第1章 绪论
1.2 国内外研究现状
从深度学习技术的提出到发展,该技术逐渐推广到了动作识别领域中。深度学习技术在动作识别领域发展开始是一帧一帧的输入到多帧的输入、从队列 RPG 图像矩阵发展到利用多特征融合的方法、由开始的使用卷积神经网络处理动作识别问题到引进循环神经网络和其他新的网络、卷积神经网络也从二维神经网络无法对时间信息进行特征提取发展到三维神经网络保留了时间上的信息。深度学习技术随着不断地发展渐渐成为了动作识别的主流方法,被研究者们所接受和推广。深度学习在图像处理的最开始应用阶段,设计者最开始的设计思路是:将视频截取成若干个图像帧,通过图像帧来表达视频特征,这种方法在今天也仍在应用。接着把截取后的图像帧数据放入到 RNN 层中进行训练分类[13],最后得到每一张图片的分类预测结果,再对结果进行处理获得最后的预测结果[14]。通过上述步骤可以看到,它是通过深度学习的方法将视频信息通过图像粒度的形式进行表达。然而,虽然这种方法在低数据量和低类别分类中取得了不错的成效,但是随着数据量和分类类别的增加,一帧一帧的图像输入有一个明显的缺点就是它忽略了图像与图像之间上下文的联系。这种方法对于相对静止的视频数据或许表现可以,但是对连续动作的视频数据表现效果并不理想。 随着技术的不断发展,卷积神经网络的提出成功的在图像分类中表现出了优秀的效果,于是研究者开始利用它对视频分类问题进行处理。但是最开始并不是一帆风顺,研究者在 ImageNet 数据集上进行了实验,结果发现卷积神经网络并没有表现得令人满意,它的识别率比起过去的分类方法大概只提升了 5%的准确率。当时研究者对这种现在认为是因为数据集的数量不够大时。紧接着,谷歌提出了一种名为 Sports-1M 的数据集,这种数据集相比传统数据集它的数据量远远大于过去,它的量级可达百万。有了谷歌公司的数据支持,人们又对该数据集进行了深度学习的实验,然而这种方法仍旧没能达到令人满意的效果。研究者发现通过深度学习技术融合特征的方法能够融合出新的特征,这个方法迁移到在 UCF101 数据集上的准确率并不高,它的准确率只达到百分之六十。在此之后,研究者开始对深度学习中不足的算法进行完善和改动,希望通过改进来提升提高视频分类的分辨效率。这一思路一个有效的工作是 Facebook 公司设计出的 C3D 神经网络。这种新的方法将过去 2D 信息不能够处理的时间信息特征进行保留,使得 3D 卷积神经网络可以保留时域上的信息[15]。C3D 网络它将过去的 VGG 网络中 3×3 的卷积核修改成 3x3x3 的三维卷积核 [16]。

软件工程论文
第3章 深度学习算法
3.1 FSTCN网络模型
这一小节我们来介绍 3D 和 2D 两种卷积神经网络,3D 卷积神经网络主要运用在视频分类和模式识别上,它由 2D 卷积神经网络发展演变而来。这是因为当时 2D卷积神经网络在处理图像时序上,它并不能很好地捕获数据时序信息,这是因为当我们输出一个二位特征图时,它的多通道信息并没有很好地表现出来,而是被压缩了。但是 3D 卷积神经网络就完全将信息保留了下来。换句话说,就是 2D 卷积神经网络在解决视频分类问题时,分类方法通常仅仅只是处理划分的多批次的视频帧问题。这种方法仅仅只是对图像矩阵数据进行处理,并没有考虑帧与帧之间的联系关系。3D 卷积因为增加了时间空间元素,提供了帧与帧之间时间关系联系的桥梁,能够在帧与帧之间保留时空领域的信息。
与传统二维的卷积网络相比,三维卷积神经网络在池化和卷积层能够保留过去二维卷积池化没有的时间领域内的信息。传统二维卷积舍弃了时间上的数据特征,和之前的二维卷积神经网络相比,三维网络利用了多帧图像的信息。三维卷积是利用卷积核,处理堆积的信息。因为特征图像中图像信息前后文相联系,与多帧图像存在时间上的关联,因此三维卷积网络可以获得帧间运动信息。
3D 网络结构和 2D 网络结构在视频分类都发挥着重要作用,视频序列里的人物动作代表着三维的时空信息,包括了人物的动作和时间上的变化,高维的卷积核带来了更大的复杂性和对训练数据的要求,早先计算机计算能力和运算水平还没能达到对网络训练的要求能力,因为受制于计算机的计算能力问题,同时网络训练时间成本等原因,2D 神经网络是过去主流的网络模型结构,后来有人提出了许多将三维信号分解到低维训练学习的方法,比较有代表性的就是 FSTCN 网络模型。
.......................
第 5 章 实验
5.1 实验环境介绍
实验选用的编程工具是 Pycharm 软件和 Jupyter Notebook 软件,使用 python3.6的环境。近些年,因为 python 具有可扩展性、类库功能(包含许多科学计算的包,用来进行数据分析和科学实验),优良的代码可读性和在机器学习数据分析领域内的良好表现,使得使用 python 能更快更好的解决人工智能方面的许多问题。其中本文主要网络架构代码实验环境搭建在 Pycharm 上运行,Jupyter Notebook 用于数据预处理和实验测试。计算机环境是 Windows10,本地处理器是 Inter(R) Core(TM)i7-6700 CPU @ 3.40GHz 3.41GHz 型号机器,基于 64x 的处理器。Python下实验的框架目前主流有四种:Tensorflow、Keras、PyTorch、MXNet。其中本文使用的是 Tensorflow 框架,它是四种开源框架之中,最流行、使用最多的框架,之所以选用 Tensorflow 的其中一个原因是它有 TensorBoard 应用,它可以监控网络状态,运行情况,并且能产生可视化的计算图。
首先搭建 python 环境,我们从 Python 官方网站:https://www.Python.org 下载它的安装包。下载获取得到 Python-安装包,接着安装 python 程序,通常来说,我们安装好 Python 打开字后直接进入编程界面。打开 cmd 程序输入 Python,就可以查看 Python 的交互功能,若没有反应,那么可能是需要设置一下环境变量,需要做一些调整。紧接着我们在 Windows 的路径添加 Python 的目录,然后在计算机->属性->高级系统设置->高级->环境变量,完成设置。
另外由于本次实验是一个分类问题,为了减少实验的时间成本和选择最合适的实验框架,必须选择更适合分类的框架结构。为此对比了上述四种框架在著名的基于 Mnist 数据集分类上的表现,Mnist 数据集是由 6 万张训练样本和 1 万张测试样本共同组成的训练集,每一个样本大小为 28*28 的灰度像素手写数字图像。实验设计是设计最简单的两层卷积层和两层池化层,最后加全连接层的网络结构,分别在四种框架下进行分类训练,最后实验结果如表 5.1 所示(GPU0 表示电脑集成显卡,GPU1 表示独立显卡)。
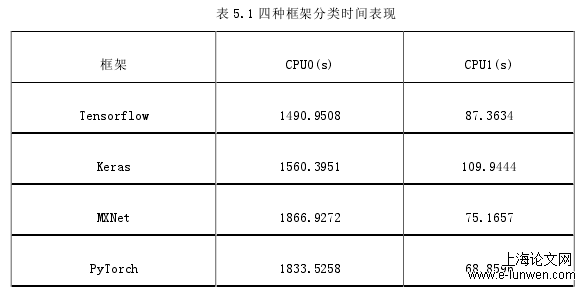
表 5.1 四种框架分类时间表现
5.2 本文实验结果以及分析
因为在模型训练的过程中由于训练集的大小和模型设计的复杂程度差距较大或者样本中噪声数据干扰数据集,使得特征提取过程中噪声覆盖了数据本来的特征等原因会出现过拟合现象,为此需要使用 Dropout 来解决过拟合问题,正如第三章中介绍的一样,本文在混合神经网络中添加了 dropout 函数[42],在一定程度上避免了过拟合现象的发生。训练前模型完成后,对训练前模型的参数进行调整,然后进行训练。在 dropout 层中可以通过设置结点的 Dropout 率(Dropout 率一般用 p 来表示)来对模型中的神经元进行丢弃,当通过 dropout 层的神经元被丢弃时,神经元内的参数也将被舍弃。通常情况下 p 值初始设置为 0.5。本次实验 p 值初始值设为 0.5。目的为了找到最适合的参数值,最适合这个网络模型。本次实验数据训练准确率和测试准确率如下表 5.2 所示。
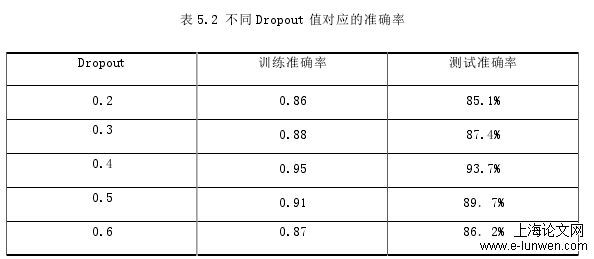
表 5.2 不同 Dropout 值对应的准确率
第 6 章 总结与展望
6.2 展望
再对视频分类问题不断地实验和研究后,我们发现深度学习可以很好地处理视频分类问题。由于时间有限,对于音频在视频分类中的作用没有展开系统深层的研究。但是毫无疑问音频特征对未来视频分类打开了一扇新的大门。同时对于视频数据集处理方面也存在一些遗憾,希望以后可以多试试几种网络结构模型,并且可以把几种网络结构进行整合,再构造一种新的神经网络结构。通过不断地尝试和分析,使得对视频分类问题达到一个新的认知高度,可以表现得更好,更加完美。最后对于音频在视频中的作用将会是未来视频分类的一个重要特征,因为声音是视频的一个重要组成成分,我们听到篮球声就知道是在打篮球,不需要画面我们就能知道视频大致内容和篮球有关,我们听到滴滴答答声就知道是雨天,这种模糊特征对解决视频分类问题是很好的帮助。我相信未来视频分类可以通过一些算法将音频特征和图像特征更好的融合在一起,更快速更高效的解决视频分类问题。
参考文献(略)

