本文是工程论文,本文主要进行的是基于卷积神经网络的音乐推荐系统的研究,研究的主要内容是将深度学习与传统的推荐算法进行结合,充分利用深度神经网络自动提取特征的强大优势,从音频内容中获取更高层的音乐特征表示,同时将用户对音乐交互的历史行为信息抽象成评分数据融入到推荐系统中,有效地缓解了传统推荐系统中存在的冷启动问题。本文主要工作如下:首先,介绍了音乐推荐系统的研究价值与意义,同时对相关研究在国内外的研究现状和发展趋势进行了简要地综述,并对比分析了传统的音乐推荐算法的优缺点。鉴于对之前有关研究的分析和总结,引出了本文的主要研究内容,即利用卷积神经网络实现基于音乐内容及用户历史行为的混合推荐模型。接着,叙述了基于卷积神经网络的音乐推荐算法具体思路,即利用卷积神经网络预测出音乐的隐含特征,获取到音乐特征的低维向量表示,再结合用户偏好的隐表示,最终为目标用户产生合理的TopN推荐。同时,对该推荐算法中涉及到的隐语义模型、矩阵分解、音频特征表示以及卷积神经网络模型架构设计等有关内容进行了详细的阐述。
........
第一章绪论
本文推荐系统包括用户建模模块、音乐特征提取模块和推荐算法模块等,其功能的实现主要包括回归模型训练和预测推荐两个过程。通过对传统的基于矩阵分解模型的协同过滤音乐推荐算法的进一步改进,把用户对音乐交互的历史行为信息抽象成评分数据,并利用深度神经网络从音频内容中获取更高层的音乐特征表示,将用户信息和音频的声学特征共同融入到推荐系统中,有利于提高推荐系统的性能,缓解推荐系统中存在的冷启动问题。本文主要研究的是基于卷积神经网络的音乐推荐问题,其主要目的是将深度学习与传统的推荐算法进行结合,利用隐语义模型矩阵分解技术以及具有强大的特征学习能力的卷积神经网络回归模型,将用户和音乐投影到一个共享的隐空间,通过计算用户偏好与音乐特征之间的相似性,最终为目标用户产生TopN音乐推荐。论文主要研究内容包括:(1)实验数据集构建首先创建在系统实验时所需的用户和音乐数据集,并分别对它们进行相应的数据预处理。(2)用户偏好模型建立通过对用户的历史行为数据进行采集,根据统一的量化标准构建出一个能够反映用户-音乐之间关系的隐语义模型,再利用矩阵分解等方法建立起用户偏好特征模型。(3)音乐的音频特征提取对系统中的音乐资源文件进行预处理,并提取出能够代表音乐音频特征的对数刻度梅尔频谱图,用于后续模型训练。(4)CNN网络模型设计及训练搭建卷积神经网络模型,并对网络模型结构及调优训练相关的参数进行对比选择,通过不断地训练与学习,获得能够预测出音乐潜在因子特征的CNN回归模型。(5)音乐推荐列表生成
.......
第二章音乐推荐技术简介
2.1基于内容的推荐算法
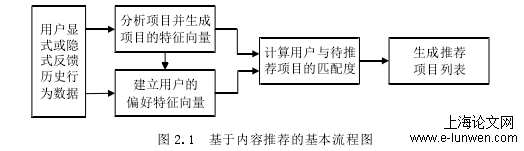
基于内容的推荐方法[18]的核心思想是从物品的元数据中提取代表性的特征,计算物品的相关性,基于用户的偏好给用户推荐相似的物品。具体而言,首先根据用户的历史行为获取与用户交互过的物品,比如用户曾经选择或者评分的物品,接着通过提取这些物品的特征学习计算出用户的偏好,然后计算用户与各个待推荐物品的相似度,最后按照相似度排序给用户进行推荐,从而为用户推荐潜在感兴趣的项目。基于内容推荐的基本流程如图2.1所示。
2.2基于协同过滤的推荐算法
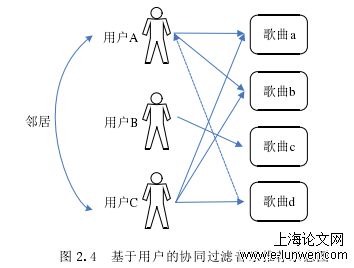
基于用户的协同过滤推荐方法主要是利用相似用户之间具有相似兴趣偏好的方法,来预测用户对项目的潜在偏好,主要体现了“人以群分”的思想。根据不同用户对相同物品的偏好程度计算用户之间的相似性,按用户偏好将用户划分为多个用户集,每个用户集中的用户有着相似的兴趣偏好,对于目标用户找到其最相似的邻近用户集,并将该邻近集中其他用户喜好的物品推荐给该目标用户。一个基于用户的协同过滤音乐推荐简单例子如图2.4所示。假设用户A喜欢歌曲a和歌曲b,用户B喜欢歌曲c,用户C喜欢歌曲a、歌曲b和歌曲d。从上面的喜好行为中可以发现用户A和用户C喜好口味比较类似,则用户A和用户C划分为同一邻近用户集,用户C和用户A相互为邻居用户。那么,用户C喜欢的歌曲对用户A来说也可能是被偏爱,于是可以将歌曲d推荐给用户A。
.......
第三章基于卷积神经网络的音乐推荐算法..................23
3.1系统总体设计.....................................................23
3.2隐语义模型.........................................................25
3.3推荐系统中的矩阵分解模型.............................26
第四章系统实验与结果分析..........................................48
4.1数据集准备.........................................................48
4.2训练与测试过程.................................................53
4.3实验结果与分析.................................................55
第五章总结与展望..........................................................62
.......
第四章系统实验与结果分析
4.1数据集准备
在深度学习视觉领域中,国内外有关企业和组织针对不同的应用场景先后开放了许多优秀的基准数据集,如MNIST、COCO、CIFAR、ImageNet以及OpenImage等都是研究人员较为常用的数据集。这些公开数据集对促进相关领域的研究和发展起着至关重要的作用。然而,与有着大量公开可用的图像或文本不同的是,音乐信息检索或推荐领域一直缺乏大型成熟、完整且易用的基准数据集。这一定程度上限制了通常需要大量数据训练的深度神经网络等模型在该领域的研究与应用。表4.1列出了目前较为常用的一些公开的音乐数据集。从上表中可以看出,或许是因为音频文件受到了唱片公司严格的版权控制,只有部分较小的数据集才会分发音频文件,对于较大型的数据集,如MillionSongDataset(MSD)[55]、AudioSet和AcousticBrainz等都没有直接提供音频文件,仅仅包含了音频的特征或者提供了音频的下载链接。由于无法自行调整特征提取的参数,所提供的音频特征往往用途十分有限,不太适合于深度学习系统学习;对于提供链接需要研究者自己下载的情况,也无法保证在线文件或服务不被更改。而对于像MagnaTagAtune一类的数据集,虽然包含了音频文件,但是通常也只是几秒的音频片段并且有时音频质量较差。MSD是一个拥有一百万当代歌曲的元数据和预处理的音频特征的集合,拥有EchoNestTasteProfile、Last.fm等多个子集,其中EchoNestTasteProfile从100万用户收集了MSD中的380000多首歌曲的用户播放次数等数据。但遗憾的是,其也仅提供音频特征,而不提供音乐音频。
4.2训练与测试过程
在训练有监督的深度学习模型时,通常会将原始的数据集分成训练集、验证集和测试集等三个部分。顾名思义,训练集就是用来训练模型所用的数据集合,利用其来确定网络模型的参数;而测试集就是在模型训练完以后用来对模型进行测试的数据集合,利用其来检验网络模型的泛化能力。在模型训练过程中,可以使用验证集来观察模型的拟合情况,当模型出现过度拟合时,及时停止训练。同时,还可以通过验证集来确定一些超参数,辅助模型优化,比如根据验证集上的收敛情况来确定训练所需的学习速率。之所以不在训练数据集上完成上述操作的原因是,随着网络模型被不断训练,很有可能造成模型对训练集上数据过度拟合,如果最后仍将训练集上的数据用于检验和测试模型的准确性就失去了意义。
.........
第五章总结与展望
为了验证本文所研究的推荐算法的可行性和有效性,利用自行构造的数据集进行了系统实验,并从多个角度对实验结果进行了较为的全面分析.实验所采用的CNN网络模型是在LeNet5AlexNet等许多优秀的模型基础上,并充分考虑到音频特征谱图的特殊性,在不断尝试和参数调优中改进而来。实验结果表明,本文的推荐算法具有较好的预测推荐能力,尤其是在冷启动环境下,推荐的质量普遍优于Frunk-SVD、User-CF以及CB等传统的推荐算法模型。如前所述,上述结果归因于本文的推荐算法同时结合了用户的偏好特征以及音乐的音频内容本身,更为重要的是卷积神经网络强大的特征学习能力。较为遗憾的是,本文仅采用单一的数据集对模型进行训练和测试,没有对数据稀疏性对推荐结果影响进行定量的分析。同时,本文只是对卷积神经网络用于音乐推荐系统的进一步探索,若在推荐算法融入更多的用户和音乐属性,加以对模型进一步改进,将有望能够较大幅度地提高推荐系统的质量。
参考文献(略)
参考文献(略)

