第一章绪论
本文对越南语名词短语进行了详细分析,在语言学部分进行了大量语料标注与语言学分析工作。在前期语言学分析的基础上,本文将越南语名词短语语言学特征分别融入到CRF 模型与 Bi LSTM+CRF 模型当中,并对模型进行了几点有意义的改进。本文立足于越南语名词短语识别的应用场景,结合越南语名词短语的语言学特点,对越南语名词短语进行了研究与限定。在此基础上,本文人工标注了一定规模的越南语语料进行了人工校对,形成了越南语名词短语标注语料库。以此语料库为根据,本文对越南语名词短语的内部词性构成、内部词性组合模式与边界进行了统计调查,得到了越南语名词短语的语言学特征。为了解决越南语名词短语标注语料不足而人工标注又耗时费力的问题,本文探索将越南语名词短语的语言学特征融入到统计模型当中,并分别针对 CRF 模型与 Bi-LSTM+CRF 这两种常见的统计模型设计了融入语言学特征的思路和方法。整体框架如下:第一章:绪论。该部分介绍了本文的研究背景与意义、研究对象与研究方法,对国内外的相关研究情况进行了梳理总结,并归纳了现有研究存在的不足和本文对这些不足的改进方向。第二章:越南语名词短语研究。主要包括对越南语语言特点的总结、越南语名词短语的定义及定性定量描述、研究对象的限定说明以及对越南语名词短语语言学特征的调查分析。第三章:基于规则的越南语名词短语识别。该章作为承上启下的部分,根据越南语名词短语的定量统计分析结果,将名词短语内部结构以及边界特征形式化为相应的语言学规则对越南语名词短语进行识别。通过对识别结果进行分析,为下一步应用统计识别方法做铺垫。
.......
第二章 越南语名词短语研究
2.1 越南语语言特点
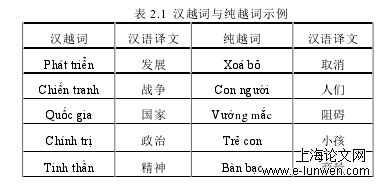
越南语是一种孤立语,属南亚语系孟高棉语族越芒语支①。越南文字先后经历过两次变化,即由开始时的汉字,到后来结构更加复杂的喃字,再到目前的拉丁文字——国语字。越南受汉文化影响较大,越南语同汉语也具有一定的相似性,主要表现为以下四点:(1)在文字表示上,两种语言都以字为基本书写单位,并且词与词之间并没有明显的分隔标记,因此在进行自然语言处理任务时往往要先进行分词处理。在上面这句话中,一个越语字正下方是其所对应的汉语字,句子整体的汉语翻译为“越南语是越南的正式语言”。要对这句话进行自动处理,就必须先对其进行分词,这与汉语非常相似。越南语中保留了大量的汉越词,这些汉越词无论是发音还是结构都与汉语非常相似。如表 2.1 所示。
2.2 越南语名词短语
为了解决这个问题,本文从现有的语言学理论出发,结合越南语名词短语识别的应用场景,对越南语名词短语进行限定。由于现有越南语语言学研究并未对越南语名词短语做出分类,本文参考周强和孙茂松等人对汉语名词短语的界定[16],将越南语名词短语分为最长名词短语、最短名词短语与一般名词短语。其中,最长名词短语指的是不被其他名词短语所包含的名词短语,最短名词短语是指内部不包含其他任何名词短语的名词短语,一般名词短语则是除去这两种短语类型之外的名词短语。可以看出,越南语最长名词短语是颗粒度最大的名词短语,越南语最短名词短语是颗粒度最小的名词短语。接下来,本章将对越南语最长名词短语的构成从定性与定量两个角度进行分析,进而为本文研究对象的限定奠定语言学理论基础。
.......
第三章 基于规则的越南语名词短语识别.............31
3.1 越南语名词短语规则识别算法............... 31
3.2 实验设计.................. 34
3.3 实验及结果分析...... 35
3.4 规则识别方法总结................. 36
3.5 本章小结.................. 37
第四章 基于条件随机场模型的越南语名词短语识别......39
4.1 CRF 简述 ................. 39
4.2 实验设计.................. 39
4.3 融合越南语名词短语边界特征的越南语名词短语识别..... 40
第五章 基于深度学习方法的越南语名词短语识别..............47
5.1 Bi-LSTM+CRF 模型.................47
5.2 越南语词向量与词性特征向量获取 ...................48
.........
第六章 识别模型中语言学特征对比及有效性分析
6.1语言学特征在 CRF 模型与深度学习模型中效果对比分析
本章在第四章 CRF 模型、第五章 Bi-LSTM 模型识别的基础上,对不同语言学特征融入两种统计模型的实验结果进行对比,具体如表6.1所示。其中,由5.4与5.6可知,BS Vector2 对本文所用深度学习模型的支持作用要优于 BS Vector。为此,本章选用 BS Vector 2 为越南语名词短语边界信息进行相似度建模。从表 6.1 各项指标的对比结果可以看出:(1)在本文采取的所有方法中,以预训练词向量、词性特征向量与 BS Vector 2 作为输入的 Attention-over-Input Layer+Bi-LSTM+CRF 架构的识别效果最佳,对越南语名词短语识别准确率达到 91.65%,召回率达到 92.48%,F 值为 92.06%。(2)词性特征、越南语名词短语边界特征等语言学特征对于两种统计模型的识别效果均有正向提升作用,且语言学特征数量的增加与识别效果的增强成正比关系。这体现了语言学特征在识别任务中的重要性。尤其是在深度学习条件下,虽然深度学习方法自身能够对特征进行抽象与提取,以此降低了模型对人工特征工程的依赖,但总体实验结果表明,外部特征依然能够提升深度学习模型的识别能力,深度学习在语言学特征抽象与提取的完成度上依然有不小的提升空间。这体现了深度学习时代语言学研究的价值。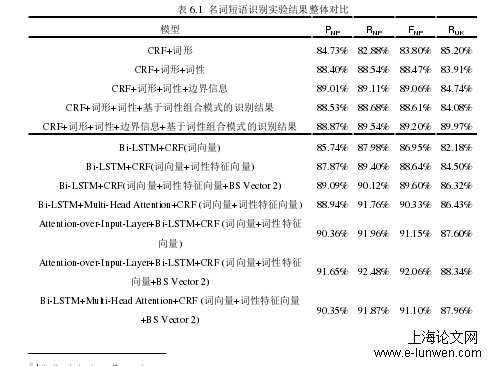
6.2 越南语名词短语识别任务中边界特征有效性可视化分析
与 Viet-NP-Embedding 相似度最高的词汇虽然名词占据了大多数,但这些名词之间没有语义上的联系。与 Viet-NP-Embedding 相似度最高的前七个词全部是名词,但这些名词在语义上的分布非常分散,既有网络通信方面的词汇,如“UMB”,也有农业生产方面的词汇,如“LTTP”,还有国际关系方面的词汇,如“H ”。这进一步说明Viet-NP-Embedding 所包含的是名词整体的语义信息,而在名词范围内,其没有明确的指向性。总体来看,本文所训练得到的 Viet-NP-Embedding 在一定程度上可作为越南语名词短语整体的向量化表示,将其与每个词向量进行相似度建模能够表示每一个词与名词短语的相似度,从而一定程度上反映该词能否作为名词短语的构成成分。因此本文所得的相似度确实为深度学习模型提供了更多的信息。
...........
第七章 总结与展望
本文以越南语名词短语识别为任务,通过加强现有识别模型对越南语名词短语语言学特征的应用,提升了越南语名词短语识别的效果。从整体来看,本文研究内容可以分为三部分:第一部分是对越南语名词短语的语言学研究;第二部分是以第一部分语言学研究为基础的越南语名词短语识别研究;第三部分是对第二部分的对比分析与总结。语言学研究部分,通过对越南语名词短语的内部词性构成、内部词性组合模式、左右边界词与左右边界词性进行统计调查,揭示了越南语名词短语的内部词性与外部边界特征,并形成了越南语名词短语内部词性组合模式库等五大语言知识库。在此基础上,设计了基于越南语名词短语内部词性组合模式的动态识别算法与基于越南语名词短语边界词性的筛选算法来对越南语名词短语进行识别。通过使用规则识别算法对越南语名词短语进行识别,归纳出越南语名词短语识别的难点与关键点,并为本文后续使用统计模型对越南语名词短语进行识别提供依据。此外,该部分还对本文得到的越南语名词短语语言学特征与词性等普通语言学特征的异同点进行了分析说明。
........
参考文献
[1] Le Minh Nguyen, Huong Thao Nguyen, Phuong Thai Nguyen, et al. An empirical study of Vietnamesewww.zhonghualw.com noun phrase chunking with discriminative sequence models[C]//Proceedings of Workshop on Asian Language Resources, 2009:9-16.
[2] Thao N T H, Thai N P, Minh N L, et al. Vietnamese Noun Phrase Chunking Based on Conditional
Random Fields[C]//Proceedings of International Conference on Knowledge and Systems Engineering. IEEE Computer Society, 2009:172-178.
[3] 郭剑毅, 李佳, 余正涛. 基于约束条件随机场的越南语名词组块识别方法:中国,CN 107797994 A[P]. 2018-03.13.
[4] Abney S. Partial Parsing via Finite-State Cascades[J]. Natural Languagewww.zhonghualw.comEngineering, 1996, 2(4): 399-399.
[5] Ramshaw L A and Marcus M P. Text Chunking using Transformation-Based Learning[C]//Proceedings of the 3rd ACL/SIGDAT workshop, 1995: 222-226.
[6] Ngai G and Florian R. Transformation-based learning in the fast lane[C]//Proceedings of the Second Meeting of the North American Chapter of the Association for ComputationalLinguistics on Language Technologies, 2001: 1-8.
[7] 张昱琪, 周强. 汉语基本短语的自动识别[J]. 中文信息学报, 2002, 16(6): 1-8.
[8] 李珩, 朱靖波, 姚天顺. 基于 SVM 的中文组块分析[J]. 中文信息学报, 2004, 18(2): 2-8.
[9] 徐中一, 胡谦, 刘磊. 基于 CRF 的中文组块分析[J]. 吉林大学学报(理学版), 2007, 45(3): 416-420.
[10] 刘芳, 赵铁军. 基于统计的汉语组块分析[J]. 中文信息学报, 2000, 14(6): 28-32.
...........

