本文是一篇计算机论文,计算机科学与技术是研究计算机的设计与制造,并利用计算机进行有关的信息表示、收发、存储、处理、控制等的理论方法和技术的学科。(以上内容来自百度百科)今天为大家推荐一篇计算机论文,供大家参考。
第一章 绪 论
1.1 研究工作的背景与意义
随着互联网时代的全面到来,每时每刻都有海量的数据上传到网络。特别地,由于近年来移动设备的快速发展,进一步地促成了图像、视频数据的大量增长。根据统计,在 2016 年的第二季度,优酷土豆(公司)月覆盖用户 3.3 亿,同类型的爱奇艺也达到 2.7 亿的用户覆盖量;短视频综合平台秒拍日均上传视频量 150 万,日均播放量达 17 亿次,全网日活跃用户 6000 万;微信以及 QQ 的用户通过微信朋友圈和 QQ 空间日上传图片高达 10 亿张。面对图像、视频数据的迅猛增长,用户对图像、视频相关服务的需求也越来越高。在安全、教育、文化、医疗等许多领域,高效的视觉信息检索、分类以及标注等等技术受到了人们的热切关注:在医学领域,医院每天都会产生大量的包含病人生理、病理和解剖学习的医学图像,这些图像是医生进行临床诊断等医疗医学行为的重要依据。基于内容的医学图像处理技术从医学的角度对图像的纹理、形状等属性进行了分析,能够为医生提供可靠的诊断依据。在公共安全中,城市街道、机场、车站等公共场所利用监控摄像头来实时监控。基于内容的标注、识别能够有效地利用视频图像,在犯罪前期预警、犯罪后期追踪中,对犯罪行为、犯罪对象进行分析,给予犯罪预防、犯罪侦破有效的支持。在教育领域,网络课堂、教学视频给予学生更充分地辅导。通过分析视频内容,进行有效地筛选、标注,再结合用户特征给出更具针对性地推送。用户亦可作为数据的提供端,上传图片进行题目检索,更快速地获得所需信息。机器学习被广泛用于处理计算机视觉问题,其中多示例学习(Multi-InstanceLearning, MIL)就被用于场景分类、图像标注以及检索等等工作。多示例学习的目的是通过对训练集的学习,构建出能对测试集中的数据进行正确判断的分类器或评估器。不同于监督学习(supervisedlearning)将一个对象(object)表示为一个带有标签(label)的示例(instance),多示例学习将训练样本分为若干个包(bag),每个包由多个示例组成,包具有标记而示例本身则没有标记。在处理多示例学习问题时,有一个广泛认可的假设(被称为多示例学习标准假设):正包中至少存在一个正示例,而负包中不会包含任何正示例。同时相比于无监督学习(unsupervisedlearning)中训练集完全没有标签,多示例学习也是不同的。
........
1.2 多示例学习在计算机视觉领域应用的国内外研究历史与现状
多示例学习是一个特殊的分类问题,首先是被引入用于解决药物活性预测问题[17]。 不久之后,研究人员扩展多示例学习以解决诸如场景分类、图像注释、识别和检索等问题[29,37,55,59]。 对于标准多示例学习模型,输入数据是一组由多个示例组成的包。与传统的分类问题不同,只有包级的标签被给出,示例级的标签是未知的。为了描述示例级标签和包级标签之间的关系,相关工作提出了一个广泛认可的标准假设,即负包中的每个示例都是负示例,而正包则至少含有一个正示例。最初的分类预测都是给出了包级别的预测,之后示例级的多示例学习也引起了研究人员的关注。具体而言,对于示例级的多示例学习问题,如何发现正示例是非常重要的。例如,一个直接的推理策略是将每个正包中的示例都看作是正示例,再进行后续的训练算法。许多示例级的多示例学习算法利用了特征空间的结构信息,进行示例推理来训练或者生成最终结果。对于特征结果信息的高效使用,将对算法效果有巨大的改进。为了解决这个问题,我们采用聚类的策略来获得特征空间中示例的隐藏分布信息,原因如下:1.示例级标签是未知的,而聚类方法作为经典的非监督学习算法能够很好地处理未标记的数据;2.同一聚类簇中的示例是互相相似的,即这些示例的相似关系具有一致性;3.聚类后,后续处理可以同时在每个组上执行,因此可以实现并行化以降低时间成本。此外,尽管许多多示例学习模型已经被提出,并取得了不错的表现,但只有其中少数模型采用多视图特征来提高效率。对于图像分类和注释等任务,特征的表示会对算法最终性能产生强烈的影响,并且有许多类型的特征被设计出来处理各种计算机视觉相关的任务。在现实情况中,一个对象通常可以由多种类型的特征来描述。例如,通过智能手机拍摄的短视频,再配上地理信息和文本标签,上传到社交网络中。对应于各种生成方法或来源,这些特征具有不同的信息,并且这些信息可以是互补的,但也可能是冗余的。因此,多视图学习旨在充分利用数据的同时减轻冗余。
............
第二章 相关研究工作
本章将介绍本工作中涉及技术的相关研究。2.1 节首先分别回顾了图像分类、检索问题以及相关技术;2.2 节介绍了视频异常事件检测问题的定义和概况,总结了视频异常事件检测所使用的技术以及存在的问题;2.3 节介绍了多示例学习发展过程中出现的代表性算法。
2.1 图像分类与检索
2.1.1 图像分类问题
在本小节中,我们将介绍图像分类问题,它是从一组固定的类别中为输入图像分配一个标签的任务。这是计算机视觉中的核心问题之一,尽管它很简单,但却有各种各样的实际应用。事实上,许多其他看似不同的计算机视觉任务(如物体检测,图片分割)都可以简化为图像分类。目前图片分类问题存在的挑战有:1. 视角变化。同一个对象会因为拍摄角度不同而可能在图像中表现出不同的视觉特性。2. 尺寸变化。同一个对象会因为观测者与之不同的距离而影响图像中的大小。3. 变形。 许多物体并不是刚体,可能会以极端的方式变形。另外对于图像的各种变形操作也会使得其中的物体变形。4. 遮挡。感兴趣的对象在图像中可能会被遮挡,有时甚至只有一小部分对象(只有少数像素)可见。5. 照明条件。照明对像素的影响非常剧烈。6. 背景杂乱。感兴趣的物体可能混入其背景之中,使其难以识别。7. 类别中的差异性。关注的类别可能是一个比较宽泛概念,如椅子。这些对象有许多不同的类型,而每种都有自己独特的外观。
........
2.2 异常事件检测
2.2.1 视频异常事件检测问题
异常事件检测旨在检测特定场景下的异常情况,在卫生监测、公安和行人监测中得到广泛应用。虽然过去几年研究人员在这方面做了大量的研究[31-35,38],但问题仍然存在。异常事件检测问题依然具有挑战性,主要有三个原因:第一,缺乏异常事件的基准数据。现有的异常事件检测数据集很少对异常样本进行标注,特别是异常事件的位置,需要进行像素级的判定。所以由于缺乏数据,很难对异常事件采用监督学习算法。 第二个原因是缺乏明确和客观的异常事件定义。例如火车站的监控视频,人群四散逃跑应该被认作是异常事件,但是很难区别因赶时间而小跑的旅客。另外,前两个问题是相互关联的,因为主观地定义异常事件性使得收集异常事件基准数据更加困难。第三,相对于正常情况,有太多的事件都可以被定为异常事件。对于一个街道监控视频,正常情况就是行人行走,但是异常情况的出现就有太多的可能了:有交通工具驶上了人行道,行人摔倒在地等等。所以很难像正常情况那样,针对异常事件训练一个普适的模式。
.........
第三章 多示例学习在图像分类与检索中的研究.......... 16
3.1 问题的定义 .............. 16
3.2 提出的方法 .............. 16
3.3 实验 .... 23
3.3.1 数据集、特征以及评级标准 ......... 23
3.3.2 参数选择 ........ 24
3.3.3 性能分析 ........ 25
3.4 本章小结 ....... 30
第四章 多示例学习在视频异常事件检测中的研究...... 31
4.1 问题定义 ....... 31
4.2 提出的方法 .... 31
4.2.1 基于图的多示例学习 .......... 33
4.2.2 锚点字典学习 ........... 35
4.3 实验 .... 37
4.3.1 数据集、特征以及评级标准 ......... 37
4.3.2 参数选择 ........ 39
4.3.3 性能分析 ........ 39
4.4 本章小结 ....... 44
第五章 全文总结与展望...... 45
5.1 全文总结 ....... 45
5.2 后续工作展望 .......... 46
第四章 多示例学习在视频异常事件检测中的研究#p#分页标题#e#
4.1 问题定义
针对 2.2 节中提出的现有异常检测算法所存在的问题,本文给出了相应的解决办法。首先针对缺乏异常事件的基准数据,我们采用多示例学习模型,从而使得我们算法仅仅使用视频的标签,而不用帧的标签;然后针对包含异常事件的数据,我们从两个方面来使用他们,第一是经过示例选择,把其中一部分示例作为多示例分类器的正训练样本,训练出一个粗分类器,该分类器功能即是快速判断是否和正样例相似,另一方面,我们同样是采用的字典学习来学出正常事件的模板,但是将选出的正示例用于改进字典学习的效果;针对字典学习算法耗时较大的问题,我们采用了双层检测的策略,首先用多示例分类器快速地进行检测,如果是异常的,则用学习到的字典进行更加精细地评分。
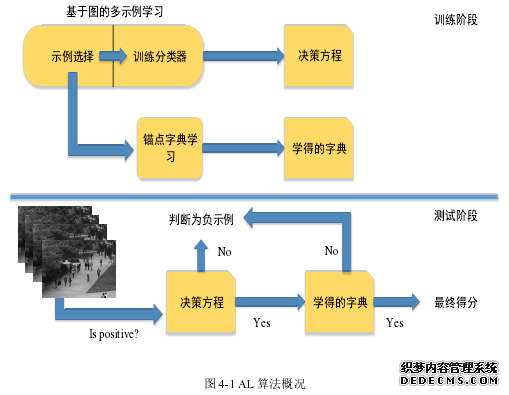
...........
总结
本文将图像分类与检索和视频异常事件检测作为两个任务,研究了多示例学习在计算机视觉领域的应用。根据不同的任务,我们提出了两个相应的多示例学习模型,CMIL 与 AL,通过实验证明了两个算法具有优秀的性能,说明了多示例学习在计算机视觉领域有非常好的应用价值,全文主要内容如下:
1. 本文首先回顾了多示例学习在计算机视觉领域的应用情况,提出了存在的几个挑战,并给出了对应解决策略。
2. 针对图像分类与检索任务,我们首先将任务转换多示例学习问题,再建立基于示例选择的多示例学习模型。为了改进示例选择,我们采用了聚类的策略来充分利用特征空间的结构信息。通过利用隐含的结构信息对正包中的示例进行聚类,在对后续操作进行剪枝的同时保持了结构信息。通过与对比算法的比较,证明聚类策略显著地减少了时间开销。
3. 为了量化示例之间的关系,我们构建了相似性关系图,通过相似性、差异性和一致性这三个方面来考察示例之间的关系,并以此为依据进行了示例推理。根据实验结果的分析,该算法有较好的鲁棒性。
4. 在处理图像检索时,我们进一步将多示例学习模型拓展至多视图特征空间,通过多视图聚类算法,以及联合建立相似性关系图,使得示例选择能够基于多视图的信息完成。在训练阶段我们采用了 MK-SVM 作为分类器来利用多视图特征。实验结果表明,多视图特征的引入对算法效果有很显著的提升。
5. 建立示例的关系图,特别是涉及较大数据集时,会消耗大量的运行时间;但经过聚类处理后,每个簇都是相对独立的。所以针对这个特点,我们在实现算法时采用了并行化处理,大幅减少了运行时间,使得算法具有处理大规模数据的能力。
..........
参考文献(略)

