本文是通信工程论文,本文的研究成果主要包括以下几个方面:(1)本文根据对专利分析方法的研究,简要论述了传统专利分析方法,与传统方法不同的是本文借鉴了文本挖掘技术的思想,提出使用基于BERT模型的自然语言处理技术对专利文本进行分析的方法,设计并实现了以文本生成的方式对大量专利文本的关键内容进行自动式生成。(2)本文在垃圾分选专利预处理过程中,使用自己制定的语料库与停用词列表,不断完善垃圾分选专利的语料,使整个处理过程中处理模型更具有专业性,能够学习到更多专业知识信息。本文创新点主要包括以下两个方面:(1)本文针对专利文本内容分析提出基于辅助文档自动生成的方式实现对专利文本内容信息的阅读归纳与总结,并设计了BERT-Attention-LSTM处理及生成模型(简称BAL模型)。同时对模型训练的模式进行改进,提出基于预学习的训练方法。针对BERT训练模型进行研究,在文本分析与处理中,对于文本的特征向量化表示是至关重要的,作为NLP技术中的上游任务其结果直接影响后续工作的结果及进展。本文采取BERT模型作为我们的特征提取器,基于特征和基于微调融合的方式去训练模型。同时,使用双层LSTM作为文本生成器,并在两者之间引入Attention机制以保证每一个时间步都不会丢失信息,从而实现专利辅助文档的生成。针对BERT-Attention-LSTM模型结构在第4章进行详细讲述。本章首先详细阐述了课题研究背景以及研究的意义,然后从三个方面对国内外研究现状进行分析。最后,根据本文所要研究的内容做出了整体的规划与安排,并详细介绍了论文主要研究的内容与论文撰写框架。
.....
第1章绪论
本学位论文的课题研究来源于廊坊市科技局基于专利大数据技术信息挖掘关键技术的研究课题。本论文的研究内容主要是对自然语言处理技术在专利文本处理及分析中的应用进行研究,其中包括自然语言处理技术在专利分析中的应用研究以及处理分析模型的研究两大部分。重点研究了NLP技术中的训练模型BERT以及文本生成方法。并且根据现有技术及条件,本文提出一种新颖的专利文本内容处理及分析方式,采用BERT与LSTM相结合并在其中加入Attention机制的方式实现对垃圾分选专利文本的处理,并最终生成专利辅助文档。具体研究内容如下:(1)垃圾分选专利文献以及专利分析方法研究,主要对专利文本内容分析方法进行研究。专利文献的研究包括对专利文本结构组成,专利文本内容特性,以及本文实验研究对象垃圾分选专利的研究,包括垃圾分选专利的技术种类,技术构成,应用场景等。而对于专利文本分析的方法的研究主要是内容处理及分析方法如文本聚类方法、文本分类方法、主题提取方法、自动摘要生成方法等。(2)针对目前自然语言处理技术(NLP)的研究,其中包括熟悉自然语言处理流程,该技术的具体应用,进行特征向量化的处理模型以及可结合的分析手段等。并根据研究内容制定出基于NLP技术的垃圾分选专利进行处理与分析的完整处理及分析的流程,其中包括了文本数据的预处理,模型的搭建,模型训练,结果评价与分析等具体任务。
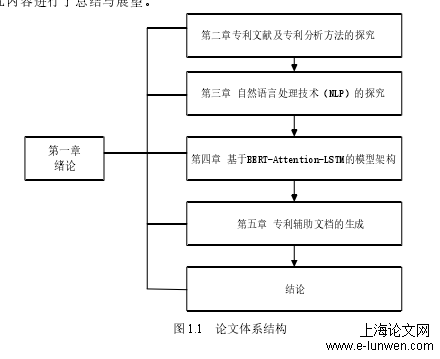
论文体系结构
........
第2章专利文献及专利分析方法的研究
2.1垃圾分选专利文献
专利文献具有巨大的信息价值以及经济价值,专利是世界上最大的技术信息源,专利包含了世界全部科技信息的90%~95%[31]。国家知识产权局局长申长雨[32]在以“专利运用新业态支撑经济发展新常态”为主题的专利信息年会上指出,要实现专利信息服务与互联网和大数据的深度结合,借助大数据对专利数据信息进行深度整合、加工、挖掘、处理,使得更有价值的隐性信息浮出水面。本课题选取垃圾分选专利作为实验研究对象,垃圾分选专利是垃圾分选技术的核心体现,其凝聚了垃圾分选技术的精华,包含了该技术设备的核心组成。目前,大多数垃圾分选专利多为生活垃圾分选专利,分选主要以减量化、资源化、无害化为目标,以一种科学且持续的处理方法,最大程度的减少垃圾存量从而改善生态环境[33]。宏观上垃圾分选有简分选与细分选之分。其中,简分选目的在筛选出出可燃物与填埋物。而细分选则是以回收塑料等可循环资源为目的,筛选出可腐物并进行下一步处理。常见的垃圾分选技术主要包括筛分、重力分选、浮力分选、磁力分选、电力分选等。近年来随着科技的发展还出现一些新的垃圾分选技术,如图像识别分选、变重分选等。目前,我国垃圾分选的技术针对国内不同地域垃圾特性已经形成了适应的工艺与成套设备体系,在本文中我们针对的主要是北方区域的垃圾分选。垃圾分选技术的新进技术主要是在匀料、大型垃圾的机械抓取、复杂缠绕物分离、破袋、循环风风选等单元上进行了突破,并且在设备系统集成上更进一步。而精分等方面垃圾分选技术还是有待进一步的突破,在实际应用中,面对一些疑难杂症问题的解决垃圾分选技术的处理能力还处于初级阶段,需要进一步的完善。
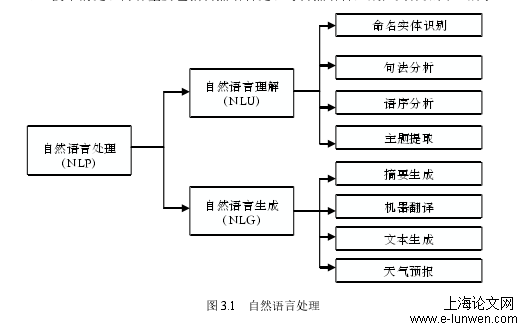
自然语言处理
2.2专利内容分析方法及其存在的不足
传统的专利文本内容分析方法多以分类分析与聚类分析为主,以统计学的思想对文本内容进行分析处理。在分析过程中对关键技术词或者主题词进行提取,通常以出现的频率或者出现的位置将其视为关键词,而这种不确定因素明显较多,而关键词在实现分类、聚类、主题提取,或者摘要的生成等任务又发挥着极其重要的作用。而且数据量的增多也使得传统对词进行定位以及进行特征向量化的方法显然力不从心.同时,采用非Transformer架构传统自然语言处理模型,其特征化向量是一成不变的难以满足文本序列的处理要求,而且在面对大数据量的专利文本时,传统的处理能力与处理效果愈发无力。作为文本这种非结构化数据,并且是一种语言文本,存在着文本内容分析的相关问题。而对于文本内容的分析不能局限于基于词频的词条统计、基于关键词的分类与聚类等操作。应考虑更多的是词序,词义,上下文联系等因素对分析的影响。本文首先从专利文本分析所涉及的技术入手,专利文本的分析通常包括专利文本的处理以及通过某种分析手段对处理过的数据信息再次进行加工,并最终实现具体任务所需要的功能。通过研究发现,就语言的处理而言,自然语言处理技术(NLP)是一项发展较为成熟的技术体系,其融合了统计学,语言学,概率论,计算机科学等学科。NLP技术包含了语言的处理以及语言的生成,对于专利文本而言,NLP技术的应用是一个研究热点。通过研究发现,在NLP处理任务中BERT模型的训练效果明显优于非Transformer模型,并且在11项NLP任务中夺得STOA结果。因此,本文选取BERT模型作为核心处理模型,并提出BERT模型结合LSTM神经网络对专利文本进行文档自动生成的分析
第3章自然语言处理相关技术的研究..............................................................................12
3.1自然语言处理(NLP)技术介绍................................................................................12
3.2自然语言理解(NLU)的研究...................................................................................12
3.3自然语言生成(NLG)的研究...................................................................................18
第4章基于BERT-Attention-LSTM的模型结构..............................................................12
4.1BERT模型介绍及其目标任务....................................................................................24
4.2Transformer架构..........................................................................................................24
4.3BERT的模型实现与操作............................................................................................33
第5章专利辅助文档生成实验..........................................................................................40
5.1实验模块设计...............................................................................................................40
5.2模块功能实现...............................................................................................................41
.........
第5章专利辅助文档生成实验
5.1实验模块设计
本文根据研究内容对本实验进行模块化设计,将本实验化分为以下几个功能模块:(1)数据获取及格式转换模块通过专利检索平台下载到本地100篇pdf格式的垃圾分选专利。在该模块中,我们要将pdf格式专利文件转换为txt文本文件,作为我们的数据源文件。(2)数据集预处理模块在该模块中,我们将转换格式后的txt垃圾分选专利文本,通过Python代码编写程序导出垃圾分选专利中的发明内容部分内容,并保存至以标号CN开头的txt文本中,生成CN001-CN100分别标号的垃圾分选专利发明内容。使用主题模型(LDA模型)对其进行分类合并,根据分选技术对其进行分类合并处理,最后生成实验数据集。(3)模型搭建模块IDE以Anaconda3(64bit)为运行环境,搭建Tensorflow运行框架。配置相关Python函数库,其中包括Numpys,Scipy,Pandas等。搭建Bert_Models_chinese_L_12_H_768_A_12模型,以及双层LSTM神经网络。(4)模型训练模块整体采用Encoder-Decoder实现文本序列到文本序列的深度学习框架模型,以BERT模型作为编码器,Decoder作为解码器,并在其中加入Attention机制。选取数据集中80%作为的训练集进行训练。其余10%作为验证集,10%作为评价系统的对比文本。(5)评价指标模块针对生成的文本主要从三个方面进行评估,分别是文本多样性,语义相似性,生成式摘要三个方面对其进行评估。依据实验研究模块内容制定出本实验整体步骤图,具体如图5.1所示:该方法与传统统计学的思想理念不同,旨在通过内容对专利文本进行分析,该文档的生成是在大量专利文本内容下由机器不断阅读和学习得到的。通过大量同一技术主题的专利文本的训练,使得其生成的文档更具有代表性与归纳性。实现机器去阅读并理解专利文本,最终并能够自动生成专利的辅助文档。
自然语言处理
5.2功能模块实现
在BAL模型中我们使用BERT作为特征向量提取模块来接收输入的文本序列,经过较为复杂的向前传播,输出特征向量表示。而后LSTM文本生成模块根据特征提取器提取到的特征信息生成目标文本序列。尽管两部分功能不尽相同,但是其上层网络功能的实现均要基于词嵌入。(1)因此,我们首先使用BERT训练好的模型参数中的词嵌入层用以初始化LSTM神经网络的词嵌入层,因为BERT模型训练的嵌入层参数已经趋于完善。(2)然后,使用进行处理过后的垃圾分选专利语料以语言模型的形式单独训练我们的LSTM神经网络,由于BERT模型训练的嵌入层参数已经趋于完善,这样我们就可以将LSTM文本生成模块嵌入层的参数固定,使其不进行更新。通过此操作,文本生成模块能够更好的学习垃圾分选专利语言领域知识,使其更具有专业性。(3)接下来,我们使用注意力机制将预训练好的特征信息提取模块与与训练好的LSTM文本生成模块进行关联,在这里强调,如果将上一个模块的结果不进行关联直接作为下一个模块的输入会导致其信息的丢失,因此需使用注意力机制将其关联。最后我们用处理好的垃圾分选专利文本数据集对整个模型进行训练,训练整个模型的参数。(4)在fine-tuning(微调)阶段,主要涉及的是学习率,batch_size,epochs。其中模型更新使用的学习率要比预训练阶段的值要小,这样才可以保留两模块在预训练阶段所学到的经验知识。在进行模型的训练中我们将模型的训练过程大体上分为两个部分:预训练阶段以及微调阶段。接下来分别对两个阶段进行讲述:(1)预训练阶段:在模型预训练阶段,首先使用本文提出的基于多篇垃圾分选专利构成的数据集,根据上述训练方式进行训练。我们的语料分词方法采用Jieba分词器,单词表大小保留。我们的BERT模型是12层,头数是12,隐藏层的维度是768。文本生成模块的LSTM神经网络为2层,每层网络隐藏单元大小为768。训练时,我们采用批量训练的方式,每批次包含16个训练样本,输入的文本序列最大长度为100。学习率的更新方式保留不变,设置dropout的值为0.1,优化器为Adam。
..........
结论
本课题对基于BERT模型实现垃圾分选专利辅助文档自动生成的方法进行了深入的理论分析与研究。通过对专利分析方法、自然语言处理技术、语言训练模型、文本生成方法以及模型训练及微调方法的严谨探究,设计并实现了基于BERT-Attention-LSTM的专利辅助文档生成模型,并根据所研究模型及方法对垃圾分选专利的发明内容进行实验验证,同时对实验结果进行分析与评价。表明该文档对批量专利阅读起到一定的辅助作用,总结出本课题所研究模型及方法在对专利内容进行处理及分析方面的积极作用。(2)在将该模型应用于垃圾分选专利分析时,本文根据垃圾分选专利领域背景知识构建垃圾分选专利专用语料库及停用词词库,提高整个任务对垃圾分选专利处理及分析的专业性。鉴于当前专利大数据时代所需,利用NLP技术实现对专利文本数据的阅读理解与表达必然成为文本分析领域的技术发展风向标。而目前使用NLP技术对专利文献的处理及分析方面研究尚不成熟,存在的问题诸如硬件设备的不足问题、数据质量问题、文本专业领域的划分,处理模型设计与优化,这些问题的存在均直接影响该技术在专利文献上的处理效果好与坏。以上提出问题涉及到硬件,软件,模型,统计学,分析算法以及深度学习等若干学科知识,因此需要集各领域研究人员的智慧于一体,才能将专利文献分析的技术发展为没有短板且真正成熟的先进技术。致力于不仅可以实现对专利文献进行辅助文档的生成,而且可以做到对专利文献的规则,结构体系,发明内容等进行生成,生成结果应更精确、模型数据处理效率更高,更能够完整的体现专利文献中潜在的信息。
参考文献(略)

