科学论文范文在哪里找?近年来,科学研究手段逐步从物理实验演变为仿真科学计算。例如在天文学方面,研究人员不再花费时间在望远镜上,而是访问由社区创建的大规模图像数据库[5]。在生物信息学方面,由国立卫生研究院主持构建的基因数据库能够帮助研究人员将特定的基因类型与各种疾病联系起来。大数据时代的到来,使得现在的科学研究对计算和存储能力有较高的需求,而构建一个高性能计算中心又需要昂贵的费用。本文为大家提供了篇关于科学方面的范文,供大家参考。
科学论文范文一:中国地震科学实验场暨CSEP-CN计划的若干统计地震学问题
本工作利用图像信息学PI算法对研究区的地震预测预报工作开展了实验,结果显示,不同目标震级下的若干计算参数,主要包含网格尺度、预测时长和预测时间起点,呈现出不同的优势分布特征,分析原因主要是由于研究区测震台站在不同时期的地震监测能力存在差异,以及不同目标震级地震事件的孕震尺度有所不同。同时,PI算法以往的时间窗口的设置主要为10年/5年/5年的比例,对于分布在小震级一端的地震事件预测,如在较弱地震活动性水平区域,这种窗口尺度的选取可能需要进行变化,利用PI算法给出的“向前”预测结果显示,“热点”集中分布于研究区内的龙门山断裂带、川滇地块西部和滇缅地块东北地区。在对PI算法主要参数进行研究的同时,算法的应用同样受到其他若干因素的影响,如使用资料存在震级标度不统一的问题。震级标度的不统一会导致地震数量在不同震级档内的数量特征存在差别,进而影响PI算法给出的热点分布。在传统对PI算法的工作中,对电离层等数据或者余震的影响等方面进行了分析,而未从理论层面进行有效的改进和完善,PI算法虽有效的从数量特征中挖掘出地震活动的涨落情况,但却是将截止震级以上的地震事件看成是均等的个体,没有了震级这一维度的概念,即没有添加G-R关系和Utsu-Omori定律产生的贡献。而研究表明,基于不同成分的混合模型在地震预测试验中有更高的概率增益。
摘要
Abstract
第一章引言
1.1中国地震科学实验场(CSES)项目
1.2“地震可预测性国际合作研究(CSEP)计划”
1.3地震预测模型
1.4统计检验方法
1.5本工作基本逻辑路线
第二章研究区域与所用数据
2.1研究区构造特征
2.2研究区地震活动特征
2.3使用数据
第三章研究区最小完整性震级评估
3.1基于目录的最小完整性震级评估
3.1.1震级-序号方法
3.1.2MAXC(MaximumCurvature)方法
3.1.3GFT(Goodness-of-fitTest)
3.1.4MBS(Mcbyb-valuestability)方法
3.1.5EMR(EntireMagnitudeRange)方法
3.1.6MBASS(Median-BasedAnalysisoftheSegmentSlope)方法
3.1.7昼夜噪声调制(Day-to-nightfromSyntheticCatalogs)方法
3.2基于地震台网的完整性震级评估
3.2.1ProbabilisticMagnitudeofCompleteness(PMC)
3.2.2PMC方法原理
3.2.3应用
3.3小结与讨论
第四章地震预测模型Ⅰ—图像信息学(PI)算法
4.1图像信息学(PI)算法简介
4.1.1算法的提出
4.1.2PI算法应用于地震预测
4.1.3算法的改进与探索
4.2PI算法基本原理
4.3PI算法在研究区的探索与应用
4.3.1使用目录分析
4.3.2算法参数
4.3.3优化参数下的PI预测结果
4.3.4小结与讨论
第五章地震预测模型Ⅱ—Reasenberg-Jones模型
5.1模型定义与参数似然估计
5.2参数残差分析
5.3地震发生率和发生概率预测
5.4模型效能检验
5.5对相关地震序列的应用
5.6小结与讨论
第六章地震预测模型Ⅲ—传染型余震序列ETAS模型
6.1时间-空间ETAS模型
6.2基本原理
6.3随机除丛法
6.4模型应用
6.5小结与讨论
第七章地震预测模型Ⅳ—“Nowcasting”
7.1EarthquakeNowcasting基本思路
7.2研究区及使用数据分析
7.3EarthquakeNowcasting评估当前危险性状态
7.4Nowcasting与Forecasting概念的不同
7.5小结与讨论
第八章结论与讨论
8.1主要结论与总结
8.1.1对研究区数据资料质量的评估
8.1.2中长期地震预测模型的应用
8.1.3短期地震预测模型的应用
8.1.4新的统计预测方法的应用
8.2存在问题及下一步工作
参考文献
科学论文范文二:世界科学中心转移过程与形成机制——基于诺贝尔奖获得者的分析
从静态的视角出发,基于1901-2017年的诺贝尔奖人才的国籍信息、机构信息以及成长空间信息,揭示诺贝尔奖人才时空分布特征,主要结论如下。(1)从国籍信息来看,美国是诺贝尔三大自然科学奖获得者数量最多的国家,且领先其他国家的优势十分明显,侧面反映了以美国主导的是科学中心的绝对地位。从不同学科看,各个国家的获奖分布数量位序基本一致,表现为以美国为首,英国、德国、法国、日本仅次之的位序特征。无论从全局统计,还是分学科统计,诺贝尔奖国籍分布皆呈现“长尾型”的位序-规模分布特征,即少数国家位于高值区,绝大数国家的获奖规模处于中等以及较低水平,两级分化显著,一定程度反映了国家间的科学发展极大的差距,以及科学发展水平极化分布格局。(2)从机构分布特征看,诺贝尔奖人才的教育与工作机构分布类型以大学为主,科研机构和企业次之,但不同国家的机构类型分布有所差异,如德国的科研机构(如马普学会)同样扮演了重要角色,这反映了世界各国从事科学研究主体差异性。与此同时,获奖者越来越多地集中于少数世界一流大学,这说明高水平的研究型大学既是培养科学人才的苗圃,又是诺贝尔自然科学奖研究工作的主要阵地。这种以世界一流大学和著名科研机构为主要载体的传递链,反映了科学知识与科学精英人才的高度集聚性。(3)从诺贝尔奖人才的成长空间分布特征看,诺贝尔奖人才成长的空间轨迹呈现出“锥形”分布,从出生至获奖,所分布的国家数量基本呈逐渐减少的态势。诺贝尔奖人才成长四个阶段皆高度集中于北美、欧洲发达国家,尤其是美国、英国和德国,其中教育地与世界一流大学分布格局高度吻合,其诺贝尔奖获奖成果完成地和其获奖时的工作地格局也高度吻合。
内容摘要
ABSTRACT
第一章绪论
1.1研究背景
1.1.1世界科学中心转移进入关键期
1.1.2中国建设世界科学中心迎来新机遇
1.1.3高层次科学人才成为科学中心建设的关键支撑
1.1.4中国诺贝尔奖的困惑需要新的视角加以研判
1.2问题提出与研究意义
1.2.1问题的提出
1.2.2研究意义
1.3研究目标、思路与研究方法
1.3.1研究目标
1.3.2研究思路
1.3.3研究方法
第二章相关研究进展与理论基础
2.1相关概念辨析
2.1.1世界科学中心
2.1.2科学精英与诺贝尔奖人才
2.1.3人才跨国迁移
2.2相关研究进展
2.2.1世界科学中心转移规律研究
2.2.2世界科学中心形成的机制研究
2.2.3科学精英成长规律的研究
2.2.4关于科学家跨国迁移的研究
2.2.5现有研究不足与本研究创新点
2.3相关理论基础
2.3.1世界科学中心形成与转移理论
2.3.2科学家跨国迁移理论
第三章诺贝尔奖人才成长的时空特征
3.1诺贝尔奖人才的国籍分布特征
3.1.1物理学奖
3.1.2化学奖
3.1.3生理医学奖
3.1.4“位序—规模”分布特征
3.2诺贝尔奖人才的机构分布特征
3.2.1大学为主导的科研主阵地
3.2.2集中分布在世界一流大学
3.3诺贝尔奖人才成长的空间轨迹
3.3.1出生地:集中分布在北美、欧洲发达国家
3.3.2教育地:与世界一流高校分布格局高度吻合
3.3.3完成地:高度集聚在美国和欧洲地区
3.3.4获奖地:与成果完成地格局高度耦合
3.4本章小结
第四章诺贝尔奖人才表征的世界科学中心转移过程
4.1汤浅现象与世界科学中心转移规律
4.2基于获奖者国别属性测度世界科学中心转移
4.2.1以成果完成国表征世界科学中心
4.2.2以获奖时工作国表征世界科学中心
4.2.3以获奖者国籍表征世界科学中心
4.3基于不同学科获奖者国别属性测度世界科学中心转移
4.3.1不同国家存在学科偏向性
4.3.2以诺贝尔物理学奖测度世界科学中心
4.3.3以诺贝尔化学奖测度世界科学中心
4.3.4以诺贝尔生理与医学奖测度世界科学中心
4.4世界科学中心测度结果比较与趋势研判
4.5本章小结
第五章诺贝尔奖人才跨国迁移对科学中心形成的影响
5.1诺贝尔奖人才跨国迁移特征
5.1.1整体获奖者迁移统计特征
5.1.2不同成长阶段类型的迁移特征
5.2人才迁移网络的国家角色识别
5.2.1网络构建
5.2.2测度模型
5.2.3网络特征与角色识别
5.3人才跨国迁移对世界科学中心形成的影响
5.3.1迁移网络结构演变与世界科学中心体系变迁
5.3.2人才跨国迁移对德国的影响
5.3.3人才跨国迁移对美国的影响
5.4本章小结
第六章诺贝尔奖人才表征的科学中心形成机制
6.1诺贝尔奖人才跨国迁移的影响机制
6.1.1理论溯源与研究假设
6.1.2变量选取与数据来源
6.1.3模型选择与构建
6.1.4回归结果分析
6.2诺贝尔奖人才表征的科学中心形成机制
6.2.1世界科学中心转移的原因初探
6.2.2影响因素与变量选取
6.2.3计量模型的构建
6.2.4回归结果分析
6.3世界科学中心的成长路径
6.3.1科学中心形成的条件
6.3.2科学中心形成的“成长模型”
6.4本章小结
第七章结论与讨论
7.1研究结论
7.2研究启示
7.3研究不足与展望
参考文献
ABSTRACT
第一章绪论
1.1研究背景
1.1.1世界科学中心转移进入关键期
1.1.2中国建设世界科学中心迎来新机遇
1.1.3高层次科学人才成为科学中心建设的关键支撑
1.1.4中国诺贝尔奖的困惑需要新的视角加以研判
1.2问题提出与研究意义
1.2.1问题的提出
1.2.2研究意义
1.3研究目标、思路与研究方法
1.3.1研究目标
1.3.2研究思路
1.3.3研究方法
第二章相关研究进展与理论基础
2.1相关概念辨析
2.1.1世界科学中心
2.1.2科学精英与诺贝尔奖人才
2.1.3人才跨国迁移
2.2相关研究进展
2.2.1世界科学中心转移规律研究
2.2.2世界科学中心形成的机制研究
2.2.3科学精英成长规律的研究
2.2.4关于科学家跨国迁移的研究
2.2.5现有研究不足与本研究创新点
2.3相关理论基础
2.3.1世界科学中心形成与转移理论
2.3.2科学家跨国迁移理论
第三章诺贝尔奖人才成长的时空特征
3.1诺贝尔奖人才的国籍分布特征
3.1.1物理学奖
3.1.2化学奖
3.1.3生理医学奖
3.1.4“位序—规模”分布特征
3.2诺贝尔奖人才的机构分布特征
3.2.1大学为主导的科研主阵地
3.2.2集中分布在世界一流大学
3.3诺贝尔奖人才成长的空间轨迹
3.3.1出生地:集中分布在北美、欧洲发达国家
3.3.2教育地:与世界一流高校分布格局高度吻合
3.3.3完成地:高度集聚在美国和欧洲地区
3.3.4获奖地:与成果完成地格局高度耦合
3.4本章小结
第四章诺贝尔奖人才表征的世界科学中心转移过程
4.1汤浅现象与世界科学中心转移规律
4.2基于获奖者国别属性测度世界科学中心转移
4.2.1以成果完成国表征世界科学中心
4.2.2以获奖时工作国表征世界科学中心
4.2.3以获奖者国籍表征世界科学中心
4.3基于不同学科获奖者国别属性测度世界科学中心转移
4.3.1不同国家存在学科偏向性
4.3.2以诺贝尔物理学奖测度世界科学中心
4.3.3以诺贝尔化学奖测度世界科学中心
4.3.4以诺贝尔生理与医学奖测度世界科学中心
4.4世界科学中心测度结果比较与趋势研判
4.5本章小结
第五章诺贝尔奖人才跨国迁移对科学中心形成的影响
5.1诺贝尔奖人才跨国迁移特征
5.1.1整体获奖者迁移统计特征
5.1.2不同成长阶段类型的迁移特征
5.2人才迁移网络的国家角色识别
5.2.1网络构建
5.2.2测度模型
5.2.3网络特征与角色识别
5.3人才跨国迁移对世界科学中心形成的影响
5.3.1迁移网络结构演变与世界科学中心体系变迁
5.3.2人才跨国迁移对德国的影响
5.3.3人才跨国迁移对美国的影响
5.4本章小结
第六章诺贝尔奖人才表征的科学中心形成机制
6.1诺贝尔奖人才跨国迁移的影响机制
6.1.1理论溯源与研究假设
6.1.2变量选取与数据来源
6.1.3模型选择与构建
6.1.4回归结果分析
6.2诺贝尔奖人才表征的科学中心形成机制
6.2.1世界科学中心转移的原因初探
6.2.2影响因素与变量选取
6.2.3计量模型的构建
6.2.4回归结果分析
6.3世界科学中心的成长路径
6.3.1科学中心形成的条件
6.3.2科学中心形成的“成长模型”
6.4本章小结
第七章结论与讨论
7.1研究结论
7.2研究启示
7.3研究不足与展望
参考文献
科学论文范文三:资产定价与数据科学中的拟蒙特卡洛方法
本文针对QMC的不同应用场景,讨论了影响QMC计算效率的若干因素,并研究了促进QMC效率提升的策略。在定价离散观测的障碍期权问题中,本文针对障碍期权中含有的复杂间断结构,提出了一种基于重要性抽样的光滑化方法,称作逐步重要性抽样(简称SIS)方法。该方法通过逐步移除贴现回报函数中的间断结构来提高QMC的模拟效率。我们证明了基于SIS方法的估计量具有无偏性,并且一定可以起到方差缩减的作用。进一步,我们还发现标的资产价格的路径生成顺序对SIS方法的效率有着不容忽视的影响。基于这个发现,我们设计了一种以最小化第一步方差贡献为目标的路径生成方法。特别地,对于在BS模型和基于隶属布朗运动的资产价格模型下定价障碍期权的问题,我们提出将SIS方法与选择最优的第一步路径生成时间相结合的QMC模拟策略。数值实验表明,本文提出的模拟策略可以显著地缩减估计量的方差,从而提高模拟效率。此外,当按照合适的路径生成顺序生成除第一步以外的资产价格路径时,估计量的有效维数被显著降低,从而使基于SIS方法的模拟策略得到进一步的效率提升。具体而言,对于BS模型下定价障碍期权的问题,当根据我们提出的标准选取最优的第一步生成顺序,并按照布朗桥顺序生成后续资产价格路径时,SIS方法总是展现出相较于其它路径生成顺序(顺序和倒序)的绝对优势。而对于VG模型下的定价问题,三种路径生成顺序的表现因问题和参数而异。总而言之,本文提出的SIS模拟策略不仅起到光滑化的作用,同时还有效地处理了金融定价中的维度灾难问题。
摘要
abstract
第1章引言
1.1拟蒙特卡洛模拟
1.2拟蒙特卡洛模拟在金融中的应用
1.3拟蒙特卡洛模拟应用中的两大挑战及应对策略
1.3.1高维度
1.3.2间断性
1.4论文的主要贡献与框架结构
第2章有效维数与降维技术
2.1有效维数
2.1.1ANOVA分解
2.1.2与有效维数相关的特征数及其计算方法
2.2路径生成方法回顾
2.2.1经典的路径生成方法
2.2.2问题依赖的路径生成方法
2.3路径生成方法在降维中的作用
第3章基于重要性抽样的光滑化方法
3.1背景介绍
3.1.1障碍期权的定价问题
3.1.2提高障碍期权模拟定价的效率
3.2逐步重要性抽样方法
3.3寻找最优的路径生成方法
3.3.1Black-Scholes模型
3.3.2基于隶属布朗运动的模型
3.3.3表示为两个Gamma过程的差的形式的方差Gamma模型
3.4数值结果
3.4.1在Black-Scholes模型下定价障碍期权的数值结果
3.4.2在方差Gamma模型下定价障碍期权的数值结果
3.5拓展应用
3.5.1其它障碍期权类型:敲入型期权的定价问题
3.5.2其它期权类型:回望期权的定价问题
3.5.3其它资产价格模型假设:常量方差弹性模型
3.6本章小结
第4章多层拟蒙特卡洛方法的相关研究
4.1背景介绍
4.1.1多层蒙特卡洛方法
4.1.2多层拟蒙特卡洛方法
4.2Sobol点和好格子点对多层拟蒙特卡洛方法的影响
4.3高维性与降维技巧对多层拟蒙特卡洛方法的影响
4.3.1路径生成方法在多层拟蒙特卡洛方法中的应用
4.3.2数值实验与结果分析
4.4间断性及光滑化方法对多层拟蒙特卡洛方法的影响
4.4.1逐步重要性抽样方法在多层拟蒙特卡洛方法中的应用
4.4.2数值实验及结果分析
4.5本章小结
第5章拟蒙特卡洛方法在大数据处理中的应用
5.1背景介绍
5.2利用QMC点从高维大数据集抽样
5.2.1高维点集的递归二分法
5.2.2从QMC点集到数据集的映射法则
5.2.3数值实验
5.3基于递归二分法的数据集压缩稀化方法
5.3.1理论分析
5.3.2数值实验
5.4本章小结
第6章总结与展望
参考文献
科学论文范文四:大科学装置控制系统架构和历史数据存档技术研究
我们使用前后端分离技术设计和开发了一套数据可视化系统。在后端,我们针对不同类型的数据的可视化需求设计了不同的服务端软件,使用Nginx反向代理服务器为前端程序提供了统一的数据访问接口;在前端,我们基于Vuejs框架开发了数据可视化单页面应用,为技术人员提供了数据显示、查询、统计和下载功能。大科学装置的规模正在不断地增大,装置运行过程中产生的历史数据也随之激增,海量数据的处理成为数据查询速度及数据分析性能的瓶颈,数据存档及分析技术面临着新的挑战。我们基于Hadoop生态系统软件设计了大科学装置的数据仓库。建立了一个由9个节点组成的Hadoop集群。集群建立过程中使用了软件对集群的建立、管理和监测很有帮助。我们设计和开发了兼容历史数据存档软件的数据迁移程序,实现了控制系统数据存档软件到Hadoop集群的数据迁移过程。这部分研究工作为未来开展基于数据仓库的数据分析提供了研究平台。目前国家同步辐射实验室正在开展HALS的预研工作,本论文的研究工作是“HALS控制技术研究”子项目的一部分,相关的研究成果为未来HALS的建设提供了技术储备。
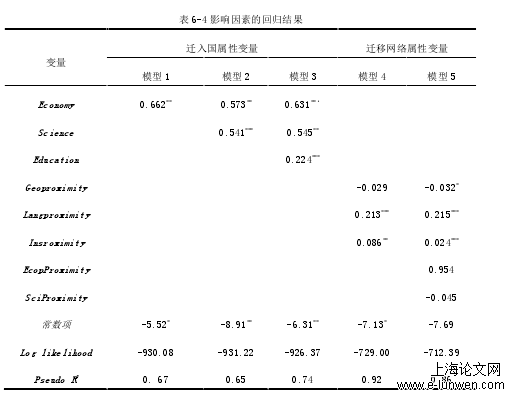
影响因素的回归结果
摘要
ABSTRACT
第1章绪论
1.1引言
1.2国内外研究现状
1.2.1EPICS7控制系统应用现状
1.2.2大科学装置历史数据存档技术现状
1.2.3大科学装置中大数据技术应用现状
1.3国家同步辐射实验室开展的大科学装置工程项目
1.3.1合肥光源装置
1.3.2红外自由电子激光装置
1.3.3合肥先进光源预研工程
1.4本论文主要内容和创新点
第2章基于EPICS7的控制系统架构研究
2.1EPICS7概述
2.1.1EPICS7中主要模块
2.1.2EPICS7命令行调试工具
2.1.3EPICS7性能提升
2.2原型控制系统
2.2.1原型控制硬件系统
2.2.2原型控制软件系统
2.3pvAccess协议性能测试
2.3.1测试平台搭建
2.3.2IOCApplication的设计和开发
2.3.3测试程序开发
2.3.4测试数据处理和结果分析
2.4pvData的应用设计
2.4.1应用背景介绍
2.4.2IOC设计与开发
2.4.3数据采集与存档
2.4.4数据可视化
2.5SoftwareInterlockServer开发
2.5.1软件结构
2.5.2软件开发
2.5.3功能测试
2.5.4实际测试
2.6本章小结
第3章基于ArchiverAppliance的历史数据存档技术研究
3.1数据存档系统架构
3.2ArchiverAppliance
3.2.1ArchiverAppliance概述
3.2.2自动化部署程序的开发
3.2.3ArchiverAppliance在NSRL的应用情况
3.2.4ArchiverAppliance性能测试
3.3存档参数的自动配置
3.3.1配置元信息
3.3.2RecSync
3.3.3AutoConfigurator
3.3.4功能测试
3.4数据可视化
3.4.1服务端实现
3.4.2Web客户端实现
3.5本章小结
第4章基于Hadoop的大科学装置数据仓库
4.1Hadoop生态系统概述
4.1.1HDFS
4.1.2MapReduce
4.1.3Spark
4.1.4Parquet
4.1.5Sqoop
4.2大科学装置数据仓库设计
4.3Hadoop集群建设
4.3.1CDH简介
4.3.2ClouderaManager简介
4.3.3服务器硬件建设与基本软件环境设置
4.3.4CDH集群软件部署
4.3.5集群运行状况
4.4数据迁移程序开发
4.4.1针对ArchiverAppliance内数据的迁移过程
4.4.2针对RDBChannelArchiver内数据的迁移过程
4.4.3数据查询
4.5本章小结
第5章总结与展望
5.1总结
5.2展望
参考文献
科学论文范文五:科学数据用户相关性标准研究
本文全面研究了科学数据相关性标准,分为三个主要研究内容:(1)科学数据相关性标准的集合及其内涵;(2)科学数据相关性标准的认知加工过程,从而构建了外界信息特征——线索——相关性标准之间的关系;(3)在相关性判断中,相关性标准对相关性判断的影响权重,从而构建科学数据相关性标准的使用特征。通过上述三个方面的研究,清晰完整的展示了整个科学数据的相关性判断过程,拓宽了相关性研究的维度,为科学数据共享平台的提升和改进提供了有力的理论依据,也为实现以人为主体,将情境和用户考虑其中的未来智能式搜索引擎提供参考依据。本次研究主要为探索性研究。前人开展了针对各种信息载体的相关性标准研究,但是科学数据作为新兴信息载体,对其相关性标准的研究较少,且与文献等可直接被人类吸收的知识有着本质不同。因此本文以探索性研究为主,通过访谈、情境实验等方法探索性的描述了科学数据相关性判断的整个认知过程。研究明确区分了科学数据信息特征、线索、相关性标准并分析了三者的对应关系。通过眼动仪+情境实验的方法获取用户对外界信息的关注数据,同时结合访谈获取用户关注外界信息后的认知处理过程。外界信息刺激用户形成线索,大脑对线索进一步加工形成相关性标准。在此过程中,用户共关注了45类数据信息特征,包括名称、数据内容、题目、关键词、作者、发表时间、链接、数据时间等;产生了50条线索刺激,用户对线索进行认知加工最终形成9个相关性标准。其中注视时长最长的为名称,排名前五位信息特征还有数据内容、题目、关键词、数据时间,这些信息特征均与专业无关。不同类型的用户关注的信息特征不同,对相同的信息特征关注的程度也有所差异。实验型用户共关注37个兴趣域,调查型用户共关注31个兴趣域。调查型用户会关注图表、数据时间、缺失数据等信息特征,而实验型用户则完全不关注;实验型用户会关注数据描述、分析结果、实验方法、基因功能、基因长度和基因序列等信息特征,而调查型用户则完全不会关注。相关标准的认知处理过程呈现出两个特点:(1)一重刺激,多重反应。一个信息特征透过不同用户的眼睛,会刺激生成不同的线索,从而触发不同的相关性标准。由于认知差异的变化,同样的信息特征用户感受到刺激不同,调用大脑的相关性标准也会发生变化。(2)多重刺激,一重反应。不同的信息特征也会刺激用户调用相同的相关性标准进行相关性判断。用户关注到题目、摘要、关键词、名称、数据内容、数据描述、物种等时都会刺激调用主题性。用户关注到经过审计的,期刊,作者,机构等时都会刺激调用权威性。
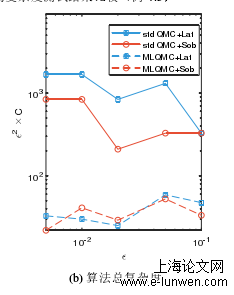
算法总复杂度
摘要
ABSTRACT
英文缩略表
第一章引言
1.1问题提出
1.2研究内容和意义
1.2.1研究内容
1.2.2研究意义
1.3研究思路和方法
1.3.1研究思路
1.3.2研究方法
1.3.3分析方法
1.4关键概念
1.4.1科学数据
1.4.2用户相关性
1.4.3相关性判断
1.4.4用户相关性标准
1.4.5信息特征
1.4.6线索
1.5论文框架结构
第二章国内外研究进展
2.1相关性发展概述
2.1.1作者、机构和国家分布情况
2.1.2学科分布情况
2.1.3相关性研究的主题及热点分析
2.2相关性标准梳理分析
2.2.1文献相关性标准
2.2.2网页相关性标准
2.2.3图像相关性标准
2.2.4音乐用户相关性标准
2.2.5不同信息载体类型下相关性标准对比分析
2.3科学数据
2.3.1科学数据特点
2.3.2科学数据相关性标准
2.4本章小结
第三章用户相关性判断理论基础及科学数据用户相关性判断模型
3.1用户相关性判断理论基础
3.1.1信息行为学理论
3.1.2认知心理学理论
3.1.3相关性判断模型
3.2科学数据用户相关性判断概念模型
3.3本章小结
第四章科学数据用户相关性标准集合及其分类
4.1问题提出
4.2实验设计
4.2.1实验方法
4.2.2第一阶段实验——深度访谈
4.2.3第二阶段实验——调查问卷
4.3科学数据用户相关性标准集合及概念
4.3.1主题性
4.3.2可获得性
4.3.3质量
4.3.4规范性
4.3.5权威性
4.3.6全面性
4.3.7便利性
4.3.8可用性
4.3.9时效性
4.4科学数据用户相关性标准分类
4.5科学数据用户相关性标准与文献用户相关性标准对比分析
4.6不同用户科学数据相关标准对比分析
4.7讨论
4.8本章小结
第五章科学数据用户相关性标准认知处理过程
5.1问题提出
5.2实验设计
5.2.1实验方法
5.2.2眼动观测法
5.2.3被试
5.2.4任务选取
5.3数据分析和处理
5.3.1数据采集
5.3.2数据分析
5.4科学数据信息特征
5.5不同用户类型科学数据信息特征关注差异研究
5.6科学数据信息特征、线索与相关性标准对应关系
5.7各个相关性标准的认知处理过程
5.7.1主题性相关性标准的认知处理过程
5.7.2质量相关性标准的认知处理过程
5.7.3可获得性相关性标准的认知处理过程
5.7.4全面性相关性标准的认知处理过程
5.7.5便利性相关性标准的认知处理过程
5.7.6权威性相关性标准的认知处理过程
5.7.7时效性相关性标准的认知处理过程
5.7.8可用性相关性标准的认知处理过程
5.7.9规范性相关性标准的认知处理过程
5.8讨论
5.9本章小结
第六章科学数据用户相关性标准使用特征
6.1问题提出
6.2实验设计
6.2.1实验方法
6.2.2被试选取
6.2.3实施过程
6.2.4权重的计算
6.3实验情境下科学数据用户相关性标准使用
6.3.1实验情境下相关性标准使用频次
6.3.2实验情境下相关性标准使用频次与重要性分析
6.4相关性判断中科学数据相关性标准权重
6.4.1实验性用户数据相关判断过程中获得成本权重计算
6.4.2科学数据用户相关性标准权重
6.4.3用户相关性标准使用特征分析
6.5讨论
6.6本章小结
第七章结论与展望
7.1研究结论
7.1.1科学数据用户相关性标准集合
7.1.2科学数据用户相关性标准认知处理过程
7.1.3科学数据用户相关性标准使用特征
7.1.4科学数据用户相关性判断模型
7.2创新性分析
7.2.1理论创新
7.2.2选题视角的创新
7.2.3研究方法的创新
7.3研究不足与未来展望
7.3.1研究不足
7.3.2未来展望
参考文献
论文写作涉及到的论文选题、标题、摘要、提纲、开题报告、答辩等方面,本网为大家提供相关的写作素材,有任何问题,欢迎随时咨询

