本文是一篇计算机论文,计算机操作系统的种类繁多,依其功能和特性分为分批处理操作系统、分时操作系统和实时操作系统等;依同时管理用户数的多少分为单用户操作系统和多用户操作系统;适合管理计算机网络环境的网络操作系统。(以上内容来自百度百科)今天为大家推荐一篇计算机论文,供大家参考。
第 1 章 绪论
1.1 研究背景与意义
自动推理是人工智能领域的一个重要分支,是人工智能的核心技术和最具挑战性的研究方向之一。著名计算机科学家L. Wos教授这样定义自动推理:“使用明确而严格的符号表示信息,用精确的推理规则作出结论,并且用仔细描述的策略控制推理规则”。自动推理的发展深刻影响着人工智能以至计算机科学的其它研究方向。20世纪90年代末以后,尤其近些年来,随着计算机软、硬件技术的发展,自动推理技术成为了硬件校验、软件生成和验证、安全协议验证、智能规划等诸多领域发展的重要基础。自动推理在计算机工程中同样得到了广泛的应用,IBM、Intel、AMD等国际知名硬件厂商普遍采用基于自动推理的硬件校验技术,并取得了丰厚的商业回报。命题逻辑是其它逻辑的基础,大部分其它逻辑的推理问题都可以转化为命题逻辑进行求解[1-4]。组合优化、自动规划、抽象论辩等领域问题都可以表示或转化为命题逻辑进行求解[5-11]。命题逻辑的推理方法研究是自动推理领域发展的基石。依赖知识编译的推理方法是求解命题逻辑推理问题的重要方法之一。知识编译的主要目的是为了提高重复性任务的计算效率,主要思想是将问题的求解分为两个阶段:离线编译和在线推理。离线编译阶段将知识库编译为易处理目标语言,在线推理阶段基于易处理目标语言完成推理任务。基于易处理目标语言,许多难解类问题能在多项式时间内完成,因此通过多次在线推理可以补偿离线编译所花费的时间。目前,易处理目标语言的种类较多,主流目标语言主要包括:Horn、OBDD、d-DNNF、SDD和EPCCL等。2003年,Lin等人提出了扩展规则推理方法(extension rule,简记为ER)[12],被著名人工智能专家M. Davis称为与归结方法“互补”的方法。与归结方法相反,扩展规则推理方法通过扩展出所有极大项组成的集合判定子句集的可满足性。扩展规则推理方法适用于处理互补因子较高的实例。2004年,Lin等人将扩展规则推广到知识编译领域,并提出了目标语言EPCCL理论和相应的KCER编译算法[13]。随后,许多学者针对EPCCL理论展开了研究。然而现有EPCCL理论编译方法的编译效率和编译质量较低,这限制了EPCCL理论在相关领域推理问题上的应用。因此,提高EPCCL理论编译方法的效率和质量对于扩展规则推理方法的进一步发展具有重要意义。
..........
1.2 命题逻辑基础
计算机科学中的逻辑是一种形式化描述工具,能够使人们对遇到的一些计算机科学领域中的情境进行建模,建模结果能够帮助人们实现形式化推理。计算机科学中常见的逻辑包括命题逻辑、谓词逻辑、模态逻辑、时序逻辑、模糊逻辑等,其中命题逻辑是其它逻辑的基础,大部分其它逻辑的推理问题都可以转化为命题逻辑进行求解。命题逻辑中的公式通常是由命题变量(或称为原子)、逻辑常量(true 和 false)和逻辑连接词(否定 、合取∧和析取∨)组成。下面,介绍一些命题逻辑中常用的基本概念: 变量(variable):能判断真假值的陈述句,例如:天下雨了,小明带伞了,小明被淋湿了等; 否定(negation):命题公式 G 取非,记作 G; 文字(literal):变量 V(正文字)或者变量 V 的否定 V(负文字); 合取(conjunction):命题公式 G∧H,G∧H 为真,当且仅当 G 和 H 同时为真; 析取(disjunction):命题公式 G∨H,G∨H 为假,当且仅当 G 和 H 同时为假; 子句(clause):有限个文字的析取; 短语(term):有限个文字的合取; 合取范式(conjunctive normal form, CNF):有限个子句的合取,有时也称为子句集,SAT 问题指的就是判断子句集的可满足性,每个子句都包含 k 个文字的子句集记为 k-cnf,其中,k 是一个常数;3-SAT 问题指的是 CNF 公式中每个子句中包含三个文字,是被证明的第一个 NP-完备问题[14].
..........
第 2 章 基于子句相关性的扩展规则知识编译
启发式选择是提高推理方法推理效率的重要途径之一[26, 91, 98-99]。谷文祥等人设计了 MCN 和 MO 两种启发式策略,提高了 KCER 算法的编译效率,并降低了编译结果的子句集规模[91]。MCN 和 MO 启发式较适用于子句长度固定的 SAT 实例上的编译,然而它们并不适用于子句长度不固定的 SAT 实例上的编译。因此,设计针对子句长度不固定 SAT 实例的有效启发式策略能够丰富并完善扩展规则知识编译方法。首先回顾扩展规则和 EPCCL 理论的定义,扩展规则能够对单个子句和单个变量进行扩展操作。定义 2.1(扩展规则,extension rule)[12]给定一个子句 C 和一个变量集 N,D = {C∨a, C∨ a},其中 a∈N 并且 a 和 a 都不在 C 中出现,将 C 到 D 的推导过程称为扩展规则,D 中的子句称为 C 扩展得到的结果,并且 C ≡ D。由定义 2.1 可以看出,扩展规则与归结规则是完全相反的规则。同时,定义2.1 应用扩展规则后得到的子句集与原子句集等价。因此,扩展规则可以被看作是一条新的推理规则。应用扩展规则后,D 中子句间存在互补文字对。应用扩展规则推理方法过程中,期望得到扩展结果中子句间最好存在更多的互补文字对,以利用扩展规则的推理特性:依赖扩展规则的推理方法适用于互补因子较高的子句集可满足性判定[12]。定义 2.2(EPCCL 理论)[13]子句集 F 是一个 EPCCL 理论,则 F 中任意两个子句间均含有互补文字对。
2.1 相关性矩阵
任意两个子句之间存在一定的关联关系,若按照是否互补则可分为:互补和非互补;若按照是否相互蕴含则可分为:蕴含和非蕴含。然而仅仅找到两个子句是否互补或蕴含所得信息较少,不能充分挖掘子句集的特殊结构。在知识编译算法中,利用这类简单关系所设计的启发式策略会具有一定的局限性和不稳定性。因此充分挖掘子句间的关联关系对于提高知识编译算法的编译效率和编译质量具有重要意义。为了能够快速地判断两个子句是否互补或计算它们变量集合的差集,本文在相关性矩阵构建的过程中为每个子句设置一个 hash 表,用于保存每个子句所包含的变量状态。对于任意变量 l,若子句 C 包含文字 l,则 hash(l)=1;若子句 C包含文字 l,则 hash( l)=-1;若子句 C 不包含变量 l,则 hash(l)=0。基于上述 hash表的思想,给定任意子句集 F,构造 F 的相关性矩阵 R 能够高效实现,且所需时间复杂度 O(n2)。因此理论上构建相关性矩阵对于知识编译算法的整体运行时间基本上没有影响。
..........
2.2 基于相关性的启发式策略
对于任意子句集 F,构建出 F 的相关性矩阵 R 之后,能够找到 F 中任意子句的相关集,而相关集所不能扩展出的极大项集的规模就代表了 KCER 算法本次递归计算的结果的规模,因此在选择子句进行扩展时,应该尽量选择对应相关集所不能扩展出的极大项集较小的子句。假设选择子句 Ci∈F 进行一次递归计算,上述过程与 KCER 算法一次递归计算的过程等同,显然该计算过程所需时间与 k 有关,因此在设计启发式时应该考虑 k 的大小。若为了提高知识编译算法的效率应该选择 k 较小的子句进行扩展。然而计算相关集所不能扩展出的极大项集是一次递归计算的结果,k 越大则相关集所能扩展出的极大项集越大,且所不能扩展出的极大项集越小,因此在考虑编译算法的编译质量时,应该考虑对应 k值较大的子句进行扩展。
.........
第 3 章 EPCCL 理论的求交编译方法........33
3.1 超扩展规则........33
3.2 求交知识编译算法.....34
3.3 实验结果............42
3.4 本章小结............47
第 4 章 EPCCL 理论的并行编译方法........49
4.1 EPCCL 理论的并行求交编译算法 ......49
4.1.1 EPCCL 理论的求交操作 ...........49
4.1.2 IKCHER 算法的并行化....52
4.2 EPCCL 理论的并行求并编译算法 ......55
4.2.1 EPCCL 理论的求并操作 ...........56
4.2.2 UKCHER 算法的并行化 ...........60
4.3 实验结果............62
4.4 本章小结............69
第 5 章 互补知识编译方法........71
5.1 互补公式............71
5.2 CNF 到 c-FCCD 的编译算法 ......74
5.3 基于 CCD 语言的推理方法.........78
5.4 实验结果............83
5.5 本章小结............87
第 5 章 互补知识编译方法
本章首先提出互补公式的概念,并基于互补公式提出一种新的非等价的知识编译目标语言 c-FCCD,然后基于超扩展规则设计并实现相应的知识编译算法C2C,再通过理论分析得出互补公式和 c-FCCD 在多项式时间内所能支持的知识编译图谱中的查询操作和转化操作,最后对比测试了 C2C 算法的编译效率和编译质量。
5.1 互补公式
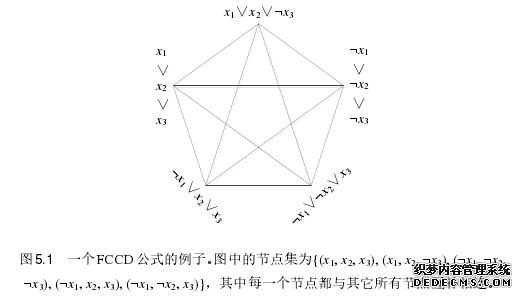
一个 CNF 公式 Σ 可以表示为一个互补连通图(complementary connecteddiagram,CCD)。一个 CCD 是一个二元组 G = (V, E),其中 V 是一个子句集,E V×V 是互补关系集合。二元关系(vi, vj) E 意味着 vi和 vj中包含了互补文字对。定义 5.1 给定一个 CNF 公式,其对应的互补连通图为 G = (V, E),G 是一个 EPCCL 当且仅当 G 是一个完全互补连通图(fully complementary connecteddiagram,FCCD)。本节主要通过理论分析得出互补公式和c-FCCD在多项式时间内所能支持的知识编译图谱中的查询操作,以及互补公式、c-FCCD 和 FCCD 在多项式时间内所能支持的知识编译图谱中的转化操作。
........
总结
在扩展规则的基础上,Lin 等人提出了一种基于扩展规则的知识编译方法KCER,可以将子句集编译为 EPCCL 理论。EPCCL 理论是知识编译目标语言的一种,知识编译的主要目的则是为了提高重复性任务的计算效率,主要思想是将问题的求解分为两个基本阶段:离线编译和在线推理。EPCCL 理论能够满足知识编译图谱中的全部八种查询操作,是一种优秀的知识编译目标语言,因此本文将其作为研究对象,基于扩展规则和超扩展规则从启发式选择、新型编译框架、并行编译、互补知识编译等方面研究了 EPCCL 理论的编译方法,旨在进一步提高扩展规则知识编译方法的编译效率和编译质量。基于上述分析,本文主要研究了以下内容:
1、提出了相关性矩阵的概念,并定义了相关集。基于对相关集性质的分析和扩展规则,建立了相关性矩阵和 KCER 算法之间的联系。基于相关集的基本信息以及相关性矩阵与 KCER 算法的联系,设计了 MNE 启发式和 M2S 启发式,用于选择满足“相关集所不能扩展出的极大项集对应 EPCCL 理论规模较小”的子句。最后,通过将 MNE 启发式和 M2S 启发式整合到 KCER 算法中,设计并实现了 MNE_KCER 算法和 M2S_KCER 算法。实验结果验证了 MNE 启发式和 M2S启发式的有效性,并表明了:对于子句长度随机的实例,MNE_KCER 算法和M2S_KCER 算法相比于 KCER 算法能够大幅度降低编译结果的规模,并且具有更高的编译效率。
2、提出了一种新的 EPCCL 理论编译算法:求交知识编译算法 IKCHER,适合难解类 SAT 问题的知识编译。基于超扩展规则能够求得任意两个非互补且不相互蕴含的子句所能扩展出极大项集的交集、差集和并集,并将所得结果以EPCCL 理论的形式保存。通过计算所有子句所不能扩展出极大项集的交集得出输入子句集所不能扩展出的极大项集,并将结果保存为 EPCCL 理论,IKCHER算法得到第一阶段的编译结果,然后 IKCHER 算法再用相同方法求得上述计算结果所不能扩展出极大项集对应的 EPCCL 理论,进而得出与输入子句集等价的EPCCL 理论。实验结果表明了:IKCHER 算法具有较高的编译效率和编译质量,是目前为止最优秀的 EPCCL 理论编译算法之一。
..........
参考文献(略)

