能的支撑,将一些共用的部分,比如连接管理、事务管理、配置加载和缓存处理,提炼出来作为最基础的组件,为上层的数据处理提供最基础的支持。
........................
第六章 总结与展望
6.1 总结
数据挖掘技术自被提出以来,引起了强烈的关注和重视。在信息爆炸的今天,怎样将数据挖掘技术与工程应用有机结合,挖掘更多潜在的有用的价值,以满足现实社会需求,这是之所以数据挖掘一直是研究的热门的原因。本文选取数据挖掘领域两个热门的算法,即关联规则 Apriori 算法和决策树分类 C4.5 算法,分别分析了两者算法的长处和所存在的不足,通过阅读相关文献资料以及对这些问题的思考,提出了一些改进方法,并在实验中验证,最终书写完成了本论文。总结一下,本文完成的工作如下:
数据挖掘技术自被提出以来,引起了强烈的关注和重视。在信息爆炸的今天,怎样将数据挖掘技术与工程应用有机结合,挖掘更多潜在的有用的价值,以满足现实社会需求,这是之所以数据挖掘一直是研究的热门的原因。本文选取数据挖掘领域两个热门的算法,即关联规则 Apriori 算法和决策树分类 C4.5 算法,分别分析了两者算法的长处和所存在的不足,通过阅读相关文献资料以及对这些问题的思考,提出了一些改进方法,并在实验中验证,最终书写完成了本论文。总结一下,本文完成的工作如下:
⑴ 对数据挖掘的主要功能做重点研究,对其中的关联规则 Apriori 算法和决策树分类 C4.5 算法进行深入研究,分析了算法的思想,发现其优点,并且重点分析了算法存在的问题。
⑵ 针对传统关联规则 Apriori 算法需要频繁扫描数据库,建立大量候选项集的缺点,提出了提出一种结合投影与排序频繁项集位置索引表的挖掘频繁项集改进算法,并且通过实验分析,发现其的确提高了搜索频繁项集的时间和空间效率。
⑵ 针对传统关联规则 Apriori 算法需要频繁扫描数据库,建立大量候选项集的缺点,提出了提出一种结合投影与排序频繁项集位置索引表的挖掘频繁项集改进算法,并且通过实验分析,发现其的确提高了搜索频繁项集的时间和空间效率。
⑶ 针对决策树 C4.5 算法需要大量的对数运算,且对高维数据的不适应性等缺点,提出了将二进制粒子群优化算法(BPSO)和决策树 C4.5 算法相结合的方式进行分类预测。首先利用二进制粒子群优化算法(BPSO)对属性进行选择,然后用决策树分类 C4.5算法建立决策树。通过实验验证,发现它的确提高了算法的效率和准确率。
⑷ 最后,通过获取的江南大学师生上网行为的路由日志信息,将数据进行相应的预处理,利用研究的数据挖掘相关模型和算法,分析了师生的网上行为特点和规律,通过可视化的编程技术,直观的展示用户网上行为的具体信息。
参考文献(略)
参考文献(略)

