本文是软件工程论文,本文主要基于英文文献研究了中药相关的实体关系抽取问题,并结合抽取出的实体关系做了进一步的应用。因此本文工作主要有以下几个方面:1.问题的提出:随着中医现代化的提出,越来越多关于中药的文章以英文的形式发表,与中草药相关的实体知识迅速积累。因此,迫切需要挖掘这些实体关系,以有效利用医学文献。通过对文献的阅读并结合信息抽取领域知识,发现有关中药的描述可以明确为具体的关系。因此,定义了中药与疾病(化学物质)这两种实体之间的“粗粒度”关系。2.语料库的构建:接着,采用自然语言处理工具对获取的数据进行了预处理,在相关专家的帮助下完成了对数据的关系标注。最后,给出了数据统计。3.关系抽取问题的研究:一、本文设计并实现了实体关系抽取模型。首先提出了SETATT-CNN模型,该模型创新性体现在根据分段输入特征提出了具有分段注意力机制的SEGATT层,实现了“词粒度”的注意力机制。对应证候常用方剂一栏,该部分为半结构化形式。由于部分百科词条描述中存在多种方剂且方剂描述上存在过多数字字符,针对这种情况首先进行文本清洗,然后采用构建的方剂词典进行标准化匹配,以获得方剂的标准化表示及关系。对于证候常用中药、方剂组成一栏,主要出现的问题就是中药后面常携带不规范的数字及其他类型字符。
.....
第1章绪论
自然语言处理技术的发展为解决中医领域非结构化知识向结构化的转变奠定了基础[5],尤其是深度学习技术的兴起为实体关系抽取问题的解决打开了新的局面[6]。深度学习方法不需要引入复杂的特征工程就能取得较高的准确率。越来越多的研究人员将此方法应用在挖掘蛋白质、基因与疾病的关系上,并取得了不错的结果,这也为本文的研究工作奠定了技术基础。将非结构化的文本内容转化为结构化的形式是知识传播的重要途径,实体和关系的简洁化表示方式是实现知识展示和检索的高效方法。实体关系网络是整合大量实体信息的结构化知识库,可以清晰的描述物理世界中概念及概念间的关系。构建中医领域的实体关系网络能很大程度的提高中医知识的传播,使人们从阅读大量医学文献获取知识的途径中解放出来。该实体关系网络以中药为核心,实现了多源实体关系的连接,初步探索了以中药为核心整合多源实体关系。最后,可视化的实现能够让使用者清晰明了的看到实体之间的关系,降低用户检索及查找实体关系的时间成本。
....
第2章相关技术介绍
2.1实体关系抽取
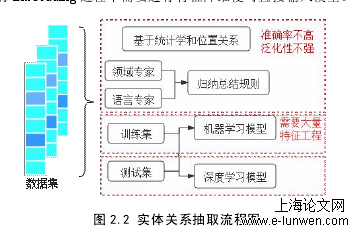
基于规则的方法就是指通过人工或者机器分析语料内容及语法成分,总结形成相应规则或者模板,然后根据形成的模板进行模式匹配,去寻找对应实体之间的关系。不难看出,针对不同领域的实体关系抽取,都需要依赖不同领域的语言专家提供方法上的支持。其局限性在于方法的准确度将很大程度上取决于专业人员和领域专家设计大型规则的能力。该方法在一定程度上能够解决实体关系抽取精确度和召回率不高的问题,但是存在的问题是显而易见的。一是人工进行规则归纳耗时费事;二是不同国家发表的英文期刊,其语言风格及表达形式都是有所不同的;三是制定的模板规则是基于部分特定样本总结而成的,其泛化性不高、可移植性差,难以应对新知识的发现。与传统的机器学习方法相比具有深层结构的神经网络模型在解决NLP问题上具有较好的效果。其主要原因在于文本经过词嵌入特征编码之后,其高维度的文本特征包含了大量文本语义信息,可以全部输入到具有大量权值参数的神经网络模型中进行训练。多隐层形式的神经网络模型具有优异的特征学习能力,学习到的特征对文本的原始数据具有更本质的刻画能力,从而更好的为实体关系分类任务服务。
2.2词嵌入特征方法
不难看出,当文本数据过大的时候往往会发生维度灾难,过多被零占位的现象将导致矩阵的稀疏与离散。其次,该表示方式忽略了一个重要特征就是句子中词与词之间是存在必然关联关系的。比如中医文本中方剂和草药大多数情况下是在疾病之前的;因此,此特征表示方法忽略了词与词之间的相互影响,降低了文本语义信息的表达能力。为了解决one-hot特征映射方式的缺点,尽可能的实现词与词之间的相似性表示,谷歌在2013年推出了Word2vec词向量训练工具,该方法能够解决one-hot表示形式所导致的矩阵稀疏、词与词之间无法进行度量计算的缺点。Word2vec模型通俗的讲就是一个具有三层结构的简单神经网络模型,模型训练所得的参数就是所需要的词嵌入特征。其结构如图2.3所示,分为输入层、隐藏层和输出层;模型的输入为one-hot向量,隐藏层采用非线性激活函数,且输出层维度与输入层一样,只是输出层采用softmax回归函数实现概率计算。在进行卷积和池化之后,往往改变了输入数据的原始结构,为了还原采样后的数据形式,便在池化后加入全连接操作。全连接是比较特殊的网络结构,可以概括为对特征的重新组装,以方便分类器进行关系分类。
第3章英文文献中药关系语料库构建............................................................20
3.1数据来源与关系定义...........................................................................20
3.2中药实体识别.......................................................................................21
3.3构建过程...............................................................................................22
3.4本章小结...............................................................................................25
第4章基于深度学习的中草药关系抽取........................................................26
4.1基于SEGATT-CNN的关系抽取模型.................................................26
4.2基于混合特征的关系分类方法...........................................................31
4.3实验设计与评价标准............................................................................33
4.4实验与结果分析...................................................................................34
第5章中草药的实体关系网络构建与应用....................................................43
5.1总体概述...............................................................................................43
5.2数据来源与获取...................................................................................46
5.3数据融合...............................................................................................49
.......
第5章中草药的实体关系网络构建与应用
5.1概述
本文将采用自顶向下的方式构建以中药为核心的关系网络。其顶层设计为模式层:定义和提供了一个标准化、规范化的数据模式,为不同来源的数据整合和知识连接提供上层指导。其底层为数据层:由一系列的具体实体关系组成。因此,本章节构建实体关系网络的流程可以描述如下:(1)以中医知识体系为主体,定义实体关系网络主体数据模式。(2)采用爬虫技术获取相关中医知识,并进行知识抽取和数据处理,完成对主体数据模式的实例化,以初步建立以中医为核心的实体关系网络。(3)建立核心实体的同义词库和中英文映射,将从英文中抽取的实体关系连接到实体关系网络中,对5.1.1节定义的数据模式以增加边和节点的形式进行语义关系上的扩展。(4)对数据做进一步的整合与存储,建立以中药为核心的实体关系网络(知识库)。并对未完成中英文映射的实体进行翻译,存储一个英文形式的实体关系网络。同时应用本文模型抽取了剩余未标注数据12542条样本。抽取出草药和疾病的正向关系对1546条,草药与化学物质的正向关系对2121条。通过阅读语义关系和中医药专家验证,3154条关系符合定义标准。在生物医学领域,经常研究的实体概念有:药物(drug)、蛋白质、基因、化学物等;为了尝试将此部分数据加入到本章节已构建的实体关系网络中,我们收集了部分公开的比赛数据集,以保证关系的准确性。
5.2数据来源与获取
构建以中药为核心的关系网络的就是探索如何整合多源知识,以丰富中药知识库。本小节将再次从两个不同来源收集实体和关系,通过实例化的方式将该部分的实体和关系加入构建好的实体关系网络中去.本文关系抽取实验定义并构建了草药与疾病的治愈关系及草药与化学物质的提取关系分别4732条和4666条数据样本,其中有效实体关系对为1766和2271.因此本小节将从这两个数据集中获取实体关系:1.从BioCreative-V(CIDrelationextract)关系抽取数据集中收集化合物与疾病的致病关系。其具体来源为具有“金标注”的训练集和开发集,收集的有效关系对为1581条,其中化学物实体610个、疾病实体777个(均包含缩写);2.从BioCreativeVI的CHEMPROT任务上下载化学物和蛋白的相互作用(为了方便,关系统一命名为粗力度的相互作用关系)关系。整理训练集和开发集得关系对5462条,其中化学物730个,蛋白质761个。因此,首先先完成文本的初步清洗,在进行关系提取。对上述数据处理后,可以整理出中医领域:中药、方剂、证候、疾病这四类实体概念之间的关系,其数据以三元组的形式存储在以下文件中,实体关系存储结果如图5.8。
......
第6章总结与展望
在模型训练上设计了具有权值系数的交叉熵损失函数。为了进一步利用高阶语义特征,又设计实现了基于混合特征的关系分类方法。该方法通过预训练深度学习模型以获得高阶特征张量,然后通过拼接特征结合不同分类器,以提高关系分类的准确率。二、方法的验证。采用word2vec结合大量PubMed语料训练了词向量特征,并在三组数据上进行了实验以验证关系抽取方法的有效性。1.将该方法应用到草药与疾病、草药与化学物质这两种实体关系的抽取上,相比于基线方法本文模型取得了较好的结果,抽取结果的准确率能达到95%。2.在BioCreativeV数据集上做了进一步验证,和当前最新论文采用的模型相比,本文设计的方法在F值上比最好的深度学习模型方法约高2.7%。综上论述,本文的研究工作其意义在于:首先基于英文语料研究了中草药相关的实体关系抽取问题。自动地从医学文献中获取我们需要的知识是一项极为重要的研究内容,能够很大程度的改善医学工作者的工作效率。接着,以收集和整理的中医领域实体知识为主体,将抽取的中草药相关的实体关系补充进来构建一个清晰可见的实体关系网络及应用。
参考文献(略)
参考文献(略)

