本文是一篇工程论文,工程硕士专业学位在招收对象、培养方式和知识结构与能力等方面,与工学硕士学位有不同的特点。工程硕士专业学位侧重于工程应用,主要是为工矿企业和工程建设部门,特别是国有大中型企业培养应用型、复合型高层次工程技术和工程管理人才。(以上内容来自百度百科)今天为大家推荐一篇工程论文,供大家参考。
第 1 章 绪论
1.1 研究背景与意义
在现实世界中,大部分的实体总是彼此互连,并且以实体为中心的应用在不断的增加,研究实体之间的相互关系变得越来越重要。这些实体之间的关联关系可以抽象成高结构化的图数据结构,图的节点表示实体,相互关系则用边来表示。在现实问题研究中,往往可以把研究对象抽象成图,研究者们利用图论的相关知识,通过分析图的结构化特征,从而提取图中隐藏信息来解决实际问题。因此,图算法的研究具有巨大潜在商业和研究价值。许多领域逐渐使用大量的关于图的处理算法进行分析,例如生物技术、工程技术、自然科学、社会科学以及经济、科技、军事等领域。近些年,越来越多的研究集中在图的子图匹配。所谓子图匹配,就是给定一个查询图,从大的数据图中找到与查询图的结构相同的所有匹配子图。在对图进行子图匹配的实际应用过程中,一般来讲,首先要将具体应用转化为能够表示实际问题的合适的图结构,然后针对实际问题,使用不同语义情况下定义的子图匹配算法来处理图中的节点、边或拓扑结构,从而得到期望的所有匹配结果,但在实际应用中,用户往往只关心自己感兴趣的一些匹配结果。因此,引入 Top-K 兴趣子图的匹配问题,根据用户提供的特定兴趣子图,在大规模的数据图中查找 K 个兴趣度最大的匹配子图,Top-K 兴趣子图的匹配问题更具有针对性。众多实际应用都涉及了 Top-K 兴趣子图匹配,例如,查找 K 个最优的具有所给出结构的治疗药品,或者在社交网中查找 K 个兴趣度最好的具有给定关联模式的团体等。由多种类型的实体组成的实体关系网络叫做异构信息网络,可以抽象成特殊的标签图结构,即异构图。在异构图中进行 Top-K 兴趣子图匹配在很多领域被研究应用,例如:文献网络捕捉协会获得“某位作者写了一篇论文”或“某位作者参加了某个会议”、在军事网络中进行团队查询、在计算机网络中发现瓶颈等。由于子图匹配问题的本质是子图同构问题,且子图同构问题本身是一个NP-Complete 问题,因此为 Top-K 兴趣子图的匹配问题带来了巨大的难度和挑战。
.......
1.2 国内外研究现状
国内外关于子图匹配问题的研究已经有很长的时间。早在 1979 年,学者Johnson 和 Garey 就证明了图同构是一个 NP-Complete 问题。但是由于它的广泛应用,依然被国内外学者研究。子图匹配的研究根据结果匹配的程度可以划分成两类:精确匹配和近似匹配。当给定查询图时,返回图中所有与查询图相同的子图称精确的子图匹配,主要应用于严格对应的关系,如生物信息分子结构的分析等;近似匹配即为当给定查询图时,返回图中所有与查询图相同或相似的子图,它主要应用于无需给出严格对应关系的场景,如地图范围挖掘等。目前关于图匹配的文献中,文献[1] ~ [4]、[18] ~ [25]关于近似匹配,文献[5] ~[7]、[26]关于精确匹配。子图匹配针对的数据图主要有 RDF 图[8]、概率图[9]和时序图[10]。经典的子图匹配方法主要有 Ullmann[11]、VF2[12]、GraphQL[13]、Spath[6]、RWM[14]和 Stwing[5]等。Ullmann[11]是一种精确子图匹配方法,它提出了状态空间搜索的子图同构检测方法,而 VF2[12]算法则是对Ullmann[11]算法进行改进,增加了查询节点匹配的顺序,这 2 种算法都没有利用索引结构和优化策略,复杂度都是超线性的,所以只适用于小规模的数据图。已有的大部分算法如 SpiderMine[15]、GraphQL[14],Spath[6]和 RWM[14]等都是通过构建索引结构和一些优化策略对候选集合进行裁剪,基于回溯的方式逐步列举解决方案并验证查询图节点所对应的候选集合,从而递归地形成最终的匹配。其中,SpiderMine[15]是通过建立频繁子图索引进行裁剪,挖掘图数据中的频繁子图或者频繁的查询子模式来加速子图匹配,而挖掘频繁子模式是非常耗时的,并且对于没有频繁子模式的查询图来说,这个索引是无效的。而 GraphQL[13],Spath[6]和 RWM[14]是为每个节点的可达性邻居建立索引结构。Spath[6]和 RAM[16]采用先匹配再排序的模式,先对单一的数据图进行子图同构检测,再按权值和进行排序。RWM[14]则采用边匹配边排序的模式,通过索引结构,逐渐缩小候选集合的大小。
.........
第 2 章 相关工作
本章将介绍 Top-K 子图匹配算法中涉及的相关内容,图的邻接表存储结构,经典的子图匹配算法,并对当前典型的 Top-K 兴趣子图匹配研究方法进行分析和归纳。
2.1 图的邻接表存储
在图结构中,不仅包含各个节点本身的信息,还蕴含着节点之间的关联关系,很难以数据元素在存储区中的物理位置来表示图中各元素间的关系。现有的图存储方法中,常用邻接矩阵、邻接表储存复杂的图数据。本文主要涉及图的邻接表储存。图的邻接表跟树的孩子链表类似,是一种顺序分配和链式分配相结合的结构。邻接表由表头节点和表节点两部分组成,其中图的节点对应于数组中的表头节点,图中每个节点的邻接节点的个数不定,可以用单链表表示,利用链表将与节点所连接的节点全部链接到对应的表头节点上,减少了内存占用。为了存储带权图即标签图,则在表节点中增加一个存放标签的字段。图 2-1 所示为带权标签图的邻接表储存。
.......
2.2 子图匹配方法
目前关于子图匹配的研究,可分为两类:近似匹配和精确匹配。近视匹配是给定查询图,返回图中所有与查询图相同或相似的子图就称为近似的子图匹配。精确匹配即是给定查询图,返回图中所有与查询图机构相同的子图就称为精确子图匹配。本文主要针对精确子图匹配的研究。众多实际应用都涉及精确子图匹配,例如查找具有所给出结构的治疗药品,或者在社交网中查找具有给定关联模式的团体等。经典的精确子图匹配方法主要有 Ullmann[11]、VF2[12]、GraphQL[13]、Spath[6]、RWM[14]和 Stwing[5]等。通过对这些方法进行分析和比较,这些方法多采用过滤-验证的手段进行子图匹配,根据过滤方式分为三类:无索引结构、频繁子图索引和可达性索引过滤。无索引结构的方法:是一种早期的没有利用索引结构过滤而直接进行匹配验证的子图匹配方法,如 Ullmann[11]、VF2[12]。Ullmann[11]是一种基于状态空间搜索的子图同构检测方法。它没有提出相应的过滤策略而是利用查询图的输入节点的顺序依次进行深度优先匹配的简单的验证方法,而 VF2[12]算法则是对Ullmann[11]算法进行优化,增加了查询节点匹配的顺序,这 2 种算法都没有利用索引结构和优化策略,复杂度都是超线性的,所以只适用于小规模的数据图。频繁子图索引方法:是一种通过建立频繁子图索引进行裁剪,挖掘图数据中的频繁子图或者频繁的查询子模式来加速子图匹配的方法,如 SpiderMine[15]。而挖掘频繁子模式是非常耗时的,并且对于没有频繁子模式的查询图来说,这个索引是无效的。可达性索引方法:是一种通过构建索引结构和一些优化策略对候选集合进行裁剪,基于回溯的方式逐步列举解决方案并验证查询图节点所对应的候选集合,从而递归地形成最终的匹配,如 GraphQL[13]、Spath[6]和 RWM[14]等。SPath 和Graph QL 都是利用每一个节点的邻居进行过滤,使得候选节点的数目最小化。其中 Graph QL 利用广度优先搜索树的形式,进一步对候选节点进行过滤,从而迭代地进行探查。SPath 则通过记录一些基本的路径,来对节点进行过滤。这样虽然减少了很多不必要的探查。但是由于在过滤中记录了过多信息,造成了很多不必要的内存开销。同时这两种方法也没有涉及到等价节点重复枚举问题和匹配顺序选择问题。
...........
第 3 章 静态异构图中的 Top-K 兴趣子图匹配 .......11
3.1 相关定义与算法的整体概述 ....11
3.1.1 相关定义 ............ 11
3.1.2 算法的整体概述 ...... 13
3.2 离线索引结构的建立 ..........14
3.3 候选集过滤 ........18
3.4 子图匹配验证算法 .............22
3.5 静态 Top-K 兴趣子图匹配算法 ............27
3.6 本章小结 ..........27
第 4 章 动态异构图中的 Top-K 兴趣子图匹配 .......29
4.1 问题提出与算法的整体概述 ....29
4.1.1 问题提出 ..... 29
4.1.2 算法的整体概述 ............. 30
4.2 动态图局部变化数据处理 ......31#p#分页标题#e#
4.3 索引的动态维护策略与动态编码方法 ......33
4.4 动态子图匹配更新验证算法 ....38
4.5 动态 Top-K 兴趣子图匹配算法 ............41
4.6 本章小结 ..........44
第 5 章 实验与分析.........45
5.1 实验设置 ..........45
5.2 性能评估指标 ......46
5.3 实验结果与分析 ....46
第 5 章 实验与分析
在合成数据集和真实数据集上,同现有的几种子图匹配方法进行对比,比较这几种方法在图与查询图不同节点数、边数的条件下,索引创建时间、存储开销和匹配执行时间几个方面的变化情况,对实验结果进行分析总结,验证本文算法的时间性能和有效性。
5.1 实验设置
本文的实验通过与目前具有代表性的 RAM 和 RWM 算法进行实验对比,来验证本文提出的 Top-K 兴趣子图匹配算法 ERWM 的高效性和可扩展性。模拟数据集 G1、G2、G3和 G4:通过 GT-Graph 软件中图生成器 R-MAT[40]创建 4 个模拟数据集:G1、G2、G3和 G4,其中节点数(|V|)分别为 103、104、105和 106,每个图的边数为其节点的 10 倍。4 个模拟图的大小指数增长,每个节点从 1 到 5 随机分配属性标签性,每条边的权值随机产生[0,1]区间的值。真实数据集 DBLP:可以在 www.informatik.uni-trier.de/~ley/db/上下载,DBLP数据是计算机领域内,以作者发表文献为核心的英文文献集成数据库。利用NetClus[41]聚类方法将 DBLP 数据聚类成由作者、关键字和会议组成的作者协同合作的异构网络。在 DBLP 作者协同和作的网络中,如果作者之间合作发表过文章,则他们之间存在边的连接。数据集中节点总数为 217080,边数为 1022962。
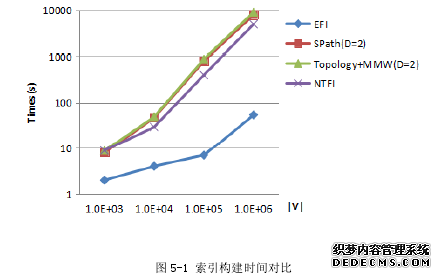
........
总结
本文针对传统异构图中 Top-K 兴趣子图匹配方法的不足,对基于有权查询图的匹配方法进行深入研究,提出一种高效的静态异构图中的 Top-K 兴趣子图匹配方法(ERWM)。针对动态图中节点和边的动态性及复杂性等问题,提出了提出一种有效的动态异构图中的 Top-K 兴趣子图匹配方法(DRWM)。本文具体研究工作内容如下:
(1)提出一种特殊的类邻接表结构存储数据图。根据异构图的节点和边类型不同的特性,通过一种特殊的类邻接表存储结构,不仅能全面存储异构图的节点和边的信息,而且能快速获得各个节点不同类型的邻接节点。
(2)建立两种新异的索引。边特性索引(EFI)和节点拓扑结构特性索引(NTFI)。利用它们能实现对图的高效过滤和查询,充分利用边的索引信息和节点的索引信息,在匹配验证前过滤掉不合格(不匹配)的节点和边,减少不必要的匹配验证,从而提高子图匹配的效率。
(3)提出两种新异的过滤策略。节点过滤策略和边过滤策略。通过两种策略进行节点和边的过滤,最终获得较小的候选集。避免了匹配阶段进行不必要的节点、边连通性检测,从而减少了算法的冗余匹配步骤。
(4)提出查询图边标签设定方法。根据查询图边的信息量公式,确定查询图中每一条边的标签。在子图匹配验证阶段,利用查询图的边标签,确定查询图中全部边的匹配验证顺序,提高匹配验证效率。
(5)提出一种在匹配验证阶段优化 ERWM 算法的动态编码方法 MDC。利用动态编码方法 MDC,记录静态异构图中 Top-K 子图匹配的重要过程。为动态异构图中 Top-K 子图匹配的增量匹配计算提供变化依据。
(6)提出一种动态异构图中 Top-K 子图匹配方法(DRWM)。该方法在静态匹配方法 ERWM 的基础上,利用滑动窗口的思想,实现随异构图节点和边的动态变化的子图匹配结果的动态更新。
..........
参考文献(略)

