本文是一篇计算机论文,计算机的应用在中国越来越普遍,改革开放以后,中国计算机用户的数量不断攀升,应用水平不断提高,特别是互联网、通信、多媒体等领域的应用取得了不错的成绩。(以上内容来自百度百科)今天为大家推荐一篇计算机论文,供大家参考。
第 1 章 绪 论
大数据已经成为了信息技术领域中的一个研究热点。它是云计算、大数据、人工智能三位一体中的原材料基础,因此大数据问题的解决对生产生活中的各项事业都有重要的推动作用。大数据本身的复杂性和它的广泛应用潜质,使得大数据领域包含了许多具有普遍性或针对性的难题需要解决。大数据领域中具有普遍性的研究问题应该首先得到重点研究,因为这些问题的缓解和突破对大数据领域的深入研究和应用所产生的推动作用更大。其中的大数据高效处理问题就是具有普遍影响性和发展瓶颈性且亟待解决的难题。本文基于三位一体中的底层支撑平台即云计算技术对大数据高效处理的若干关键问题进行了一定的研究。本章首先给出了云计算下大数据高效处理问题的研究背景和意义;然后简要介绍了国内外研究现状;其次着重阐述了本文研究内容;最后给出了本文组织结构。
1.1 研究背景和意义
当前是人类社会繁荣发展的时代,科学技术每天都在不断进步。而随着国际一体化进程的加速和互联网技术的蓬勃发展,这个开放的世界每时每刻都在产生涉及方方面面的大量数据。在信息技术没有得到充分发展的年代,社会的发展还不足以产生大量数据。因此,数据一直以来都被视为一种稀缺资源。根据信息论,我们知道数据包含了信息和冗余数据,而这里所说的信息可以是知识、情报、模式、规则等极其珍贵的财富和资源。为了挖掘和发现这些有价值的信息,需要利用计算机科学和技术的发展来对数据进行处理和分析,这就衍生出了计算机科学下面的若干子学科分支,如知识发现、数据挖掘、知识表达、图像处理、自然语言理解等。科研人员在这些领域中针对数据分析算法的设计和数据的高效利率上不断进行研究和探索。但一直以来都受制于数据来源以及数据量的不足,这无疑成为了阻碍数据科学发展的一个瓶颈。而随着信息技术的发展,数据爆炸式增长,大数据时代到来。数据存储和数据库技术的发展使长期保存积累大规模结构化和非结构化数据成为可能。数据的缺乏不再是一个问题。人们相信利用大数据可以找到许多困扰我们多年的难题的解决方案;利用大数据可以挖掘出许多商业上具有很高价值的信息和模式;利用大数据可以促进科学研究的飞跃式进步,如生物医学、地质勘探、人工智能等对人们生产生活产生翻天覆地影响的学科领域。随着科学技术的不断发展和人类世界数据量的不断增多,大数据已经成为极其重要的研究课题。
..........
1.2 国内外研究现状
自大数据出现以来,如何解决大数据问题,实现大数据的高效处理一直是一个倍受关注的课题,近年来更是成为最热点的研究领域之一,被世界各国置于国家战略的高度。无论是工业界还是学术界,都在研究和应用基于分布式并行云计算的大数据分析处理,但对云平台下的大数据高效处理的研究还处于初级阶段。下面对旨在大规模数据高效处理的相关研究进行简要的介绍,其中包括针对大数据的分布式云存储、云计算资源调度和大数据的预处理。为了高效地解决大数据问题,利用分布式云存储来管理数据至关重要。单一存储介质的容量是有限的,随着大数据的爆炸性增长其不可无限地进行纵向扩展。而大量的存储节点进行横向扩展组成的存储集群也需要分布式计算集群来进行管理,以实现高效的检索和其它管理功能。因此,通过分布式云存储系统来管理大数据是必然选择。目前在工业界主要使用类 HDFS 存储架构的分布式文件存储系统来存储大数据[1]。该系统实现了大规模非结构化和结构化数据的分布式存储,是大数据存储系统从无到有、从理论到实践的里程碑式成果。但它的算法和策略都相对比较简单,因此随着大数据理论的发展和需求的不断提升,必然需要研究更加高效的存储策略与系统。Brinkmann 等人[2]提出了一个随机化的块级别存储虚拟化方法,通过 hash 机制将数据块放置到不同容量的存储节点中进而实现容量高效、时间高效、紧凑型和自适应性的目标。Zhang 等人[3]基于滑动窗口思想提出了 SLAS 方法通过使用一个新的映射管理方案来支持数据的重布局。Yuan 等人[4]旨在科学云工作流中应用数据的分布式存储问题,设计了一种基于矩阵与数据间依赖关系的 k 均值聚类策略来放置数据。郑湃等人[5]针对云计算环境下数据密集型应用的高时间开销的数据放置部署问题,设计了一种同时考虑数据间依赖关系、负载均衡以及时间复杂度的数据放置解决方案,基于数据副本通过阶段性部署优化实现资源的节省。Chang 等人[6]针对系统的总体负载均衡,基于分析数据的历史访问记录来给每个数据访问记录赋予一个权重值,根据权重值来确定相应数据的副本数量与部署位置。
.........
第 2 章 相关概念介绍
本文主要研究云计算下大数据高效处理的若干关键问题,包括大数据云计算下多任务部署方法与虚拟机的动态迁移策略、针对大数据高效处理的移动云计算模型与部署方法、大数据的预处理以及云计算下大数据推荐系统框架。根据本文的研究内容,本章对这些相关概念进行了针对性的总结介绍,简要阐述了本文研究过程中涉及的各种相关技术。
2.1 云计算与大数据
云计算(Cloud Computing)的概念由Google公司于2006年首次提出。它的本质是一种分布式计算范式,融合了分布式计算、并行计算、效用计算等传统计算机技术。云计算可以利用虚拟化技术将大量同构和异构的各类可配置计算资源(如:网络、存储、CPU、应用服务以及其它I/O设备)抽象为一个统一的、底层透明的、可按需提供服务能力的共享资源池。用户可以通过方便的、普遍存在的、按需的网络访问申请共享资源池中的资源,按使用量进行结算付费。因此,云计算具有弹性可扩展的特性,而无需考虑硬件资源的异构性或型号的差异,不同资源实体可以动态实时地加入和退出。根据服务层次的不同,云计算可以分成以下三类服务模型:(1)Software as a Service (SaaS):软件即服务。这类云计算服务将应用软件作为一种服务能力通过网络按需提供给用户。用户不再需要为了使用某应用程序而购买该软件,也无需管理或控制底层基础设施,只需通过浏览器等网络接口或其它网络程序接口来访问相应的云计算SaaS服务,按使用量付费即可获得相应的软件服务。(2)Platform as a Service (PaaS):平台即服务。这类云计算服务与SaaS类似,也是将软件作为一种服务提供给用户,但它提供的是一套软件开发平台或者是通过使用提供商支持的编程语言、函数库、服务和工具创建的用户定制应用程序。我们可以将PaaS部署到云基础设施中向用户提供平台服务,而用户无需管理和控制底层基础设施。(3)Infrastructure as a Service (IaaS):基础设施即服务。这类云计算服务提供用户的服务是能够部署和运行任意软件(包括操作系统和各级别应用程序)的处理器、存储、网络和其它基本计算资源与I/O设备,即虚拟化资源池。用户不需要管理和控制底层云基础设施,但可以使用云基础设施服务控制操作系统、存储和部署的应用程序。
........
2.2 移动云计算与大数据
移动云计算是伴随着云计算、移动设备和移动互联网的高速发展而出现的新兴概念。目前移动云计算还没有一个公认的统一精确定义,但它被普遍认为是云计算、移动计算和无线网络技术的有机结合,旨在将弹性可扩展的丰富计算资源带给移动用户、网络运营商和云计算提供商。近些年,移动设备和移动无线网络呈现出爆炸式蔓延发展态势,给社会生产和人们生活带来了深远影响。“计算”正在从固网的个人计算机向个人移动设备上转移。许多传统应用程序和一些顺应社会发展的新兴应用都运行在个人移动设备上。然而,移动设备本身硬件的发展速度和计算能力的提升速度远不及人们对个人移动设备的应用需求增速。而且移动设备存在一些由于其自身特点而产生的难以解决的瓶颈因素限制其资源利用率的提升,如:有限的电池容量、受限的硬件体积、受限的网络连通性等。与此同时,云计算的出现为固网下计算能力的不断扩展与提升提供了解决方案。在这样的背景下,将云计算与移动计算结合,即移动云计算的概念被提出。
.........
第 3 章 针对大数据高效处理的云计算下多任务............19#p#分页标题#e#
3.1 一种云计算下负载均衡感知的启发式任务部署方法 ...... 19
3.2 基于改进人工蜂群算法节能感知的虚拟机动态迁移策略 ........ 36
3.3 本章小结 ........ 53
第 4 章 针对大数据高效处理的移动云计算模型与部署方法 ...........55
4.1 基于虚拟机部署的移动云计算模型及启发式部署方法 ............ 55
4.2 基于社区协同计算的移动云计算模型及移动应用划分分派方法 ...... 68
4.3 本章小结 ........ 86
第 5 章 云计算下大数据实例约简预处理....89
5.1 基于聚类分析与最优极小样本集的大数据实例约简预处理方法 ...... 89
5.2 云计算下结合社会上下文与机器学习思想的大数据推荐框架 ........ 103
第 5 章 云计算下大数据实例约简预处理与大数据推荐系统框架
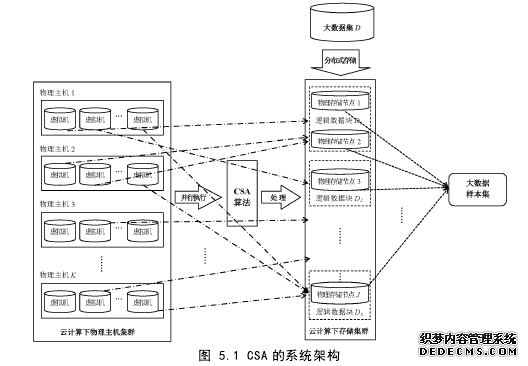
通过大数据的多层面预处理来实现大数据高效处理潜力是一种直观的想法和直接的手段。大数据有效且高效的预处理无疑是云计算下大数据高效分析处理的关键共性问题之一。众所周知,大数据难题很大程度上源于其数据量的大规模性以及其特征的高维性;而与此同时我们还需要利用它的大规模实例和高维特征来实现相应的需求。大数据的约简和降维预处理方法都是旨在尽可能保证原大数据的特点和分布特性的情况下降低其数据规模,而与传统的基于随机抽样的样本处理分析截然不同。因此对大数据的约简和降维预处理是十分重要和亟待突破的难题,是大数据预处理的核心问题。本章针对现有数据约简策略的不足,提出了一种基于聚类分析的大数据实例约简预处理方法(CSA)。它通过利用大数据聚类和极小样本集最优化抽样思想实现高效的大数据实例规模约简策略,同时基于类簇的分布特点利用云计算下的并行计算能力实现高效的大数据实例约简预处理过程,进而在尽可能保证大数据原有特性的情况下凭借减少实例规模来从根本上促进大数据的高效分析处理。另外,本章针对云计算下大数据的高效处理,对基于云计算的大数据推荐系统预测模型进行了研究,提出了一种结合机器学习思想与社会上下文理论的启发式大数据推荐系统框架方法(BDRSF)。它旨在实现大数据的规模性与云计算下并行计算能力之间的优势互补。由于其自身也是一种大数据分析处理问题,因此通过对云计算下基于大数据的推荐预测方法的研究可以促进云计算下大数据高效处理。同时通过在云计算下对这一经典数据预测问题的研究,实现了从模型与算法层面来增强云计算下大数据高效处理的潜力与基础。
.......
结论
信息时代开始进入大数据阶段。尽管大数据是一种宝贵的信息财富,但是现有的经典计算范式和传统的数据分析方法不能对大数据进行高效的分析处理与利用。而与此同时,云计算的出现与发展为大数据提供了底层支撑平台,利用云计算弹性可扩展的虚拟化资源池及其并行计算潜力可以为大数据问题的解决提供物质基础。由于大数据问题本身涉及诸多学科和领域的研究而且许多跨学科领域都对大数据有应用需求,因此针对云计算下的大数据问题有许多研究方向。着眼于不同的方向和学科都有诸多不同的研究问题,但是所有这些大数据研究领域在底层研究上具有共性问题,简言之就是云计算下大数据的高效分析处理问题。这个问题对大数据下各个领域的研究与应用都有着决定性的深远影响。本文围绕云计算下大数据高效处理的若干关键问题展开研究,首先重点关注针对大数据高效处理的云计算下多任务部署方法与虚拟机动态迁移策略问题;然后在此基础之上针对大数据高效处理对移动云计算模型与部署方法进行了研究;最后针对大数据高效分析处理研究了云计算下大数据实例约简预处理问题与大数据推荐系统框架。本文的主要贡献如下:本文旨在云计算下大数据的高效并行处理,提出了一个针对大数据云平台在时间维度上长期负载均衡优化的启发式多任务部署方法 LB-BC。现有的负载均衡策略往往是针对当前批次的任务部署进行优化,而没有考虑云平台长期运行过程中的任务负载在最优主机选择上存在前后相互影响的问题。本文基于云平台任务部署的特点,从大数据云平台长期负载均衡最优化的角度出发,设计了基于聚类分析与贝叶斯定理相结合的全局最优目标主机选择方法。基于聚类分析与贝叶斯概率模型找出最优主机类簇来部署大数据多任务,进而实现简单高效的大数据云平台长期负载均衡机制。LB-BC 方法通过实现大数据云平台的长期负载均衡最优化使得云计算资源能够充分高效地被利用,进而最大化云平台的对外服务能力,达到促进云计算下大数据高效并行处理的效果。
..........
参考文献(略)

