本文是软件工程论文,在这个信息爆炸的时代,人们也更愿意在互联网上发表自己的所见所闻所想,因此,这使得收集并统计出网络上广大网友的情感动态变得很有意义。而国家电网作为一个国有特大型骨干企业,为客户供更优质的服务并保持永恒不变的主题。因此本文提出了一个能抓取互联网上电力相关主题信息的软件,分析其整体情感走向,能有助于国网公司及时群众的满意度及需求,使公司能更好的履行社会责任,更好的实现“互联网+营销服务”。研究对象为具有一定互联网代表意义的微博,此次研究所构建的系统采用了当前的自然语言处理技术,该系统可以实现对微博的实时抓取,同时也可以展开针对性的情感倾向性分析。此次研究有一些亮点,有一定的贡献,详细如下的:1)针对微博上各类电力相关主题信息的实时发布,传播而电力公司无法及早掌握该信息的情况,本文开发并实现了一个爬虫程序,可在微博内定向实时抓取电力相关主题的信息。2)基于电力相关主题的特征性,在原有分析算法的基础上,通过完善新的词汇库,结合单词词典和规则级,提升现有的分析计算方法,加强了本抓取软件对微博中电力相关主题信息的敏感性3)建立了一个微博电力相关主题信息的收集与分析系统,分析微博内对电力相关话题的关注度和情感倾向性。
........
第一章绪论
自从互联网传入国内后,该项研究并没有被当时的人们所重视,一直到近几年,互联网深入到每个人的生活、工作中后,才慢慢被人重视起来。这在调动人们情绪以及引导舆论的方向上,有着重要的参考价值[5]。但在提取这些信息的过程中,也并不是一帆风顺。首先,这些数据都存在于平台的后台服务器中,如何拥有调动并搜索该数据的权限就是一个较大的问题。因为这涉及到该平台公司的商业机密甚至每一个平台用户的个人隐私。因此到目前为止,在国内该项研究一直未有突破性的进展。本文所研究的即是针对微博中关于电力相关主题方面的数据收集,通过程序自动分辨出每一条主题中的情绪倾向,来判断该条主题信息包含了对于电力行业正面或是负面的心态。这样一来,电力公司针对社会舆情的应急处理将会大大提前,而不是一味的被动防御,甚至可以再舆轮还未爆发前主动出击,消除网上人们对电力公司的负面情绪,正确引导舆论走向。这对于公司更好的贯彻“你用电、我用心”的服务理念有巨大的帮助。

......
第二章相关理论与研究综述
2.1网络爬虫简介
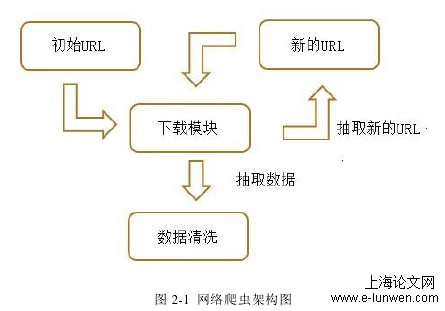
因为从本质上来说,现有的搜索软件都是根据一个最初赋予的URL,逐层自行挖掘网络页面,符合条件的页面产生下层RUL,然后重复这一过程,最终层层排列,搜索到的信息越来越庞杂,直到完成任务为止。最终用户得到的就是一个未经删选的庞大数据,若想得到精确目的用户还需手工逐条确认。综上所述,在现今这个网络信息井喷的时代,要想搜索一个特定的跟电力信息相关的主体,无异于大海捞针,既耗时耗力,最终得到的结果针对性也未必够。因此,本文特地提出了电力相关主题爬虫概念,其可以定向抓取与电力主题相关的信息,区别于传统爬虫,本电力相关主题抓取爬虫主要从以下三个方面做了提高与创新:(1)明确了定向抓取方向为电力相关主题;(2)在抓取结果的基础之上来抽取数据,同时还需要进行过滤;(3)对URL搜索策略进一步的明确。
2.2微博与文字处理
用机器来处理语言?这个曾经一度被认为是天方夜谭的想法,在距今大约70年前被人打破,这个人就是有计算机科学之父之称的图灵。1950年,图灵提出了一种想法,尝试让机器同人交流,即聊天机器人[8],若人无法判断对方是否为机器,则反应这机器有智能,这一理论被图灵发表在了1950年的《Mind》中,对当时引起了巨大的冲击,而他的这一理论测试,就是著名的图灵测试。同其他从无到有的技术发展一样,语言处理经历的60多个年头也并非是一帆风顺。早期的自然语言处理因为人们致力于让计算机“学习”能力上,让计算机学习语法,学习文字逻辑关系,从而让计算机能分析出语言背后意义,但20多年一直毫无进展。早期自然语言处理方法如图2-6所示。
.....
第三章电力相关主题数据实时抓取与预处理...................19
3.1针对电力相关主题数据的网络爬虫......................19
3.2数据的预处理...................20
第四章电力相关主题微博情感倾向性分析.......................26
4.1各类词典的构建...............27
4.2N-pos模型判断情感主客观性................................28
4.3基于词典的情感倾向分析算法..............................30
第五章系统实现与实验................37
5.1系统架构...........................37
5.2爬虫模块...........................38
5.3数据处理模块...................39
....
第五章系统实现与实验
5.1系统架构
本系统步骤如下,首先形成主题,这一过程的实现主要依托于对每日热门主题的抓取,新浪微博中内设了热门微博,全部是热门主题,依托于爬取就可以得到相应的热门主题,其他途径如下,用户进行输入,依托于实时接口,用户将主题关键字输入到其中,爬虫程序将会展开后续的爬取操作。接着为爬虫模块,在用户查询关键字的基础之上对当日前100条微博进行爬取,这是一种默认的操作,也有接口可以对参数进行修改,这种情况下就可以对任意时间段的微博进行爬取,这样就可以真正的实现实时跟踪主题。此后为数据预处理模块,囊括了两个部分,首先就是数据清洗,其次就是分词,解析数据,最终所呈现出的文件为XML格式,后续所需要进行的操作就是分词以及词性标注,这一过程的实现主要依托于jieba。此后为情感分析模块,使得情感分析算法得到有效的实现,最终为展示,详见图5-1。
5.2爬虫模块
爬取数据不能违反网络协议规定,在这一过程中需要对爬取频率进行严格的控制,30秒发送请求给服务器,这一时间间隔是比较理想的[28],其次,在爬取新浪微博页面的过程中,主要就是对拥有javascript代码的爬取,需要对代码位置确定,后续所需要做的就是进行转化,本文编码格式转化javascript代码,最终形成的就是html代码。在爬取链接失败的时候,有必要第一时间进行处理,系统构建了失败的队列,链接没有成功进行爬取,这部分会在失败队列中进行保存,对失败队列中所存在的链接进行统一爬取,这一过程需要持续进行,全部爬取工作完成后就可以终止。此次实验使用的爬虫技术比较简单,不过爬虫模块在实际应用中可以对多线程爬取功能很好的支持,由于应用了多线程爬取,这在很大程度上提高了爬取效率,系统需要先进行待爬取队列的构建,同时还需要进行已完成队列的构建,然后对待爬取队列中所存在的链接进行多线程爬取,在已完成队列的基础之上,将完成的链接全部丢入到其中,同时在失败队列的基础之上丢入失败的链接。
............
第六章总结与展望
过去几年来智能设备诸如手机、电脑等急速更新换代,网络速度的不断提升,导致人们通过网络产生互动的频率急剧增加。数据显示,截止至2018年上半年,2018年一二季度,根据相关机构发布的数据显示,中国的网民规模持续扩大,网民规模已经达到了8.02亿人,其中有99.1%用户使用手机上网,占比非常高,与2013年的移动宽带下载速度相比2018年中国在移动宽带下载速度提高了6倍,而相应的移动宽带资费却出现了大幅的下降,与2013年资费相比下降了90%,这极大的刺激了网络流量的增加,当前阶段每月流量人均为7.2GB,移动互联网接入流量554亿GB。在这个信息爆炸的时代,人们也更愿意在互联网上发表自己的所见所闻所想,因此,这使得收集并统计出网络上广大网友的情感动态变得很有意义。而国家电网作为一个国有特大型骨干企业,为客户供更优质的服务提是其永恒不变的宗旨。因此本文提出了一个能抓取互联网上电力相关主题信息的软件,分析其整体情感走向,能有助于国网公司及时群众的满意度及需求,使公司能更好的履行社会责任,更好的实现“互联网+营销服务”。
参考文献(略)

