本文是语言学论文,在研究了国内外自然语言处理技术文献的基础上,对目前自然语言处理技术的发展和应用进行了分析。针对文本分类领域的算法进行了深入研究,对于传统机器学习算法和卷积神经网络算法在文本分类应用时出现的问题,提出了新的解决方案。针对机器学习和深度学习在文本分类领域应用的研究,取得了以下的研究成果:第一,词向量技术中介绍了独热编码和连续编码,介绍了SGM和CBOW,两种进行词向量训练的常用方式。提出了基于权重预处理的优化算法PRE-TF-IDF,该算法在预处理阶段增加了关键信息权重处理环节,以解决传统TF-IDF算法无法根据词语所在的位置信息进行权重值的问题。通过实验结果证明了该算法的有效性和可行性。
.....
第一章绪论
研究了基于机器学习的中文文本分类问题。针对传统TF-IDF算法与朴素贝叶斯分类器结合的文本分类模型,仅根据词语出现的频率来衡量一个词语在文本中的重要性,而无法根据词语在文章中出现的位置进行重要性评估的问题。提出一种基于权重预处理的PRE-TF-IDF算法来提高文本分类的准确性,该方法增加了关键信息权重处理与词密度权重处理,两个创新步骤,降低了词频因素对实验结果的影响,同时提升文本分类时的准确性。通过实验结果证明了该算法的有效性和可行性。(2)研究了基于深度学习卷积神经网络模型的中文文本分类问题。将CNN模型与SVM分类器进行结合,并在模型中增加了注意力机制。通过卷积神经网络对文本数据集进行特征提取,并使用基于支持向量机的分类技术替代卷积神经网络中泛化能力不足的归一化指数函数,在效率和准确性上都起到了一定程度的提升。模型使用支持向量机分类器替代归一化函数进行分类,避免了泛化能力不足的问题。同时在模型中增加了注意力机制,提升模型提取特征词语的效果,简化模型参数。
.....
第二章自然语言处理关键技术概述
2.1自然语言处理介绍
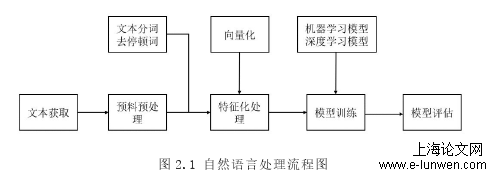
如图2.1所示,自然语言处理的流程大致可以分为五个步骤,(1)通过网络爬虫或本地导入等方式获取文本。(2)对文本进行预处理操作,将文本进行分词并去除其中的语气词和停用词。(3)对文本进行特征化处理,使用独热编码或词嵌入技术,将词语映射成对之对应的词向量形式。独热编码又称之为一位有效编码,即N位寄存器与N个状态一一对应,寄存器中只有一位有效;词嵌入技术的将词语量化到低维度的稠密向量空间,维数固定,相比于独热编码,效率更高。(4)针对模型进行训练,可以使用基于支持向量机、决策树、临近算法或逻辑回归等机器学习模型算法,也可以使卷积神经网络或循环神经网络等基于深度学习的模型算法。(5)使用测试集对训练模型进行验证,评估模型算法的优劣。针对上述五个步骤进行简单的介绍:语料库的收集大多采用网络爬虫或本地文本数据集。语料预处理阶段主要包括对收集来的语料库进行语料清理、分词、词性标注和去停顿词等操作。在特征化环节,需要对完成预处理的文本进行向量化,将完成分词的词语表示成向量形式,以便计算机能够对其进行计算。这样的操作有助于通过向量的表达方式,发现不同词语之间的相似关系。在模型训练环节,使用的训练方法包括传统的有监督、无监督和半监督学习模型等,具体使用的模型需要根据不同的应用场景进行选择。针对建模后的效果进行评价,常用的效果评估指标有准确率、召回率等。
2.2词向量技术
摘要可以使读者在最短的时间内准确地了解文章的内容,摘要对区分文本类别也起到了十分重要的作用,因此对于摘要段落内出现的词语赋予高于正文词语的权重。关键词段落常常位于摘要后一段,使用几个词语来概括文章涉及的专业领域,字数较少但概括能力极强,因此需要对关键词赋予高于正文词语的权重。针对不包含摘要和关键词的期刊文本,则不作额外赋值,统一按正文中出现词语赋值。发表单位常常会出现学校的名称、企业名称或期刊名称等。根据文本所属的出版单位信息,可以大致对文本可能涉及的领域有一定的评估。例如,一篇发表自理工类学校的文章,该文章属于计算机、电子或能源等领域的可能性要比艺术、教育或法律等领域的可能性高。通过中国大学信息查询系统,获取国内的所有的高校的名称和其所对应的专业类别,类别包含“综合类”、“理工类”、“师范类”、“财经类”和“农林类”。这五种高校类别与表3.2中八类文本专业领域分别具有不同的权重配比。
第三章基于权重预处理的中文文本分类....................23
3.1TF-IDF算法.........................23
3.2基于权重预处理的优化算法(PRE-TF-IDF)............................24
第三章基于权重预处理的中文文本分类....................23
3.1TF-IDF算法.........................23
3.2基于权重预处理的优化算法(PRE-TF-IDF)............................24
3.3实验结果与分析.................29
第四章基于卷积神经网络的文本分类算法改进........35
4.1CNNSVM模型原理............35
4.2重要参数设置.....................44
4.3实验结果与分析.................47
4.4本章小结.............................49
第五章总结与展望..........................50
....
第四章基于卷积神经网络的文本分类算法改进
4.1CNNSVM模型原理
从图4.13可以看出,随着词向量维度的增加,模型训练的精确度也在不断增加。同时,模型训练所需要的时间也在不断增加。通过精确率和训练耗时的斜率可以看出,当维度从64提升到128时,精确率增加了0.4%,但训练时间却增加了约69.3%,这样的代价并不合适。所以,在实验中需要根据不同数据集来选取合适的词向量维度。鉴于本文所用的数据集,当词向量度从64维提升到128维时准确率只是轻微提升,所以本实验中将词向量的维度选择为64维。模型所能输入的最大序列长度也将对模型时间的分类效果起到一定的影响作用。因此,在要针对文本序列的长度进行调整,以便CNNSVM优化模型能够更好的进行文本分类。当文本数据作为输入进入卷积神经网络模型进行训练时,需要先将本长度与预先设置的最大长度进行比较。但由于机器学习的文本分类算法较为强调文本中特征词语的选取,且属于浅层学习方法,不能有效地继续深层挖掘分类信息。基于神经网络的深度学习算法应运而生。
4.2重要参数设置
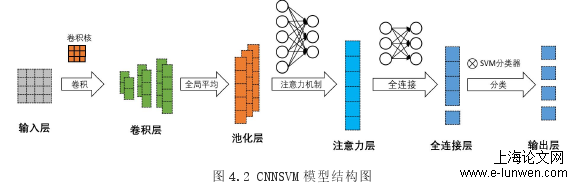
若文本长度大于预先设置的阈值,按阈值将文本分割成若干个文本,文本长度小于阈值时,需要使用空格字符进行填充。通过实验进行分析,确定最佳的阈值长度。具体实验结果如图4.14所示:第三章中,在传统TF-IDF算法的基础上提出了基于权重预处理的PRE-TF-IDF算法,分类精确度最高可达86.9%。其中,基于深度学习的CNN(ConvolutionalNeuralNetworks,卷积神经网络)模型,作为机器学习的一个重要分支,在文本分类领域的应用,取得了不错的效果。将CNN模型应用于文本分类,只需要将完成预处理的文本集导入输入层,通过模型训练,将自动生成特征词语,大大简化了特征词语的选取。本文提出一种将CNN与SVM分类算法进行结合的改进模型,CNNSVM模型。该模型主要的创新点有两处:一方面,使用SVM(SupportVectorMachine,支持向量机)替换传统CNN中的t归一化函数实现模型的分类功能,以便解决原模型泛化能力不足的问题。另一方面,相比于传统CNN模型,CNNSVM模型增加了注意力机制,该机制的作用是对特征词语进行精炼,选取类别代表性更强的特征词语,以提升模型分类的准确度。
........
第五章总结与展望
随着自然语言处理技术的不断发展,相关的电子产品与应用也逐渐融入人们的日常生活中,给人们带了许多便捷。例如语音助手、翻译软件、自动问答机器人等,都是基于NLP的产物。近年来随着移动设备和互联网的不断普及,使得NLP技术在人们的生活中有了更广泛的应用。分类器中,介绍了KNN、NBC、SVM和基于CNN的分类模型。第二,分析了传统TF-IDF算法在进行特征词语选取以及文本分类时的局限性。除此之外,还增加了词密度权重处理环节,使用类别内词密度和类别外词密度两个指标对特征词语的权重进行更有效的赋值。通过对照实验,对PRE-TF-IDF算法的性能进行了评估。第三,将传统CNN模型与SVM分类器进行结合,提出一种新的文本分类模型,CNNSVM模型。该模型使用SVM分类器替代传统CNN模型中的t归一化指数函数,以达到提高模型泛化能力的目的。除此之外,在传统CNN模型的基础上,增加了注意力机制。通过注意力层为特征词语重新计算权重值,较少意义较小的特征词语数量,提升模型的运行效率。通过对照实验,对CNNSVM模型的性能进行了评估。
参考文献(略)
参考文献(略)

