本文是金融论文,通过上述的研究结果表明:利用数据包络分析对数据进行一些指标预处理,在传统逻辑回归模型中增加DEA效率值,能够提高模型准确率。此外,从表5-4所示的两次的相关性结果可以发现,用户调查问卷中小额消费贷款意愿分填写的分值越高,用户的借贷此款产品的意愿越强烈。其次是积分账户的加挂数和车加挂账户数。用户的积分账户数越多,信用卡加挂数越多和拥有的车辆越多,用户的借贷此款产品的意愿也是很高的。但是产险加挂的账户和个人银行加挂账户越多的人群,反而借贷的意愿很低。对于二次处理后的数据包络分析的效率值,也是呈现负相关性,即用户的效率值越低则使用网贷产品的可能性越大。所以,在日后有效用户的选择中,更倾向于营销触达问卷中意愿值更高的,积分账户数、车辆加挂数和信用卡加挂数更多的,但产险和个人银行账户数越少和效率值低的用户。最重要的是选择,在新名单用户以及数据获取后,可以通过以上模型训练,选择前五个分位的用户进行短信营销,能够实现命中接近90%的有效用户,获取更高的营销回复率,以最低的成本获取最大的有效客户,提升产品投入产出比。
.......
第一章绪论
在互联网金融产品快速的发展的同时,由于中国人民银行个人征信中心系统提供的产品与服务不能满足某些企业的定制性产品需求,互联网金融机构还需要自身数据库体系和民营的市场第三方机构作为补充。所以,只通过个人征信行业的信息衡量用户信用状况和产品使用意愿,在网贷产品有效客户的识别过程中是远远不够的。征信是互联网金融发展过程中的一片重要蓝海,特别是P2P网贷和大数据金融等新融资模式的出现,对互联网参与用户的信息搜集、挖掘与分析提出迫切的要求,由此大数据时代背景下的个人征信需求也就随之而来。由中国人民银行批准1999年7月建立的上海资信有限公司开始试点个人征信业务,历经近20年的发展,目前已经形成了较为系统化的征信体系。随着时代的进步和技术的成长,个人征信体系也经历了三个时代:工业化时代、电子化时代、互联网时代。与此同步成长的也有传播方式、存储方式和计算预测方式。互联网个人征信应运而生。(图1.1)2016年,伴随着政策的放开,互联网金融的快速发展,我国个人信贷业务发展迅猛,初步形成以政府为主,社会征信机构、信用评级公司为辅的多元化征信市场。随后,个人征信行业正式进入发展高潮。大数据征信模式是网贷平台和互联网金融公司不可或缺的部分。利用大数据的方式搜集征信数据,使得数据维度打破了原有的局限,从过去的手动输入到现在互联网平台及移动端设别的多渠道数据输入,有助于对信息主体的多方面信息掌握,更加全面的了解信息主体的各类特征。
......
第二章互联网消费金融贷款产品现状分析
2.1互联网消费金融贷款的发展现状
近年来,随着互联网技术与传统金融行业不断融合,互联网金融行业不断进行细分,互联网消费金融模式兴起,主要表现为针对个人用户提供小额消费贷款的活动,由于对用户行数据的搜集,信用状况的把握和风控体系的提升,互联网消费金融模式可以更好的将个人消费信用贷款业务嵌入到消费场景中去,发展更具有优势。本文研究的互联网金融背景下的消费信贷属于互联网消费金融这一创新金融领域。据艾瑞咨询发布的《2018年中国互联网消费金融行业报告》数据显示,2017年我国互联网消费金融放贷规模达到4.38万亿元,较2016年增长了904%;2018年,居民房贷持续转移,我国金融理念的渗透和场景布设提升消费金融渗透情况,互联网消费金融放贷规模持续走高,全年达到约9.78万亿元,同比增长122.9%。显然,我国互联网消费金融贷款产品正处于突破式快速发展的阶段。
2.2互联网消费金融贷款产品问题表现及成因
据中国人民银行征信中心2017年度7月月报数据显示,自从工作开展以来,已提供了45.21亿次个人征信报告的查询,主要提供:一是个人基本信息,包括姓名、证件类号码、通讯地址、联系电话、婚姻状况等;二是信用交易信息,包括信用卡、贷款、其他信用信息;三是其他信息。因此,央行的信用数据库在金融信贷产品中处于重要地位。但是,央行征信系统中存在的信用信息很难覆盖到线上金融客户。互联网消费金融贷款的用户中,有一大部分客户群体是在央行征信体系中信用空白的用户,这些用户的信用信息是搜集不到的,所以,无法根据央行的征信报告了解此类用户的信用状况,判别此类用户的偿还能力。此外,央行征信报告的数据主要集中于用户的个人基本信息、信用交易信息和报告查询等其他信息。征信报告的这些数据不能帮助互联网消费金融机构判别出用户是否是某款网贷产品的有效用户。因为,数据维度不够全面也不够深入。首先,数据集没有涉及用户在电子商务平台上的交易消费信息。其次,也没有包含互联网金融领域的金融数据,更没有用户在浏览网贷产品的痕迹数据等。所以,互联网金融公司无法仅仅通过央行征信报告准确的做出用户画像,对借款人作出很有效的贷前调查,无法识别出网贷产品潜在的有效用户。
........
第三章大数据信贷产品有效用户识别案例分析...................................19
3.1 用户信用识别.....................19
3.2信贷产品有效用户识别.....................20
3.3本章小结.....................22
第四章客户数据指标选取与预处理方法.............................................24
4.1互联网金融贷款产品介绍.....................24
4.2数据准备.....................25
第五章Logistic-DEA有效用户识别模型................................34
5.1Logistic-DEA模型流程.....................34
5.2逻辑回归模型训练与结果.....................34
5.3数据包络分析(DEA)模型.....................36
........
第五章Logistic-DEA有效用户识别模型
5.1Logistic-DEA模型流程
由于本研究所用数据的维度广泛而复杂,涉及的数据量大,因此Logistic-DEA的模型由一系列步骤组成。此模型可以应用于任何大型数据集,无论是什么行业,什么领域。本研究使用DEA对数据进行预处理,因为它可以区分每一位客户,以衡量他们各自的效率价值,而不是将他们分为不同的类别。这个方法可以提高模型预测的精准度,使初始LG模型的预测更加有效。Logistic-DEA模型简称为DEALG方法,主要是根据最初的LG方法的初始结果,选取数据包络分析(DEA)的输入和输出值,从而运用MaxDEA软件计算每个客户作为决策单元(DMU)的效率值。由DEA获取的效率值作为一个新的指标,将与初始回归得出的相关指标一起用于LG模型的训练和测试。最后,利用该模型对客户进行对企业营销文本信息响应的必要的测试,验证了此模型的有效性和准确性,有助于分析增加DEA指标对于逻辑回归模型贡献。
5.2逻辑回归模型训练与结果
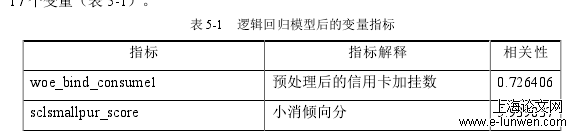
Manirad,Cook和Aviles-Sacoto等学者(2015)质疑了运用所有输入值和输出值进行原始的DEA模型的效果。于是,他们发现找部分输入和输出指标会使得模型效果更佳[61]。Eddie(2007)指出数值越大越好的放入产出指标,数值越小越好的放入投入指标[46。DEA效率值的相关性为负相关,效率值越小的用户越容易申请此贷款产品,与实际情况相符。所以,根据逻辑回归得出的指标相关性和经验,最终选择3个输入指标,6个输出指标。存款加挂账户、产险加挂账户数和基金倾向分位区间在相关性上是负相关,并在实际情况中的表现也是客户拥有越多的存款、产险和越大的基金意愿是小额消费贷款意愿较低,车加挂账户数、积分账户数、金融账户数、小额消费贷款意愿、信用卡使用意愿以及过去30天内的登录次数的相关性是正相关,且在实际情况中也是值越大,小额消费贷款意愿较强。所以,最终选择出以下9个指标。(表5-3)[1]
..........
结语
通过上述的研究结果表明:利用数据包络分析对数据进行一些指标预处理,在传统逻辑回归模型中增加DEA效率值,能够提高模型准确率。此外,从表5-4所示的两次的相关性结果可以发现,用户调查问卷中小额消费贷款意愿分填写的分值越高,用户的借贷此款产品的意愿越强烈。其次是积分账户的加挂数和车加挂账户数。用户的积分账户数越多,信用卡加挂数越多和拥有的车辆越多,用户的借贷此款产品的意愿也是很高的。但是产险加挂的账户和个人银行加挂账户越多的人群,反而借贷的意愿很低。对于二次处理后的数据包络分析的效率值,也是呈现负相关性,即用户的效率值越低则使用网贷产品的可能性越大。
参考文献(略)

