本文是经济论文,对于股票预测,从不同的角度和损失函数考虑,分别建立支持向量分类机和支持向量回归机要比单独建立其中一个预测的性能要好。鉴于模型复杂度和预测准确率的提升程度而言,在股票预测问题上,滑窗周期数设为3是比较理想的结果,相对于股票数据五天的交易周期,是一个较优的选择。提升支持向量机模型性能的关键是找到最优的参数σ和C,而不同的参数调优方法会给该过程带来不同程度的便利,就本论文的研究而言,遗传算法和粒子群算法是完全更优于普通的网格搜索法的,且粒子群算法的速度要优于遗传算法,但是就建模过程而言,还是综合考量两者的预测结果折中较好。通过自然语言处理进行新闻情感分析产生情感特征变量,对模型性能进行对比评估可以发现,新闻情感特征所带有的信息增益是比较大的,能给模型性能带来较大的提升.本文利用支持向量机模型同时进行涨跌的分类预测和基于回归的趋势模拟,等同于支持向量分类机和支持向量回归机两个弱学习器通过不同权重的组合为一个强学习器,从而能更好地提升股票预测性能,同时能够更好地解析预测结果。本文不同于以往研究将原始数据只是单独的作为一个整体,而是将原始数据分为牛市、熊市和盘整期三个阶段的预测情况和个股整体预测情况进行对比分析,从而能够确定不同阶段的最佳预测模型,而不会造成在各个阶段性能良莠不齐,同时能够给不同阶段股民给出不同的投资建议。
......
第一章绪论
由于股票市场的时效性,每天大批量数据的产生,迄今为止,股票市场已经累积了足量的历史数据,借此契机,专家学者们获得大量研究数据,得以在股票市场的研究上大展拳脚。然而股票的价格受到大量因素的影响,这使得股价的预测不是那么容易,但是,随着机器学习技术的发展,使得从海量信息中挖掘出来对股票预测极其重要的信息有了可能,所以股票预测这项工作依然是具有极高的价值和意义的。在股票买卖过程中,如果建立了金融预测模型,我们将历史数据灌入,学习到参数,从而对未来的股票价格进行预测。假如模型的预测价格高于当天的收盘价格,即模型告诉我们未来股票价格可能出现上涨,则我们可以继续持仓这只股票以期获得后续更高的投资收益;另外,情况相反时,我们可以根据模型的建议采取相反的举措与动作。所以建立一个准确且高效的股票预测模型对于投资者更好的收益显得非常有意义,当然,找到这种股票价格上涨下跌趋势的规律对于国家宏观调控和企业的经营管理也是有很高的现实价值的。(1)本文通过在不同参数优化算法上对比分析选取较为有利的参数优化方法改善传统的网格搜索法在模型性能和速度上的不足,另外引入了前沿的多核支持向量机算法以提升模型的预测性能。
......
第二章文献综述
2.1股票预测研究现状
综上所述,迄今为止专家学者们对支持向量机算法在股票预测上的应用做了大量研究,从各个方面进行了深入探索。相比传统的时间序列方法,像Arima、Garch和蒙特卡洛模拟法,新兴起的机器学习算法(如神经网络和支持向量机)在股票时间序列的预测上有着更不错的效果。支持向量机算法应用到股票时间序列预测上的发展时间不算长,众多专家学者仍然在不断地就支持向量机算法在股票预测上应用的改进和优化做着大量的尝试和努力,希望改进支持向量机算法的弊端和局限性使其在股票时间序列的预测上取得更好的效果,其中的难点和痛点主要集中在下面几个方面。现总结归纳如下:(1)组合模型参数难以确定。一部分学者为了提高支持向量机在股票预测上的性能,寻求各种模型与支持向量机模型的组合,组合模型比单一模型能够更好的处理股票数据中的非线性和线性特征。但是由于支持向量机模型的参数过多,并且模型最终表现是优是劣也受到初始参数的设置的影响。组合模型很容易使得在参数选择上的难度增加(参数数量成倍增加)。
2.2本章小结
本章主要分析了历年的相关文献,然后介绍了迄今为止支持向量机(SVM)在股票市场预测方面的应用现状,当前的研究技术热点以及支持向量机参数调优理论,最后是关于支持向量机模型的性能改进方法的文献综述。另一方面,参数选择也是一个困难工作,主要依赖个人经验和交叉验证选择,往往在硬件的要求上比较严格,否则效率过低,另一方面也较受主观因素的影响,基于这几点,参数的最优化过程比较困难,所以模型的预测结果达到最优比较困难。基于前述分析可知,普通支持向量机在调节参数的时候需要考虑到核函数的选取,然而选用何种核函数往往是凭经验而为的,比如说从业者在选择模型核函数时喜欢选择高斯径向基核函数,但是这只能针对同构的数据集,假使数据集一旦异构,就难以得到满意的效果。
第三章股票市场及支持向量机等相关算法概述................................................................................................14
3.1股票市场相关知识概述..........................................................................................................................14
3.2支持向量机算法及相关理论..................................................................................................................17
3.3情感分析技术..........................................................................................................................................24
第四章股票市场预测指标体系构建及处理.......................................................................................................33
4.1数据获取..................................................................................................................................................33
4.2股票市场预测指标体系构建..................................................................................................................34
第五章基于支持向量机的股票市场预测...........................................................................................................49
5.1股票市场预测模型构建..........................................................................................................................49
5.2股票市场预测模型的参数优化及改进..................................................................................................55
5.3股票市场预测模型结果评估及对比分析...............................................................................................59
.....
第五章基于支持向量机的股票市场预测
5.1股票市场预测模型构建
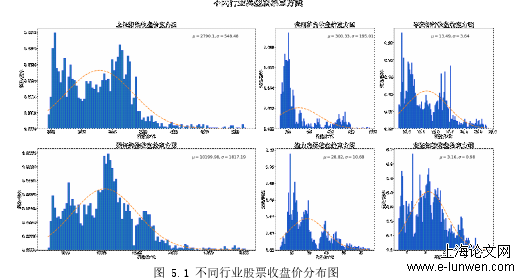
可以发现,无论哪支股票,收盘价都没有表现出正态分布的迹象,收盘价并没有完全围绕在一个恒定的均价上下浮动,这也给股票分析带来了一定的困难,这种时涨时跌的状态,正是股票数据较难处理的地方,而且伴随着牛市和熊市出现多峰分布的现象,值得注意的是收盘价在中低价位的天数分布较多,所以进行建模预测的时候,如果使用传统回归模拟,这些高价数据很容易给回归线带来拉扯偏离,支持向量机完全能克服这方面问题。接下来将原始数据预测列抽出,也即收盘价,进行建模准备。我们用当天的收盘价减去前天的收盘价作为涨跌情况的判断,高于前一天的收盘价即为上涨,低于前一天的收盘价即为下跌,接着进行数值化处理,将上涨转化为数字1,下跌转化为数字0,以此作为二分类预测变量。借助上一章节主成分处理的方法,将特征数据降到二维进行可视化,观察数据的分布情况,以贵州茅台为例,红色的点为上涨,白色的点为下降,如图5.2所示:观察可以发现,上涨和下跌的数据点完全集中在一起,完全的非线性可分形态,在较低维空间难以找到一个超平面将两类数据点完全分开,所以需要转化到高维空间来找到最优超平面,根据第三章非线性可分理论,对于这种高维线性不可分数据,高斯径向基核函数是最好的选择。
5.2股票市场预测模型的参数优化及改进
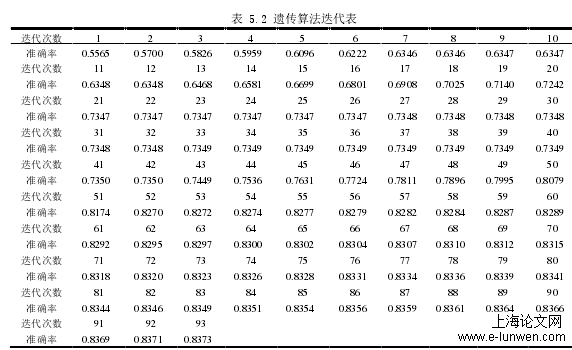
可以看到,当算法迭代了93次之后结果最优,结束迭代,参数????的取值为0.1031,参数C的取值为247,对应的预测准确率相比网格搜索法有所提升达到了0.837317,消耗时间356.28秒。模型迭代次数与准确率表现如图5.6:与遗传算法同样使用高斯径向基核函数,对参数和参数C进行参数调优,在粒子群算法中,两个参数相当于使用二维粒子,算法具体的实现过程中,粒子的两个参数维度相互独立、互不影响,各自拥有各自的速度和最优位置,往往因为这些特性,粒子群算法在支持向量机参数调优的应用中表现良好。同样,设置粒子群算法的初始参数:初始粒子数:8;自我学习因子1设置为2,种群学习因子2设置为2,速度范围:-10~10;惯性权重:0.8;另外重点说明,粒子位置的更新由粒子本身的速度决定,而参数和参数C的移动速度相对独立,而基于此,算法的收敛速度更加获利。最终利用粒子群算法的实验过程和结果如表5.3所示:所以针对单核支持向量机在处理异构数据上的劣势,能够组织多个核函数协同作用来进行异构映射的多核学习器(MKL)得以登场。组合模型相对更加灵活,可以通过各个单核不同的特点映射到组合高维空间中不同异构空间上,从而充分利用各个异构特征的特点来提高模型的预测性能,具体过程如下:1)选择一些常见单位核函数,例如Sigmoid、RBF、Polynomial和linear,假使选择了M个单位核函数,则可以通过线性组合的方式通过不同系数组合来形成组合核函数。2)通过实验,训练出这一组线性组合模型中每个核的权重系数d(weight)。
....
第六章总结与展望
将数据周期划为牛市期和熊市期分别建立支持向量机模型是一种较好的选择,能明显优于在整个盘整期建立支持向量机的预测性能,而搜索热度指数指标在这两个时期的支持向量机建模过程中似乎能起到一个不错的效果。虽然支持向量分类预测股票涨跌和支持向量回归拟合股票指数对于投资者每天监控投资持有的股票是一件势在必行的事,但是在这之外通过股票组合投顾策略进行股票的选取何尝不是一件有利于投资的事情,完全能够帮助投资者刚好的盈利。虽然牺牲了一定的速度性能,但是改进的支持向量机模型多核支持向量机还是给模型的预测能力带来了提升,在远大于一天的持仓周期下,牺牲速度成全模型预测能力实际上对于投资者完全是不用犹豫的。支持向量机在股票预测上的应用是一个复杂而繁琐的过程,要想达到最理想的预测结果,需要综合考量建模过程中的各个影响因素。因为此处融合了多种核函数的特点,能够同时兼顾到多种异构特征。通过不同核函数的特点映射到不同异构空间的特征。另外可以根据学习到的系数自动加权选择不同的核函数,侧重不同的特点。但是由于相比传统支持向量机,多核支持向量机除了要学习参数w和参数b以外,还要学习权重参数d,但是这个时候相应的合页损失的求解就不是一个凸函数了,相应的求解也变得很困难。
参考文献(略)
参考文献(略)

