量化金融论文哪里有?本文创新点主要有以下三点。首先对于金融市场的多维的时间序列特征用切片的形式作为某一时刻的数据特征图,即 2.2.3 节中描述的时间序列特征图,这样在可以把更高维度更多的特征信息输入给深度卷积神经网络。第二,将深度卷积网络用一维卷积的形式改造,使其适用于除了上述特征输入。第三,将改造的深度卷积网络结合强化学习,模拟真实的市场交易环境,将此算法应用在期货市场交易之中,填补了我国在这方面的研究空缺。
1 绪论
2.1.4 卷积神经网简介
20 世纪 60 年代初,David Hubel 和 Torsten Wiesel 从约翰霍普金斯大学和 StevenKuffler 一起来到哈佛大学,在哈佛医学院建立了神经生物学系。他们们中提出了感受野,Receptive fields,的概念[17]。日本科学家 Kunihiko Fukushima 在 1980 年的论文[9]提出了一个包含卷积层、池化层的神经网络结构。1989 年 Y。LeCun 等人提出了 LeNet,将反向传播算法应用到这种神经网络结构的训练上,就形成了当代卷积神经网络的雏形[10]。(卷积神经网以下简称 CNN),CNN 发展了 30 年,现在成为了计算机视觉主流应用且取得不俗的成果。2012 年,Hinton 的学生 Alex Krizhevsky 提出了深度卷积神经网络模型 AlexNet[15]以较大差距赢得了 ILSVRC 2012 比赛。将网络深度提高到了 19层的 VGGNet[11]在 2014 年获得了 ILSVRC 比赛的亚军和定位项目的冠军,在 top5 上的错误率为 7.5%,而 Google 将层数提升到 22 层的 InceptionNet[12]以 top-5 错误率6.67% 获得了同年的冠军。在 2015 年的由 Kaiming He 等人提出的残差网络[16]获得ILSVRC 冠军,将网络深度提升到 152 层,取得 3.57% 的 top-5 错误率,同时参数量却比 VGGNet 低。这之后还出现了 DenseNet,ResNeXt,DPN,SENet 等一系列优秀的网络结构。下面介绍卷积网络的基本要素。

量化金融论文
.......................
3 从交易的角度探索更优的交易模型
3.1 模拟交易数据集来源以及特征选取
本文下面的所有模型都基于上证交易所的螺纹钢期货市场,使用螺纹钢的主力合约分钟线数据集,主力合约能够保证交易的流动性,能够即时买卖,降低模型因流动性而产生的风险成本。总数据量为 274095。虽然强化学习不存在交叉验证的说法,但本文仍将原始数据分为原始训练集和原始训练集,训练集为 RB1610、RB1701、RB1705、RB1710、RB1801、RB1810 其作为主力合约的时间段的数据,测试集为 RB1901、RB1905、RB1910、RB2001、RB2005 其作为主力合约时间段的数据。
建立特征的方法与第二章中的数据集特征选取方法一致。主要特征包括: 开盘价,最高价,最低价,收盘价,移动平均线 (MA),布林线 (BOLL) 的上下限,指数移动平均线 (EXPMA),顺势指标 (CCI),随机指标 (KDJ),(MACD),变动率 (ROC),相对强弱 (RSI),威廉指标 (WR),真实波动率 (ATR),平均价格 (AVG),中位数价格 (MID),n 天价格差等。对以上特征中含有时间间隔 n 的特征,按 n = 3, 5, 7, 10, 20, 30 的间隔,再生成新的特征,一共 90 个特征。最终的时间序列特征图数据集的建立方法与第二章中的时间序列特征图数据集建立一致。
.......................
4 深度强化学习交易模型的模拟交易: 使用改造后的密集连接网络-PPO 模型
4.1 模型概述
这里使用 Proximal Policy Optimization Algorithms(PPO) 算法并结合第二章的改造的 DenseNet 进行试验。PPO 算法本质上属于 Actor-Critic 算法,它有两种主要变体:PPO-penalty 和 PPO-clip。PPO-Penalty 近似解决了像 TRPO[30]这样的受 KL 约束的更新,但是对目标函数中的 KL 散度偏离进行了惩罚,而不是使其成为硬约束,并且在训练过程中自动调整了惩罚系数,以便对其进行适当缩放。PPO-Clip 在目标中没有 KL散度项,也没有任何约束。取而代之的是依靠对目标函数的专门裁剪来防止新策略与旧略策相差过大。PPO-clip 更新策略通过下面式子:

模型概述
............................
4.2 模拟交易实验结果
按照 Algorithm 4 中的逻辑框架,在环境中执行策略,每个 EPOCH 收集 4000 个时刻的即时轨迹数据,执行 400 个 EPOCH,一共 1e6 个时刻的轨迹数据。在考虑成本的情况下测试集对应的最终收益迭代曲线如图 4.1 所示,图 4.2 为 400EPOCH 后最终得到的模型的一次从头到尾的期货主力合约测试集资金曲线:
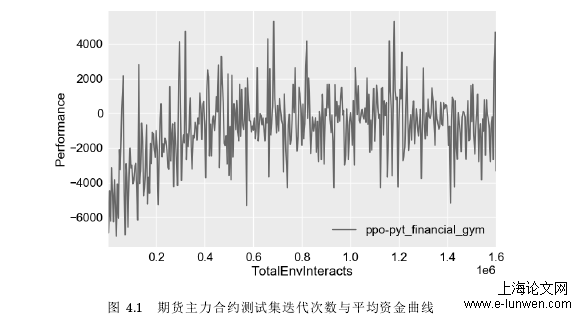
图 4.1 期货主力合约测试集迭代次数与平均资金曲线
.............................
结论
由于目前我国在金融领域交易中的深度强化学习技术的应用尚少,本文为这方面的稀缺进行了填补。
本文前半部分的实验选取了上证指数 2005-04-08 到 2020-03-13 的数据进行实验,实验结果表明,一维卷积形式能够适应时间序列特征图的计算,其表现超过其他对照组,表明该方法的有效性。
本文后半部分探索了交易模型,选取了螺纹钢合约 (即 RB1610、RB1701、RB1705、RB1710、RB1801、RB1810、RB1901、RB1905、RB1910、RB2001、RB2005 合约主力期间的数据),对比随机交易模型和 VPG 模型实验,VPG 算法能够极大地延长持续交易时间,而一维卷积形式的 DenseNet-PPO 算法能够在测试集的交易中一直存续,相比前两者进一步缩小了与最优模型的利润差距,并且在不考虑高频交易导致的成本后,能够达到盈利。在本文所做的交易中,其假设比较僵硬,没有考虑仓位的设置以及止损等等,同时为了因为减少流动性所产生的成本而假设每次交易量为 1 手,使其不会对市场中其他交易者的行为以及金融标的价格造成影响。资金量较大的时候,就应当考虑自身交易对市场价格带来的影响,因此有必要进行更深入的研究。此外,虽然本文仅针对金融期货市场进行了实验,但这一方法对于其它市场是否也适用,有待于进一步探索。
参考文献(略)

