本文是工程论文,本文主要对交通路标检测识别算法进行了学习和研究,结合机器视觉和深度学习的相关知识,对现有的交通路标检测识别方法进行了总结。阐述了相关神经网络的网络结构以及它们之间的联系与优缺点。对于小目标检测,提出了对SSD改进的Dalation_DenseNet_SSD模型,提高了小目标的检测精度,避免了小目标的漏检情况;对于分类置信度和位置置信度之间的弱相关性和NMS机制的不足,提出了改进的KL_Softer-NMS_DD_SSD模型,提高了目标位置的精准定位和分类置信度;对于交通路标识别中效率低和参数量大的问题,提出了改进的SqueezeNet-IR-GRU模型,提高了识别的准确率和模型的而稳定性,减少了网络参数量。总体而言,本文工作主要有以下个方面。(1)通过DenseNet中的Denseblock模块减少了网络的参数量,减小了网络的运行时间。②加入空洞卷积,在原始卷积核的基础上增大了感知域,从而得到更多的图像特征信息,减少了池化操作造成局部细节信息的丢失,提高了小目标的检测性能。
.......
第一章绪论
本文总共有六章,具体内容安排如下:第一章:绪论。本章主要介绍交通路标检测识别的背景和意义,概述和总结国内外对于交通路标检测识别的研究现状,其次介绍交通路标检测识别的难点问题,最后介绍本文的研究内容和章节安排。第二章:基础理论与技术。本章主要介绍卷积神经网络的概述以及基本结构,其次介绍了空洞卷积和深度可分离卷积,最后介绍了SSD模型,为后三章内容做准备。第三章:提出了改进的Dalation_DenseNet_SSD模型。本章首先介绍了本文使用的数据集和格式分析了SSD模型的不足,其次详细介绍了Dalation_DenseNet的原理和优势,提出将与SSD结合的改进Dalation_DenseNet_SSD模型。最后对改进的模型进行实验对比分析,改进的模型在对小目标的检测性能上有所提高。第四章:基于KL_Softer-NMS改进的Dalation_DenseNet_SSD模型。本章首先分析了NMS机制对先验框剔除和定位的不足;研究了一种基于KL散度改进的损失函数以及Softer-NMS对先验框的选择。最后通过对改进的模型进行实验对比分析,改进的模型在对目标的定位和准确率上都有所提高。第五章:交通路标识别算法研究。本章首先分析现有交通路标识别算法在模型复杂度上和实时性之间的不足,提出了一种基于SqueezeNet小型改进的SqueezeNet-IR-GRU网络对于交通路标的识别。最后通过对改进的模型进行实验对比分析,改进的模型在识别准确率、收敛性和稳定性上都有所提高。第六章:总结和展望。本章主要对本文的研究内容进行总结,并针对本文提出的交通路标识别算法的不足之处指出下一步的研究方向。
.......
第二章基础理论与技术
2.1CNN概述
局部感知域也称稀疏连接。人们对于事物的认知都是通过局部到全部的一个过程,对于图像的识别也是根据这一特征,即图像的某一特征在局部区域是相对比较密集的,而对于局部区域相对较远的区域相关性就比较弱。因此,每个神经元不必与图像的所有像素点进行连接,只需要对局部区域进行连接,最后将所有神经元的信息拼接起来就可获得图像的所有信息。神经元全连接和神经元局部连接图如图2-1(a)和图2-1(b)所示。由于卷积核权值共享机制,假如只有一个卷积核,则只能获得的一种特征。为了获得图像的所有特征信息,将增加多个卷积核对图像进行卷积操作,将不同卷积核获得的特征图进行拼接,从而得到图像的所有特征信息。输出特征图的个数与卷积核的数量相同。
2.2CNN结构
池化操作[27]的本质就是一个下采样,通常都是在卷积之后进行操作,如果不进行池化操作,每个卷积后会输出高维度的特征向量,同时卷积后的特征图也没有多大的改变,如此经过多个卷积操作之后,会产生很大的参数量,从而增加了网络的训练难度,并且很容易出现过拟合现象。为了减少计算的参数量和防止过拟合的出现,通过池化层进行降低维度,减少参数量。池化是防止过拟合的一种方法(也可以增加Dropout层,引入BatchNormal层等)。常用的池化操作有最大池化(max-pooling)和平均池化(mean-pooling)操作。在卷积神经网络中,激活函数(ActivationFunction)[28]可以增加神将网络非线性建模的能力。因为在神经网络中,卷积层是对输入的图像进行线性计算的,但输入的图像信息不一定全都是线性可分的,通过增加激活函数来进行非线性操作。因此,选择合适的激活函数不仅可以增加网络的性能,而且还可以去除多余的信息,避免出现过拟合的现象。
..........
第三章基于Dalation_DenseNet改进的SSD模型··············································23
3.1引言·······························································································23
3.2基准数据集·····················································································23
3.3Dalation_DenseNet_SSD模型································································25
第四章基于KL_Softer-NMS改进的Dalation_DenseNet_SSD模型························36
4.1引言·······························································································36
4.1引言·······························································································36
4.2KL_Softer-NMS_DD_SSD模型·····························································36
4.3实验结果与分析···············································································41
4.4本章小结························································································44
第五章交通路标识别算法研究·······································································45
5.1引言·······························································································45
5.2SqueezeNet-IR-GRU网络模型······························································45
5.5.3实验结果与分析···············································································49
........
第五章交通路标识别算法研究
5.1引言
前几章通过改进SSD模型实现了对交通路标的检测,本章将对交通路标的识别算法进行深入研究。现常用的交通路标识别方法都是基于卷积神经网络,随着模型网络层数的增加,准确率会随之提高,但也出现了效率降低、参数量增加等问题。为此,本章提出了结合深度残差网络和GRU网络的改进SqueezeNet模型(SqueezeNet-IR-GRU)。通过实验验证SqueezeNet-IR-GRU模型,不仅大幅度降低了参数量,其收敛性、稳定性和召回率等也都优于其他网络模型。本章提出的SqueezeNet-IR-GRU模型,具体研究如下。(1)采用轻量级SqueezeNet作为基础模型进行改进,SqueezeNet模型相对来说网络结构简单,参数量少。(2)将激活函数ReLU用ELU函数代替,避免网络梯度消失,提高学习效率。(3)将原始的残差网络进行改进,能够很大程度减少参数量,缩减训练时间。(4)结合GRU(GatedRecurrentUnit)神经网络能够记忆过去有用的信息,保证模型的稳定性。
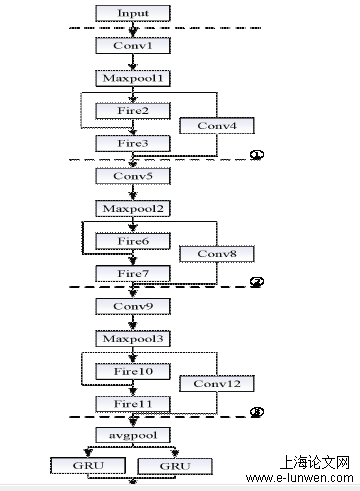
5.2SqueezeNet-IR-GRU网络模型
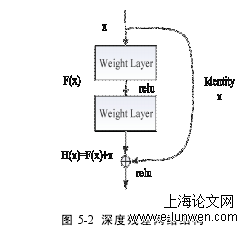
深度残差网络(ResNet)是由HeKaiming等人在2015年提出的。随后,深度残差网络在图像识别领域表现出惊人的效果。在深度学习中,随着网络层数的增加,训练结果有时并不会随之变得更好,反而可能会使梯度消失的现象越明显,要解决这个问题就要在网络模型上添加一个恒等映射x,使得网络随深度增加而不退化。即可得到函数H(x)=F(x)+x,但H(x)优化是比较困难的,所以将其转化为学习残差函数F(x)=H(x)-x。只要F(x)=0,就能得到恒等映射H(x)=x。本文正是将这一思想引入到SqueezeNet模型中。x网络是输入,H(x)是期望输出,F(x)是残差映射函数。图5-2为残差网络结构。输入图像经过图5-5①中的卷积层Conv1,得到96个48×48的特征图,再经过最大池化层Maxpool1,输出为96个24×24的特征图,将Maxpool1得到的输出与Fire2得到的输出相加,将相加后的输出经过Fire3再与Maxpool1的输出经过Conv4进行相加,最终得到96个24×24的特征图。图2中的②、③与①处理过程相同,为了获得更多的有效特征,将得到的特征图依次经过256、384个数量的卷积核,最后输出为384个6×6的特征图。将③输出经过平均池化avgpool,取其区域的平均值作为输出,得到384个3×3的特征图。
........
第六章总结与展望
③为了对不同大小的目标进行检测同时获得上下层更多的语义信息,采用反卷积对特征融合进行输出预测。④通过在CTSD数据集上进行验证,实验结果表明改进后的模型相比于Dalation_VGG_SSD和SSD512模型在mAP上增加了3.9%和6.4%,损失分别下降了0.5和1.8。同时获得了92.6%的召回率和94.4%的精准率,体现了改进模型的可行性。(2)在目标检测时,由于得到的预测框不一定都很准确,甚至可能会出现目标以外的一些物体的问题。另外在NMS机制对预测框进行筛选时,只是依据分类置信度进行筛选,而没有考虑位置置信度的问题,就可能造成分类置信度高的定位不一定准确,被丢弃的box可能定位准确。因此,提出了一种改进的KL_Softer-NMS_DD_SSD模型对上述问题进行改善。①通过KL散度改进SSD模型的损失函数,增强分类置信度和预测框与真实框IoU之间的相关性,通过预测框和真实框IoU来确定预测框与真实框之间有多大重合的可能性,从而获得更逼近真实框的预测框。
参考文献(略)
参考文献(略)

