本文是一篇计算机论文,计算工具的演化经历了由简单到复杂、从低级到高级的不同阶段,例如从“结绳记事”中的绳结到算筹、算盘计算尺、机械计算机等。它们在不同的历史时期发挥了各自的历史作用,同时也启发了现代电子计算机的研制思想。(以上内容来自百度百科)今天为大家推荐一篇计算机论文,供大家参考。
第一章 绪论
1.1 论文研究背景及意义
随着互联网的普及,近年来不断发生的食药安全事件引起了广泛关注。2015年 6 月 1 日,海关总署开展打击走私冻品专项行动,打掉 21 个走私冻品犯罪团伙,查获了 42 吨“僵尸肉”。 2016 年 3 月爆发的山东毒疫苗事件引起舆论热潮,医药行业陷入前所未有的重大危机。2016 年 3 月 18 日,山东疫苗案件被曝光后,互联网对该事件的关注度持续上升,据新华网舆情监测系统显示,2016 年 3 月 22 日当天新闻信息量超过 7900 条,总信息更新量超过 12000 条。2017 年 6 月 1 日,通州小营村一处冷藏库将进口冷冻猪肉卖给北京几个郊区的黑作坊,部分冷冻猪肉已加工成熟食送往市场。各种食药安全类突发事件频繁发生,给公众的生活带来了极度的恐慌和不安。在互联网背景下,食品药品安全舆情具有时效性强,影响巨大等特点。食品药品安全与人们的生活息息相关,一旦相关事件被爆出,就会在短时间内得到迅速传播。由于公众对食药安全话题的参与度极高,食药安全突发事件引发的网络话题和舆情热点,往往会迅速放大事件影响,个别事件甚至会引起全国舆论浪潮。针对食品安全突发话题的检测是食品安全研究的重点,目前突发话题检测的主要方式有两种[1],一种是基于内容特征的方法,这种方法基于突发关键词[2]或基于概率主题模型[3,4]对突发话题进行检测,另一种方法是基于信息传播模型的方法,这种方法是通过信息传播模型将信息的元数据抽象成结点,通过一定的信息传播模型进行突发话题的检测。两种方法各有优点和缺点,基于内容特征的方法可以大大降低数据的规模,但是突发话题被检测出的时间较大地滞后于话题实际发生的时间,而基于信息传播模型的方法能从微观层面更早地检测出突发话题,但是准确性的好坏很大程度上取决于传播模型的好坏和用户间传播影响力的计算且需要丰富的历史传播数据进行模型的训练,这对数据的收集和处理都提出了较高要求。针对食品安全问题的报道可能来自不同类型的网站,有的来自新闻网、更多的报道可能来自于社交媒体,例如微博、微信、博客、论坛等等,如今使用社交媒体的用户数量正逐年递增,人们更喜欢通过社交媒体来传播和共享信息,到目前为止,仅微博一家社交媒体的用户月活跃人数就高达 3.76 亿[5]。文献 [6]的实验结果发现大多数类型的报道,例如恐怖袭击、冲突、意外、自然灾害等,社交媒体的报道是先于新闻网站的,然而,对于某些类型的报道,新闻网站的报道却比社交媒体的报道来得更加及时,例如体育、文化、政治等话题的报道。
..........
1.2 国内外研究现状
随着社交媒体的不断发展,国内外关于话题检测的技术研究的处理对象多与社交媒体数据相关。在长文本方面,国内外的话题检测多以新闻数据作为研究对象,国外主要的新闻网站有美国有限电视新闻网(CNN)、雅虎新闻(Yahoo! News)等,而国内主要的新闻网站有新浪、搜狐、网易、头条等,这些新闻网站每天都会产生大量数据。在短文本方面,twitter 作为国外社交的重要平台,据《twitter 财报》报道,2017 年第三季度 Twitter 月活跃用户数 3.3 亿,同比上涨 4%[7],所以在国外的话题检测研究中,多以 twitter 数据作为处理对象,而国内相对应的则是微博,根据《新浪微博数据中心:2017 微博用户发展报告》统计,2017 年 9 月,微博月活跃用户达到 3.76 亿,与 2016 年同期相比增长 27%[5]。在国外,针对突发话题的研究开始的比较早,研究技术相对成熟,涉及多种技术路线,包括基于聚类、频繁模式挖掘、基于 Exemplar、矩阵分解和概率主题模型的技术方法[8]。在国内,从 2008 至 2017 年,网络舆情突发话题检测研究的相关文献逐年增多,近几年更成为舆情挖掘领域的研究重点。目前针对社交网络中的突发话题研究中,大部分都只基于单一数据源,由于长短文本特点不同,传统的长文本研究方法对于短文本来说不适用,反之,亦成立,因此学者们通常只针对一种文本类型进行研究,鲜有人考虑以多源数据相结合,以长短文本融合的方式进行话题检测研究。但有研究表明[6],由于不同的信息来源对于不同类型的话题报道有早晚之分,有的话题报道传统的官方新闻网站早于微博、知乎等社交媒体,而有的话题则由社交媒体先行发声,所以能够综合多源数据,结合长短文本的不同特点来检测突发话题,可以增加突发话题检测的数量和提高检测结果的质量,因此,未来的研究方向必定趋向于结合传统媒体与社交媒体的方式,综合长短文本的特点来研究舆情挖掘中的突发话题检测技术。
........
第二章 相关理论与技术
此章节将概括性地介绍论文涉及的相关技术理论,包括数据预处理、文本特征词提取与表示和话题检测技术三部分的内容。数据预处理部分主要介绍不同分词技术的优缺点以及用于发现字符串短语的频繁模式发现算法,文本特征提取与表示部分主要阐述当前应用于特征提取的方法、几种文本表示模型以及文本相似度度量方法,话题检测技术部分重点阐述用于话题聚类的不同算法及其优缺点。
2.1 数据预处理
原始数据往往存在一些问题,如数据不一致、重复、含噪音等问题。为了方便进一步的数据挖掘分析,必须对原始数据进行预先处理。数据预处理指的是对原始数据进行分类或分组前所做的审核、筛选、排序等必要的处理,数据预处理有多种方法,包括数据清理,数据集成,数据变换,数据归约等,而中文数据预处理中最重要的方法是数据清理,数据清理包括分词、去停用词(包括标点、数字、单字和其他无意义的词)、命名实体识别等阶段。词是最小的独立运用单位,西方语言中往往可以通过显示的标志来区分单个词,如英文可以通过空格来区分单词,而中文词之间没有明显的标示词边界的符号。因此,自动分词问题是计算机在处理中文文本上所面临的首要工作。近十年以来,国内外许多研究人员都对中文分词进行了研究,并且发表的大量的论文和专著,到目前,已经有较为成熟的自动分词技术。目前中文分词包括基于词典、基于语法规则和基于统计等三种方法。基于词典的方法的基本思想是利用词典或词库对待分词的字符串进行匹配的方法。常用的有正向最大匹配法,逆向最大匹配法和最少切分法,但是单纯使用任何一种匹配方法,其精度还远远不能达到实际要求,切分的准确率很低。基于语法规则的中文分词方法的基本是想是利用计算机来模拟人对句子的理解,为了消除歧义,在分词的同时加入了语法和语义等分析。但由于这种分词方法需要大量的语言知识和信息以及中文语言本身的复杂性使得基于语法规则的分词系统还处于试验阶段。基于统计的方法是目前最流行的自动分词方法,它是利用字与字之间的相邻共现概率来衡量词的可信度,即字与字之间相邻共现概率高的更容易成为一个词。
..........
2.2 文本特征词提取与表示
在文本分类领域,包括无监督的聚类和有监督的分类,原始的文本中可能由几十万甚至上百万个中文词条组成,维度相当高。为了提高文本分类的准确率和有效性,一般需要提前对文本进行降维,剔除一些不重要的词或短语,这就是文本特征词提取的过程。文本特征词提取算法有许多,包括信息增益(IG)、卡方校验、TF-IDF 等等,其中使用最广泛的为 TF-IDF 计算方法。而文本表示就是对文本特征加权,将文本表示成数学向量的过程,目前的文本表示模型有概率主题模型、图空间模型、布尔模型以及向量空间模型,其应用最广泛的是向量空间模型。在文本分类领域,TF-IDF(Term Frequency–Inverse Document Frequency)作为特征降维或特征提取的算法,TF-IDF 的主要思想认为某个词在一篇中文档中出现的概率越大,即词频 TF 越高,而在其他文章中很少出现,则说明这个词具有很高的辨识度,即重要性越高。通常 TF-IDF 越高的词或短语在原始语料中的重要性越高。TF-IDF 实际是 TF*IDF,TF 表示词频,即词条在文档 d 中出现的频率,IDF表示逆文档词频。
...........
第三章 可变长文本的图结构模型............ 22
3.1 基于 WORD2VEC 的主题爬虫算法........... 23
3.2 话题关键词选取与特征提取........ 26
#p#分页标题#e#
3.3 可变长文本的话题网络构建........ 29
3.4 本章小结....... 30
第四章 话题聚类与突发话题检测............ 32
4.1 话题聚类....... 32
4.2 突发词和重要词...... 34
4.3 基于图结构模型的突发话题检测........... 36
4.4 本章小结....... 40
第五章 实验结果与分析...... 41
5.1 开发环境说明.......... 41
5.2 实验数据集.............. 41
5.3 食药安全主题爬虫算法实验与分析....... 45
5.4 特征提取实验与分析......... 46
5.5 基于图结构模型的话题检测实验与分析.......... 49
5.6 基于图结构模型的突发话题检测实验与分析............. 55
5.7 本章小结....... 58
第五章 实验结果与分析
本章将对论文提出的基于 word2vec 的主题爬虫算法、话题检测和突发话题检测等方法进行实验,并与其他方法的结果进行对比分析。
5.1 开发环境说明
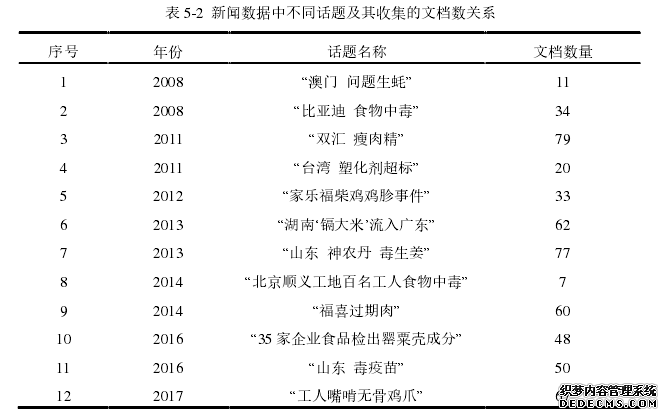
本论文是在 Windows10(64)操作系统的 PC 机上运行的,该 PC 机的处理器为x64, CPU 为英特尔处理器,共有 8G 内存和 500G 硬盘容量。开发 IDE 使用的是Eclipse 2013 版,数据库使用 MySQL Server 5.6,分词工具采用 ICTCLAS5.0。具体配置环境如图 5-1 所示。实验采用两种数据集:面向食药安全主题的数据集和中文突发事件语料库—CEC(Chinese Emergency Corpus)[44],两种数据集中均包含两种类型的数据—新闻和微博数据,面向食药安全主题的数据集用来评估话题检测方法的性能,而CEC 语料用于研究突发话题检测实验。本文以“双汇瘦肉精”,“台湾塑化剂超标”等 12 个话题为关键词收集了 548 条新闻数据,以“毒生姜”,“湖南‘镉大米’流入广东”等 9 个话题为关键词收集了 1098条微博数据。数据集基本信息如表 5-1 所示,新闻和微博数据中不同话题及其收集的文档数关系如表 5-2 和表 5-3 所示,数据样例如图 5-2 和图 5-3 所示。
.......
结论
论文研究以互联网上的 Web 多源数据为数据源,包括以新闻为代表的长文本数据和以微博为代表的短文本数据,提出了基于 word2vec 的主题爬虫算法,专门收集有关食药安全主题的数据作为处理对象进行突发话题的检测,重点对话题的关键要素识别和特征提取、可变长文本话题检测以及突发话题检测等技术进行了研究。在特征提取、可变长文本的话题聚类和突发话题检测等方面提出了较大改进,并在实验部分进行有效验证分析。
1)在话题关键词选取阶段,论文采用后缀数组的数据结构对中科院的ICTCLAS 分词技术进行了二次分词组合,使得分词不会过细,获得了可以表达完整语义的有意义串,再将有意义串放入用户词典,通过抽取命名实体的方式来选取出相应的话题关键词作为候选特征词。在特征提取方面,论文首先对传统的TF-IDF 和 TF 词权重计算方法进行了改进,提出了根据特征词所在文本位置的不同对其权重进行加权求和的方式来提高特征提取的准确度,获得了新的词权重计算方式 WTF-IDF 和 WTF。最后,针对不同类型的文本论文选取不同的特征选取依据,如新闻等长文本使用 WTF-IDF 值计算特征词权重,而微博等短文本采用 WTF值计算特征词,并在此基础上,根据长短文本的不同,选取不同个数的特征词。
2)在可变长文本的话题聚类方面,论文提出了一种词共现关系的图结构模型,用文章中不同的特征词来代表图模型中不同的结点,用词共现关系来表示结点之间的连边,即如果两个特征词在同一篇文章中出现,则相应结点有连边,反之,相应结点没有连边并用两个特征词在同一篇文档中出现的次数来代表连边权重,最后利用基于模块度的社团划分方法实现该图结构模型的话题聚类过程。该模型充分利用了词共现关系,实现了可变长文本的话题聚类和大规模文本语料的快速聚类,克服了传统方法需要区分长短文本分别进行聚类和提前训练语料的缺点。实验效果话题的召回率高达 0.857,明显优于其他方法。
..........
参考文献(略)

